| [ Team LiB ] |
|
2.3 NormalizationWhen beginning the development of a data architecture for a project, you first want to capture all the entities in your problem domain and the attributes associated with those entities. Depending on your software engineering processes, these entities may be driven by your object model or your object model may be driven by the logical ERD. Either way, you should not initially concern yourself in any way with issues like performance, scalability, or flexibilitythe task is to model the problem domain properly. Unlike other areas of software architecture, relational data architecture provides a very formal process for optimizing your model for efficient resource usage, scalability, and flexibility. This formal process is known as normalization. Normalization seeks to achieve the following goals:
As I noted earlier, normalization is a formal process. It defines very specific criteria for your data model that it breaks out into normal forms. The normal forms establish a stringent and objective set of rules to which a data model must adhere. Each one builds on requirements of the previous, as is shown in Figure 2-4, and improves upon the overall design of the model. Figure 2-4. The six normal forms build on top of one another Before a data model can be said to be in a certain normal form, it must meet all of the requirements of that normal form and any lesser normal forms. The second normal form, for example, necessitates that a data model meet the requirements for both the first and second normal forms. No matter what your problem domain, you will want to normalize your data model at least to the third normal form. For most simple problem domains, the third normal form is good enough. Deeper normal forms represent specific data modeling issues that do not apply to most data models. Most data models in the third normal form are therefore already in the fifth normal form. If you have a very complex system, you should go ahead and verify that it is in at least the fourth normal form. Formally normalizing your data model to the fifth normal form should be left for very specific problem domains. I will dive into the details of each of these normal forms later in the chapter.
In addition to the six normal forms noted here, a seventh normal form called the domain/key normal form (DKNF) exists. The rule for DKNF is that every logical restriction on attribute values results from the definition of keys and domains. In theory, a table in DKNF cannot contain anomalies. If nothing about DKNF makes any sense to you, don't worry about itno process exists to prove a table is in DKNF and therefore it is not used in real world modeling. 2.3.1 Before NormalizationBefore you begin the process of normalization, you should already have a logical ERD describing your problem domain. This logical ERD should describe all of the entities that make up the problem domain, their major attributes, and their relationships. For the purposes of this section, I will be referring to a data model to support a web site for film fans. It specifically stores information about films and enables people to browse the films in the database based on that information. Figure 2-5 shows the data model before normalization. Figure 2-5. The raw film site data model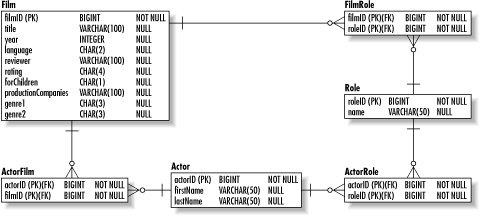 Because we want this web site to be accessible to all North American visitors, it has translations into Spanish and French. These translations are supported through a duplication of the logical data model into three separate physical databases. 2.3.2 Basic NormalizationBasic normalization addresses the design demands common to any relational database. As a data architect, you will always want to carry your design through to the third normal form. 2.3.2.1 First normal formA table is in the first normal form (1NF) when all attributes are single-valued. This requirement is not simply a good design requirement; it is a fundamental requirement of the relational model. At its simplest, it means that only a single value may exist at the intersection of a column and a row. The film database has three different violations of 1NF:
The problem with the first violation is that it makes the database very inflexible. For one thing, searching for films by a specific production company is difficult. You cannot use a simple equality check like: SELECT filmID, title FROM Film WHERE productionCompanies = 'Imaginary Productions'; That column, after all, contains a comma-separated list of companies. Instead, you need a much less efficient query like: SELECT filmID, title FROM Film WHERE productionCompanies LIKE '%Imaginary Productions%'; The solution to the problem of multivalued attributes is to create a new entity to support that attribute. In the case of the film database, we should create a ProductionCompany table with foreign key references to the primary key in the Film table. We now have a one-to-many relationship between films and their production companies. Another, less obvious multivalue attribute is the genre support for films. Because of a need to support the classification of films like Blazing Saddles that fall into two genres, we have in our data model two genre columns. This approach has several problems associated with it. The problems are:
The solution, again, is the creation of a new entity to support the multiple values. In this case, we will create a lookup table for genres and a many-to-many relationship between Film and Genre. The final problem with the raw data model is the fact that the entire database is duplicated for every language we want to support. In order to add a new language, we need to create a new duplicate of that database and replace its text values with translations for the target language. The application then needs to be configured to use that database as a data source for the new language. For this problem, we need to create translation entities for each of the text attributes in the database. Adding support for a new language means nothing more than adding new rows to each translation table. Figure 2-6 contains the film database in 1NF. Figure 2-6. The film database in 1NF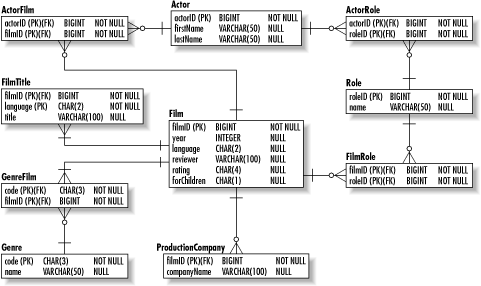 2.3.2.2 Second normal formA table is in the second normal form (2NF) when it is in 1NF and all non-key attributes are functionally dependent on the table's entire primary key. Functional dependency means that an attribute is determined by another attribute. In the case of filmID and title, the title is functionally dependent on the filmID because which film the row represents determines what its title is. On the other hand, the title of the film does not necessarily indicate which film you are dealing with. When an attribute is not dependent on the entire primary key of the table it is in, it has likely been placed in the wrong table. Our data model has this problem in the reviewer attribute of the Film entity. The purpose of this attribute is to capture the name of the person who initially reviewed the film for the site. The reviewer attribute, however, does not depend on the filmIDthe reviewer exists independent of the film. The existence of attributes that violate 2NF causes database anomalies. A database anomaly is an error or inconsistency that occurs when some event takes place. Specifically, there are:
Again, the solution to this normalization problem is the creation of a new entity to remove the nondependent attribute. This entity, Reviewer, contains the name of the reviewer and is related to many films. Figure 2-7 shows our data model in 2NF. Figure 2-7. The film database in 2NF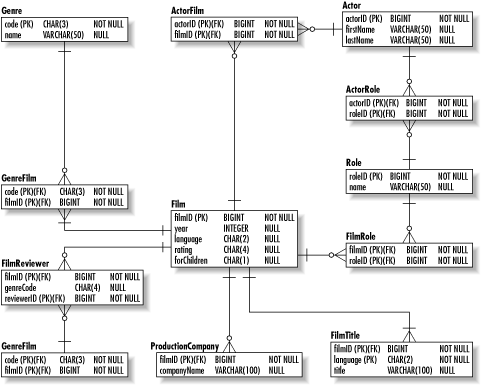 2.3.2.3 Third normal formA table is in the third normal form (3NF) when it is in 2NF and no transitive dependencies exist. A transitive dependency occurs when a functional dependency is inherited through some other identifying attribute. In our data model, the forChildren attribute depends on the rating attribute, which in turn depends on the filmID. Because the forChildren attribute has no direct dependency on the filmID, it is thus transitively dependent on the filmID. Violation of 3NF causes database anomalies. First of all, if the MPAA changes which ratings are suitable for children, you will need to update every instance of the Film entity to reflect that change. An insertion anomaly also exists in that any new ratings for children will not be reflected in existing films. Of course, the insertion anomaly is not a huge problem for this database since films rarely change ratings. Finally, deletion of the only row with a rating associated with being for children causes us to lose all information about it being for children.
To fix this problem, you need to move the transitively dependent value into a table that provides functional dependency. In other words, move the forChildren attribute into the Rating table as shown in Figure 2-8. Figure 2-8. The film database in 3NF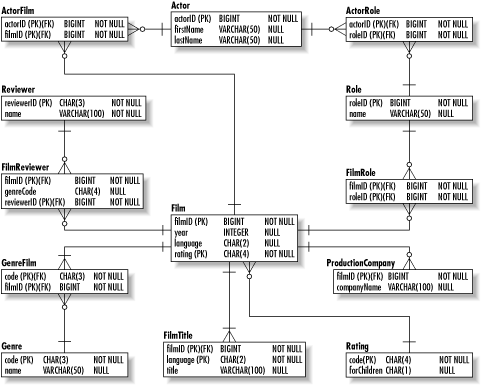 2.3.3 Specialized NormalizationHaving your database in 3NF is generally good enough to guarantee your system is free of the most common anomalies. The other forms of normalization handle special situations. In fact, if your database is not subject to the special considerations of Boyce-Codd normal form or fourth normal form, your database is automatically in 4NF. The fifth normal form is impossible to verify without computer-aided modeling tools and is rarely worth seeking. 2.3.3.1 Boyce-Codd normal formA table is in Boyce-Codd normal form (BCNF) when every determinant is a candidate key. A candidate key is a set of attributes that could potentially serve as a primary key. BCNF is essentially a more generalized form of 3NF. It specifically addresses issues that arise in tables with one or more of the following characteristics:
Our data model contains no relations to which BCNF applies. To illustrate BCNF, consider a table that contains three or more columns with a couple of the combinations capable of uniquely identifying a row. An example might be a Showing table that represents when a real estate agent shows a house to a client. The table has the structure shown in Table 2-5.
For the sake of this example, assume that a buyer gets only one chance to view a property. Furthermore, only one agent can show a property to one buyer in a given time slot. In that case, it is possible for notes to be determined by either of the following combinations:
You could choose either of the two combinations. BCNF simply states that as long as every column that determines notes is a candidate key, the table is in BCNF. 2.3.3.2 Fourth normal formA table is in the fourth normal form when it is in BCNF and all multivalued dependencies are also functional dependencies. The problem here with the current model is the FilmReviewer table. It ties film reviewers with the films and genres they review. Table 2-6 shows some sample data from the table.
The full set of columns forms the primary key for this table. It is thus normalized to BCNF. Unfortunately, it still contains redundant data. The redundancy is caused by multivalued dependencies. Specifically, reviewerID determines the values of filmID and genreCode independently. In the relations we have seen so far, the determinant establishes the full set of values that together form the instance. We can fix this problem by splitting genreCode's dependence into one table and reviewerID's dependence into another. For example, we can create a ReviewGenre table that captures the genres the reviewer specializes in. We can similarly create a ReviewerFilm table that contains the film reviews. Figure 2-9 shows the resulting data model. Figure 2-9. The film database in 4NF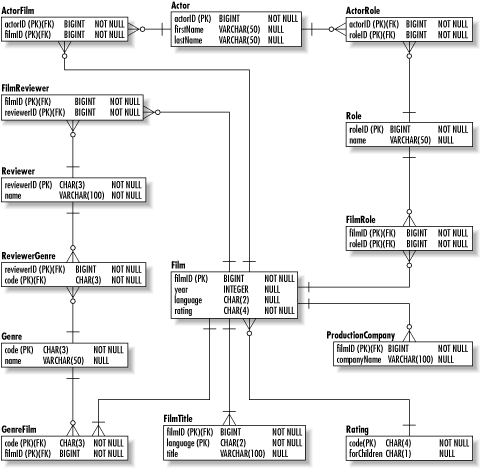 Spending time normalizing to the fourth normal form is useful only for data models that have a lot of complex join tables. If you have just a few such tables, you are probably already in 4NF anyway. If you are not, the anomaly is almost certainly of no consequence to your system. 2.3.3.3 Fifth normal formA table is in the fifth normal form (5NF) if it is in 4NF and cannot have lossless decomposition into any number of smaller tables. It is actually very hard to tell when a table is truly in 5NFjust about any table in 4NF is also in 5NF. It can occur in situations in which you have a many-to-many-to-many relationship as exists with Film, Actor, and Role. Given certain data, the database can end up making claims that simply are not true. For simplicity's sake, assume that the database has a single actor in it who has appeared in two separate films playing two separate roles. The joined information from these tables looks like the data in Table 2-7.
So far, this structure should seem quite normal to you. The three entities have three corresponding join tables ActorFilm, FilmRole, and ActorRole to help manage the relationships. The problem arises when you insert particular data, such as adding Robert Culp who also played the president, but in the movie The Pelican Brief. In short, we add one row to Actor, one row to ActorFilm, one row to ActorRow, and one row to FilmRole. No rows are added to Role or Film. The join suddenly ends up with both true claims and some utterly false ones as Table 2-8 shows.
The important thing to note about the database is that there is nothing wrong with the data in the tables. The only thing wrong is what the relationships among the tables imply given a very specific data set. By now, you have probably guessed that the solution is to create another entity to manage this trinary relationship. The Appearance table in the fully normalized Figure 2-10 manages this solution. Figure 2-10. The film database in 5NF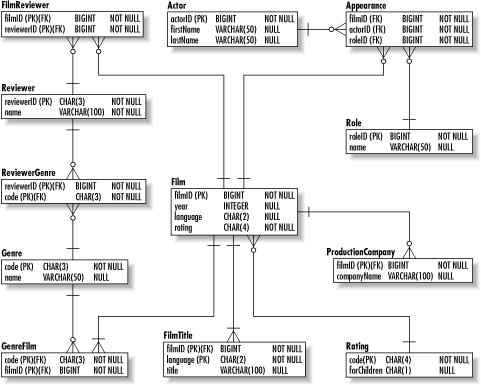 |
| [ Team LiB ] |
|
