| [ Team LiB ] |
|
3.1 TransactionsA transaction is an event or sequence of events that takes a database from one consistent state to the next. If any of the events fails or the sequence fails to complete, the system is returned to its initial state. Once it completes, it is guaranteed to be in the new consistent state until it is acted upon to completion by another transaction. 3.1.1 ACID RequirementsFormally, a transaction is a group of database operations that together have a shared set of guaranteed propertiescommonly known as ACID properties. ACID is an acronym that stands for Atomicity, Consistency, Isolation, and Durability.
In other words, if you have an account transfer, it meets ACID requirements in the following ways:
Your database engine is largely responsible for guaranteeing the ACIDity of your transactions. You, the software architect, are nevertheless responsible for identifying what events make up a transaction and how the application should package those transactions for the database.
3.1.2 Transaction DesignThe key to identifying transactions is determining what stages in your use cases represent consistent database states. If we examine the transfer example, we see two distinct events that make up the transfer:
After the debit of the savings account, the database is said to be in an inconsistent state because important information about the system would be lost should the transfer fail to complete. In this case, the important information is someone's money! Inconsistency can also mean having orphaned data in the database. Consider, for example, the deletion of a person from a database with the following steps:
If something goes wrong after the first step, you could end up with a database full of unreferenced addresses and phone numbers unless the transaction returns the system to its initial state. The database is therefore in an inconsistent state until all addresses and phone numbers are deleted. Though you want your transactions to be large enough to prevent the database from entering inconsistent states, you also want them as small as possible. As you will see later in this chapter, transactions make huge demands on a database. The larger the transaction, the more resources it eats and the worse the performance of your application.
To illustrate this problem in action, consider an e-commerce application that needs to create a customer before the customer can place an order. To make the application as easy to use for the customer as possible, you may let her enter her customer information along with her first order. The use case thus looks something like this:
It is the combined job of the business analyst and information architect to craft this use case as the best way for a new customer to buy something. It is your job as the software architect to figure out its implications on the database. In many situations, there will be a one-to-one correspondence between use cases and transactions. In this case, however, we have two separate transactions because the database can be in a consistent state with the customer information and no order information. In other words, steps 1-3 make up the first transaction and steps 4-6 make up the second. Figure 3-1 contrasts the use case from the client's perspective with the sequence from the architect's perspective. Figure 3-1. A multitransaction use case from the perspectives of a client application and an architect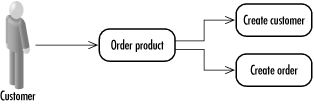 By breaking this one use case into two transactions, you will not sacrifice database consistency but you will gain performance. The division enhances performance because you enable other transactions that may be waiting on resources blocked only by the first three steps to execute prior to the completion of the entire use case. If you encapsulated the use case in a single transaction, then those other transactions would have to wait until the completion of the use case. Figure 3-2 shows how breaking the use case into two transactions can reduce blocking. Figure 3-2. Reduced blocking by dividing work between two transactions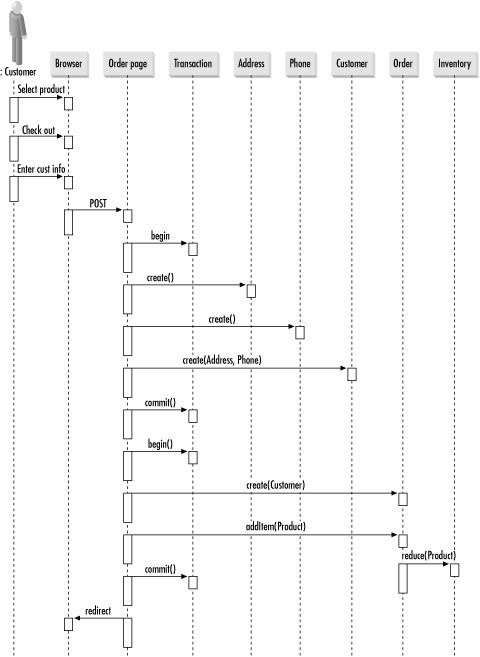 |
| [ Team LiB ] |
|
