|
|
< Day Day Up > |
|
9.1 What Is the Spider?One of the most valuable features of any web site is the ability to search for what you need. Companies with web sites are constantly looking for the right tool to provide those features; they can write their own or purchase something from one of the big vendors. The problem with writing your own is mastering the tools. The problem with purchasing is usually vast expense. Google, the world's leading search provider, sells a boxed solution at $18,000 per unitnot including the yearly license. Customized search engines are often built around the act of querying the database that sits behind a web site. Programmers immediately jump to this solution becausetools and libraries make querying a database simple. However, these customized search solutions often miss entire sections of a web site; no matter how stringently a company tries to build an all-dynamic, data-driven web site, they almost always end up with a few static HTML files mixed in. A data-driven query won't discover those pages. Crawling a web site is usually the answer, but don't attack it naively. Let's look at what crawling means. When you crawl a web site, you start at some initial page. After cataloging the text of the page, you parse it, looking for and following any hyperlinks to other endpoints, where you repeat the process. If you aren't careful, crawling a web site invites the most ancient of programming errors: the infinite loop. Take a look at Figure 9-1. The web site is only four pages, but no simple crawler will survive it. Given Page1 as a starting point, the crawler finds a link to Page2. After indexing Page1, the crawler moves on to Page2. There, it finds links to Page3 and Page4. Page4 is a nice little cul-de-sac on the site, and closes down one avenue of exploration. Page3 is the killer. Not only does it have a reference back to Page1, starting the whole cycle again, but it also has an off-site link (to Amazon.com). Anyone who wants a crawler to navigate this beast has more processor cycles than brain cells. Figure 9-1. A simple, four-page web site that breaks any naïve crawler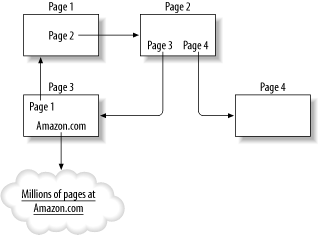 I had a client who couldn't afford the $18,000 expense to buy search capabilities and didn't want to sit down and write something custom that might cost them the same amount in development dollars. They came to me and provided a set of straightforward requirements for an application that would enable them to search on their web site. Here's what they asked me to do:
My solution was to write an open source web site indexing and search engine. The goal was to have an application that could be pointed at any arbitrary web site, crawl it to create the domain of searchable pages, and allow a simple search language for querying the index. The crawler would be configurable to either allow or deny specific kinds of links, based on the link prefix (for example, ONLY follow links starting with http://www.yourdomain.com or NEVER follow links starting with http://www.amazon.com). The indexer would operate on the results of the crawler and the search engine would query the index. Here are the advantages this engine would provide:
|
|
|
< Day Day Up > |
|