| [ Team LiB ] |
|
8.1 Data Access PatternsThe most common J2EE persistence mechanism is a relational database management system, or RDBMS. Therefore, we focus primarily on patterns that apply to relational databases. Java, both in and out of J2EE, is chock full of database technologies. Enterprise JavaBeans were designed with the database backend in mind, and the JDBC API, which is part of the J2SE package but heavily used in J2EE environments, provides a powerful, low-level approach for connecting any Java object to an external database. Other technologies, such as Java Data Objects, provide a higher-level abstraction of the persistent data, handling much of the mapping between database tables and Java objects. Of course, databases are not the only persistence mechanism available. Simpler applications can persist data to files on disk in text or binary formats, or to XML. Java objects themselves can be serialized directly to disk and reloaded later, although this approach makes it difficult for human beings to access and manipulate the data independently from the program that created it. Collectively, these persistence mechanisms are referred to as data sources. Whatever data source we use, there are problems when we embed persistence logic directly into business components. When the business object is responsible for persistence, it means we've given two responsibilities to a single class. Doing so isn't intrinsically evil, but it can be problematic in several ways. First, the full persistence layer has to be implemented before the business object can be fully tested. Second, the business object becomes locked in to a particular persistence scheme. Finally, the business object code becomes more complex and difficult to understand, particularly when there is a separation between the programmers who understand the business logic and those who understand the persistence mechanism. 8.1.1 Data Access Object PatternWe need to separate the business logic and the resource tier. The Data Access Object pattern separates the code that accesses the database from the code that works with the data. Other components of the application delegate responsibility for database access to a DAO object, which communicates with the rest of the system by passing around data transfer objects. A DAO is responsible for reading data from an external data source and providing an object encapsulation for use by business components. Unlike an EJB entity bean, a DAO is not a remote object and should not contain any business methods beyond getters and setters for the data it provides access to. The applications' business process logic should be located elsewhere, where it can be tested independently and reused in the event that the persistence layer changes. DAOs are simply the access path to the persistence layer. If you're not using EJBs, a set of DAOs can be used as the data model for simple applications that don't include much business logic beyond the control tier. Business process logic can be embedded in Business Delegate objects insteadwe'll talk about those in more detail in Chapter 9. Figure 8-1 shows how a DAO object interacts with the rest of the system. A presentation tier object, such as a servlet or a Struts action, uses a business object to retrieve a data object. The business object uses a DAO to access the persistence mechanism, and receives a data object that it can manipulate, pass back to the presentation tier, or both. Figure 8-1. Data Access Object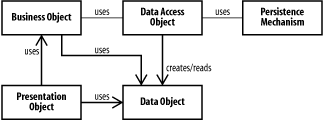 Example 8-1 shows an interface for a DAO object that manages patient data in our simple model. Rather than provide individual fields, it uses the PatientDTO object (described in Chapter 7), which keeps the external interface of the DAO itself as simple as possible. Example 8-1. PatientDAO.javapublic interface PatientDAO {
// Retrieve a patient's record from the database
public PatientDTO findPatient(long pat_no);
// Save a patient DTO back to the database
public void savePatient(PatientDTO patient);
// create a new patient, based on data in the PatientDTO,
// and return a PatientDTO updated with the primary key for the new patient
public PatientDTO createPatient(PatientDTO patient);
}
We might add other methods for other database-related actions, such as determining whether a patient record with a particular ID exists without having to actually load all the data (like the findPatient( ) method does). Example 8-2 shows an implementation of the PatientDAO interface. Some of the code is similar to the ejbLoad( ) method in Example 7-3, although it is simplified, since the PatientDTO uses a different approach to storing address information (an arbitrarily long list of Address objects, rather than fixed home and work addresses). Example 8-2. PatientDatabaseDAO.javaimport java.util.*;
import java.sql.*;
import javax.sql.*;
import javax.naming.*;
public class PatientDatabaseDAO implements PatientDAO {
public PatientDTO findPatient(long pat_no) {
Connection con = null;
PreparedStatement ps = null;
ResultSet rs = null;
PatientDTO patient = null;
try {
con = getConnection( ); // local method for JNDI Lookup
ps = con.prepareStatement("select * from patient where pat_no = ?");
ps.setLong(1, pat_no);
rs = ps.executeQuery( );
if(!rs.next( ))
return null;
patient = new PatientDTO( );
patient.pat_no = pat_no;
patient.fname = rs.getString("fname");
patient.lname= rs.getString("lname");
ps.close( );
rs.close( );
ps = con.prepareStatement(
"select * from patient_address where pat_no = ? and address_label in " +
"('Home', 'Work')");
ps.setLong(1, pat_no);
rs = ps.executeQuery( );
// Load any work or home
while(rs.next( )) {
String addrType = rs.getString("ADDRESS_LABEL");
Address addr = new Address( );
addr.addressType = addrType;
addr.address1 = rs.getString("addr1");
addr.address2 = rs.getString("addr2");
addr.city = rs.getString("city");
addr.province = rs.getString("province");
addr.postcode = rs.getString("postcode");
patient.addresses.add(addr);
}
} catch (SQLException e) {
e.printStackTrace( );
} finally {
try {
if(rs != null) rs.close( );
if(ps != null) ps.close( );
if(con != null) con.close( );
} catch (SQLException e) {}
}
return patient;
}
public void savePatient(PatientDTO patient) {
// Persistence code goes here
}
public PatientDTO createPatient(PatientDTO patient) {
// Creation code goes here
}
private Connection getConnection( ) throws SQLException {
try {
Context jndiContext = new InitialContext( );
DataSource ds = (DataSource)jndiContext.lookup("java:comp/env/jdbc/DataChapterDS");
return ds.getConnection( );
} catch (NamingException ne) {
throw new SQLException (ne.getMessage( ));
}
}
}
Now that we have a DAO object, we can rewrite our ejbFindByPrimaryKey( ) and ejbLoad( ) methods in PatientBean to be much simpler. We can also use this code in presentation tier code when EJBs aren't involved at all. public Long ejbFindByPrimaryKey(Long primaryKey) throws FinderException {
// mildly inefficient; we should have a simpler method for this
PatientDatabaseDAO pdd = new PatientDatabaseDAO( );
if(pdd.findPatient(primaryKey.longValue( )) != null)
return primaryKey;
return null;
}
public void ejbLoad( ) {
Long load_pat_no = (Long)context.getPrimaryKey( );
PatientDatabaseDAO pdd = new PatientDatabaseDAO( );
PatientDTO pat = pdd.findPatient(load_pat_no.longValue( ));
fname = pat.fname;
lname = pat.lname;
Iterator addresses = pat.addresses.iterator( );
// Load any work or home addresses
while(addresses.hasNext( )) {
Address addr = (Address)addresses.next( );
if("Home".equalsIgnoreCase(addr.addressType)) {
homeAddress = addr;
} else if ("Work".equalsIgnoreCase(addr.addressType)) {
workAddress = addr;
}
}
}
8.1.2 DAO Factory PatternDAOs offer applications a degree of independence from persistence implementations, but the application still needs to be able to instantiate the appropriate DAO and (usually) provide it with connection information to whatever data store is being used: server addresses, passwords, and so forth. In applications that use a large number of DAOs, inheritance provides a simple solution for shared functionality: an abstract parent DAO class can implement methods for retrieving database connections and other resources, and each DAO implementation can extend the parent class and use the common functionality. But things get more complicated when one application needs to support multiple different databases (which may require very different DAO implementations). The DAO Factory pattern allows us to abstract the process of finding an appropriate persistence mechanism away from the business/presentation components. Applications interact with a single class, which produces particular DAOs on demand. Each DAO implements a specific interface, making it trivial to switch persistence mechanisms without affecting the application as a whole. Figure 8-2 shows why we implemented PatientDAO in the previous section as an interface and an implementing class, rather than just writing the database code directly into PatientDAO. We can write a series of DAOs implementing the interface, one for each unique persistence approach. We can then write a DAO factory object that knows how to instantiate each of these according to whatever criteria are appropriate. Alternately, we can go one step further and offload the creation of particular DAO types to type-specific factories. The core DAO factory, which is used by the business or presentation components, is then responsible only for selecting the appropriate factory. Figure 8-2. DAO factory with two DAO types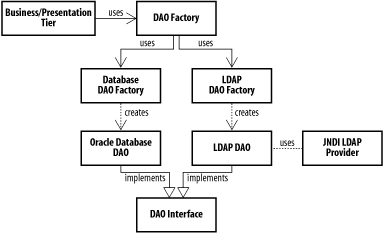 Example 8-3 shows a simple DAO factory that creates specific DAO objects. We dispense with the layer of intermediate factories, since we've embedded the logic for locating data sources directly within our DAO objects. At some point, we must decide what form of persistence mechanism is required. In this case, we specify the persistence strategy as a system property. An alternative would be to develop a naming convention for the JNDI directory itself and have the DAO factory check for known data source types until it finds the one it needs. For example, the factory could attempt to retrieve a data source named "jdbc/oracle", and if it didn't find one could check for "jdbc/db2", and so on. Example 8-3. PatientDAOFactory.javapublic class PatientDAOFactory {
private static final int DAO_ORACLE = 1;
private static final int DAO_DB2 = 2;
private static final int DAO_SYBASE = 3;
private static final int DAO_LDAP = 4;
private static final int DAO_NONE = -1;
private int mode = DAO_NONE;
public PatientDAOFactory( ) {
String dataSource = System.getProperty("app.datasource");
if ("oracle".equalsIgnoreCase(dataSource))
mode = DAO_ORACLE;
else if ("db2".equalsIgnoreCase(dataSource))
mode = DAO_DB2;
else if ("sybase".equalsIgnoreCase(dataSource))
mode = DAO_SYBASE;
else if ("ldap".equalsIgnoreCase(dataSource))
mode = DAO_LDAP;
}
public PatientDAO getPatientDAO( ) {
switch(mode) {
case DAO_ORACLE:
return new PatientDatabaseDAO( ); // Generic, works with Oracle
case DAO_DB2:
return new PatientDatabaseDAO( ); // also works with DB2
case DAO_SYBASE:
return new PatientSybaseDAO( ); // But Sybase needs special treatment
case DAO_LDAP:
return new PatientLDAPDAO( ); // Or we can just hit the directory
default:
throw new DAOCreationException("No Data Access Mechanism Configured");
}
}
}
The getPatientDAO( ) method throws a DAOCreationException if no DAO type is configured at the application level. We've defined this as a runtime exception rather than a regular exception, since configuration issues of this kind will generally only occur when an application is first being configured, and we don't want to force explicit exception-handling every time the factory gives out a DAO. Different applications will handle error conditions differently. You may have noticed we didn't do much to configure the DAO objects themselves. This is because most DAOs, whether used in a J2EE container or elsewhere, can manage their data sources via JNDI. This ability abstracts most of the configuration away from the application itself: database server addresses, login credentials, and so forth are all specified at the application server level. 8.1.3 Lazy LoadAccessing a DAO generally involves accessing data that lives outside the Java runtime environment, and calls outside the native Java environment are expensive. At the bare minimum, the system has to switch application contexts, and there are usually network connections and disk accesses involved. DAOs and DTOs partially address this problem, since they help assure that information isn't loaded too frequently. But loading a DAO for a complex data structure can still be an expensive operation. The Lazy Load pattern speeds up DAOs and other persistence-dependent objects by postponing data retrieval until the data is specifically requested. When using lazy loads, individual methods like the findPatient( ) method of our PatientDAO will only retrieve the data required for immediate use. Objects implementing this pattern should break up the available data into as many discrete, logical pieces as possible. Figure 8-3 shows the sequence in which an application might implement the Lazy Load pattern. Our DAO example in the previous section gathers all of the data it provides in a single activity, even though it involves querying multiple tables. If the application only needs patient names and not addresses, resources will be wasted as the DAO retrieves information that is destined to be ignored. Figure 8-3. Lazy load sequence diagram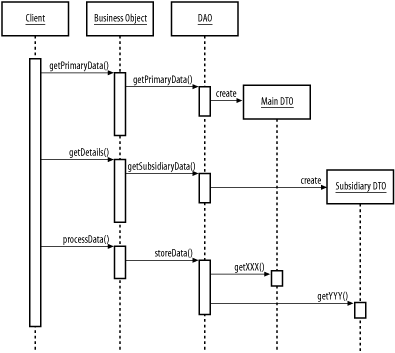 Using the Lazy Load pattern does not mean throwing out everything we said in Chapter 7 about the benefits of grouping information into objects for transfer between parts of the system! It just means that it's possible to go overboard: a mammoth object that retrieves every possible piece of data about a particular entity is going to waste time. An application retrieving customer information almost always wants a name and address, but it rarely needs detailed information on every order placed over the last 10 years. Finding the right balance depends on the design of your application. As a general rule of thumb, prefetching data that doesn't have a lot of extra cost (for example, additional columns in a table you're querying anyway) can be helpful, while queries to additional tables can be postponed. The Lazy Load pattern can also be applied when building objects that access the database on behalf of the presentation tier. A frequent strategy for building quick and easy data models is to write a JavaBean that acts as a frontend for the database. This bean can then be passed to a JSP page or to a templating system like Jakarta's Velocity. The Lazy Load pattern can be helpful in this situation, since it allows development of a single component that can be used on a number of different pages, while only loading the data that each page needs. 8.1.4 The IsDirty PatternReading and writing from the database are both expensive operations. Efficient data-handling code is particularly necessary in EJB environments, where you don't have control over when a bean's state is and isn't being written to the database. But all database access is expensive: you can count on adding 50 to a 100 milliseconds to any procedure just to cover overhead for each SQL statement that is executed. And that's exclusive of any additional time taken to execute the statement.[1]
Composite Entity Beans, DTOs, and DAOs provide opportunities to decrease reads from the database. The IsDirty pattern is used to decrease writes to the database. It's really the inverse of Lazy Load: only data that has changed in the bean is written back. Data that has been read directly from the database and not modified is considered clean; data that has been altered is considered "dirty." This pattern can speed up composite entity beans dramatically. A well-written EJB container won't persist unless there's been some call to a business method on an entity bean, but once a BMP bean has been changed (at all), the container has no choice but to call the ejbStore( ) method. If the change affects one table and the total scope of the bean covers five, writing to just the changed table provides a dramatic efficiency gain. Performance gains in non-EJB database components can be even more noticeable. Using the IsDirty pattern, your application might not know whether an object was modified and will therefore have to call its persistence methods at points where no data has actually changed. Implementing IsDirty puts the responsibility for persisting on the data object rather than the application. In an EJB, we implement the IsDirty pattern in the setter methods of an entity bean, and in the ejbStore( ) method. In the Patient bean, we could implement the pattern by changing the setHomeAddress( ) method like this: public void setHomeAddress(Address addr) {
if(!homeAddress.equals(addr)) {
homeAddrChanged = true; // mark changed
homeAddress.address1 = addr.address1;
homeAddress.address2 = addr.address2;
homeAddress.city = addr.city;
homeAddress.province = addr.province;
homeAddress.postcode = addr.postcode;
}
}
We now do a check to see if the data has changed; if so, we record the fact via a homeAddrChanged boolean in the bean class itself. This value is called a hint. We can use this variable in the ejbStore( ) method to determine whether we need to write the patient's home address back to the PATIENT_ADDRESS table. Since a DAO object doesn't maintain the state of the data it reads, the IsDirty pattern can't be implemented in a DAO directly. However, if the DAO objects were written according to the general guidelines we discussed earlier, you should have enough granularity to use this pattern effectively. Finally, there are situations in which you want to make absolutely sure that the data in the database matches the data in memory. This is generally the case if there's a possibility that the data in the RDBMS changed due to an external process after the Java object was created. When dealing with POJO data objects, you can implement a forcePersistence( ) method (or add a force parameter to the persistence method) that ignores dirty write hints. 8.1.5 Procedure Access ObjectPrevious generations of enterprise development tools have left millions of lines of legacy code lying around the average large company. Much of this code implements complex business processes and has already been tested, debugged, and adopted. In two-tier "thick client" applications, the business logic is often stored in the database itself in the form of stored procedures. Stored procedures are often used to provide external integration interfaces for applications based on a database platform. Rather than providing external applications with direct access to the underlying tables, a system will provide a set of stored procedures that can be called by other systems at the database level. This set of procedures allows the main application to ensure that all contact with its database takes place through an approved path, complete with error-checking. It also, of course, provides external applications with a defined interface, allowing the developers to change the underlying table structures without having to perform all of the integration activities again. Whatever the source, we can leverage those legacy stored procedures in a new J2EE system using the Procedure Access Object pattern. A PAO is simply a Java object that sits in between the business tier and the database; however, instead of accessing tables directly, it accesses stored procedures. The PAO is responsible for mapping the stored procedure to a Java object that can be used transparently by the rest of an application. Essentially, a PAO is a cross between a DAO and the command object defined by the GoF (Chapter 3 gives a brief introduction). Figure 8-4 shows the structure of a sample PAO that handles new customer registration for an e-commerce system. The PAO accesses a stored procedure that creates a new customer record (accepting arguments via the IN parameters) and provides a new CustomerID (the OUT parameter). The PAO also does a little translation, combining the address and city/state/Zip properties into a single address field for use by the stored procedure (thus hiding a limitation of the legacy business logic from the main application). Figure 8-4. Customer management PAO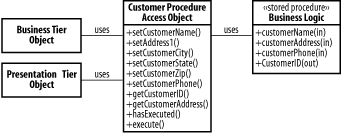 Using stored procedures in a J2EE application comes at a cost. Stored procedure programming languages are usually database-vendor-specific; Oracle's PL/SQL is the most prevalent. Although many vendors, including Oracle, are moving towards using Java as an internal stored procedure language, the mechanics of implementation still vary from vendor to vendor, and performance is usually somewhat less than the "native" language offers. Using stored procedures immediately locks your application to a single backend database (although a PAO abstraction can make it easier to develop stored procedure support for multiple databases in parallel). Moving business logic out of the Java layer can complicate development, since you're now effectively maintaining two separate code trees for a single application: database code for database-centric business logic, and Java code for everything else. This complicates deployment, too, particularly when stored procedures and Java objects that depend on them must be kept synchronized: you can't just stuff everything into a JAR file anymore. In exchange for the complexity, you get to reuse existing components, and can often extract a substantial performance benefit as well. Stored procedures can perform multiple SQL statements in sequence, and support the same data handling and flow of execution control as any procedural language. Since stored procedures execute in a database, they have a real performance edge in activities that execute multiple insert or update statements, or that process a large number of rows and perform some database operation on each one. For example, a stored procedure that performs an expensive join across several tables, iterates through the results, and uses the information to update other tables will run much faster than a Java component that has to retrieve all of the information through the network, process it within the JVM, and then ship it back to the database (if more than one table is updated, the data may end up making several round trips). Stored procedures also improve efficiency when dealing with data spread across multiple databases. Databases like Oracle support direct links between remote databases, which can be much faster than a JDBC link. When a performance-sensitive activity involves multiple databases, creating a link natively and handling the logic via a stored procedure will almost always provide a dramatic performance boost.[2]
Encapsulating your stored procedures in a procedure access object provides the same set of benefits that the DAO pattern does. You don't get portability, but you at least get plugability: you can swap PAOs the same way you swap DAOs, and easily replace them with complete Java implementations when appropriate.
|
| [ Team LiB ] |
|
