| [ Team LiB ] |
|
6.2 Using XPathThe System.Xml.XPath assembly is relatively small, containing only five classes, six enumerations, and one interface. There are two ways to select nodes from an XML document with XPath. The first, which was introduced in Chapter 5, uses the SelectNodes( ) and SelectSingleNode( ) methods of XmlNode. The second way uses the XPathNavigator class, obtained by calling XmlNode.GetNavigator( ) or XPathDocument.GetNavigator( ). In this section, I'll discuss these methods of using XPath in .NET. 6.2.1 XmlNodeXmlNode defines two methods, with two overloads each, to allow navigation via XPath. SelectSingleNode( ) returns a single XmlNode that matches the given XPath, and SelectNodes( ) returns an XmlNodeList. 6.2.1.1 Selecting a single nodeSelectSingleNode( ) returns a single XmlNode that matches the given XPath expression. If more than one node matches the expression, the first one is returned; the definition of "first" depends on the order of the axis used. The context node of the XPath query is set to the XmlNode instance on which the method is invoked. One overload of SelectSingleNode( ) takes just the XPath expression. The other one takes the XPath expression and an XmlNamespaceManager. The XmlNamespaceManager is used to resolve any prefixes in the XPath expression. Example 6-2 shows a simple program that selects a single node from an XML document and writes it to the console, with human-readable formatting. Example 6-2. Program to execute an XPath query on a documentusing System;
using System.Xml;
using System.Xml.XPath;
public class XPathQuery {
public static void Main(string [ ] args) {
string filename = args[0];
string xpathExpression = args[1];
XmlDocument document = new XmlDocument( );
document.Load(filename);
XmlTextWriter writer = new XmlTextWriter(Console.Out);
writer.Formatting = Formatting.Indented;
XmlNode node = document.SelectSingleNode(xpathExpression);
node.WriteTo(writer);
writer.Close( );
}
}
Because SelectSingleNode( ) is called on the XmlNode instance that represents the entire document, the context node in this case is the document, and the XPath query will be executed relative to the entire document. However, the context node could be any other XmlNode in the document, depending on which XmlNode instance's SelectSingleNode( ) method is invoked. If you need to use a specific XmlNode subclass's methods or properties on the resulting XmlNode instance, it is up to the calling code to cast the XmlNode instance to the appropriate type. For example, if the XPath expression were to return an XmlElement instance, the code would explicitly have to cast the XmlNode to XmlElement in order to call, for example, GetAttribute( ) on it. But then you could also construct your XPath expression to just go ahead and select the attribute in question directly.
6.2.1.2 Selecting multiple nodesSelectNodes( ) is similar to SelectSingleNode( ), except that it returns an XmlNodeList rather than an XmlNode. XmlNodeList implements IEnumerable, so you can use any of the techniques commonly used to manage a collection. For example, you can interrogate the XmlNodeList's Count property to discover how many elements it contains, access each element with its array indexer, or use a foreach statement to iterate through the elements in order. I've modified the SelectSingleNode( ) example to select a list of nodes. The changed lines are highlighted: XmlDocument document = new XmlDocument( ); Document.Load(filename); XmlTextWriter writer = new XmlTextWriter(Console.Out); writer.Formatting = Formatting.Indented; XmlNodeList nodeList = document.SelectNodes(xpathExpression); Console.WriteLine("{0} nodes matched.", nodeList.Count); foreach (XmlNode node in nodeList) { node.WriteTo(writer); } writer.Close( ); As with SelectSingleNode( ), it is up to the calling code to ensure that any casts are correct; this includes the implicit cast in the foreach statement. In this example, however, the foreach will always succeed, because each element of an XmlNodeList is, by definition, an instance of XmlNode. Also like SelectSingleNode( ), one overload of SelectNodes( ) takes an XmlNamespaceManager parameter. 6.2.1.3 Creating an XPathNavigatorIn addition to the SelectSingleNode( ) and SelectNodes( ) methods, XmlNode implements the IXPathNavigable interface. The only method that IXPathNavigable requires is CreateNavigator( ). CreateNavigator( ) returns an XPathNavigator, which provides an efficient, read-only, random-access model of the XmlNode. Once you have an XPathNavigator, you can call its Select( ) method to navigate to a node or set of nodes using an XPath expression. The following code produces the same output as the SelectNodes( ) example above: XmlDocument document = new XmlDocument( );
Document.Load(filename);
XmlTextWriter writer = new XmlTextWriter(Console.Out);
writer.Formatting = Formatting.Indented;
XPathNavigator navigator = document.CreateNavigator( );
XPathNodeIterator iterator = navigator.Select(xpathExpression);
Console.WriteLine("{0} nodes matched.", iterator.Count);
while (iterator.MoveNext( )) {
XmlNode node = ((IHasXmlNode)iterator.Current).GetNode( );
node.WriteTo(writer);
}
writer.Close( );
A couple of lines in this example bear closer investigation: XPathNodeIterator iterator = navigator.Select(xpathExpression); XPathNavigator has a Select( ) method that returns an XPathNodeIterator. Select( ) itself has two overloads, one that takes a string XPath expression, and one that takes a precompiled XPathExpression. A compiled XPathExpression can be obtained by passing a textual XPath expression to the XPathNavigator.Compile( ) method. If you were going to select the same XPath expression multiple times or from different context nodes, it would be more efficient to use a compiled XPathExpression. In the previous example, I used the version of Select( ) that takes a string parameter.In the following example, I'm using a compiled XPathExpression: XPathExpression expression = navigator.Compile(xpathExpression); XPathNodeIterator iterator = navigator.Select(expression); Other useful methods that XPathExpression provides include AddSort( ), whose two overloads allow you to sort the set of nodes resulting from the expression, and SetContext( ), which allows you to set the XmlNamespaceManager used to look up namespace prefixes. In addition to the two Select( ) overloads, XPathNavigator provides a set of selector methods, including SelectAncestors( ), SelectChildren( ), and SelectDescendants( ), each of which returns an XPathNodeIterator ready for use in navigating the set of results.
Each of these methods has two overloads; one of which takes an XPathNodeType, while the other takes a string local name and namespace URI. In all these methods, the parameters determine which nodes will be selected, relative to the XPathNavigator's context node: while (iterator.MoveNext( )) {
XPathNodeIterator represents a set of nodes returned from an XPath expression. Its interesting methods include Clone( ) and MoveNext( ). Clone( ), which implements the .NET Framework's ICloneable interface, returns a new XPathNodeIterator whose state is the same as the original one, but further changes to either the original or the clone will not affect the other. Thus, cloning an XPathNodeIterator allows you to work with XPath query results by allowing you to navigate through different branches of the XML tree. MoveNext( ) moves the XPathNodeIterator's position to the next node. XPathNodeIterator's interesting properties include Count, Current, and CurrentPosition. Current returns a new XPathNavigator whose context node is the XPathNodeIterator's current node. Like cloning an XPathNodeIterator, this allows you to navigate through XML branches. Count and CurrentPosition return the number of nodes selected and the XPathNodeIterator's current position, respectively: XmlNode node = ((IHasXmlNode)iterator.Current).GetNode( ); Since the XPathNavigator in this example was obtained by calling XmlNode.GetNavigator( ), it implements the IHasXmlNode interface. IHasXmlNode's sole method, GetNode( ), returns the XPathNodeIterator's context node. So this line of code gets an XPathNavigator whose context node is the same as the XPathIterator instance's current node and casts it to an IHasXmlNode in order to get its current XmlNode. It's important to remember the distinction between the XPathNodeIterator.Current property, which returns a new XPathNavigator positioned at the context node, and the IHasXmlNode.GetNode( ) method, which returns the context node as an XmlNode. By casting an XPathNavigator to an IHasXmlNode, you can get access to the current XmlNode itself. 6.2.2 XPathDocumentYou might not want to load a complete XmlDocument just to use XPath. An XmlDocument brings with it all the DOM overhead, allowing you to not only read but to write to the XML node tree. For read-only access, there is the XPathDocument class. Like XmlNode, it implements IXPathNavigable; but unlike XmlNode, it represents a read-only view of the XML document. XPathDocument does not maintain node identity like XmlDocument, nor does it do any rule checking required by the DOM. It is optimized for XPath queries and XSLT processing.
XPathDocument's sole purpose is to serve as an implementation of IXPathNavigable. It has constructors that take a Stream, a URL, a TextReader, and an XmlReader, respectively, and its only other method is CreateNavigator( ). An XPathNodeIterator obtained from an XPathDocument does not implement IHasXmlNode. Each element of the XPathNodeIterator is actually an XPathDocumentNavigator, and does not have a GetNode( ) method. Remember that the XPathDocument is not an XmlDocument; that is, it does not implement the DOM specification, so it is not navigable as a tree of XmlNode instances. If it's important to you that you be able to access the nodes using DOM, use XmlDocument.CreateNavigator( ). XPathDocumentNavigator does have some properties and methods with which you can access node-specific information. XPathDocumentNavigator implements the following abstract properties and methods of XPathNavigator: HasAttributes, HasChildren, IsEmptyElement, LocalName, Name, NamespaceURI, NodeType (which returns an XPathNodeType, not an XmlNodeType), Value, and GetAttribute( ). With the following modifications to your XPath query code, the current node's name is written to the console: XPathDocument document = new XPathDocument(filename); XPathNavigator navigator = document.CreateNavigator( ); XPathNodeIterator iterator = navigator.Select(xpathExpression); Console.WriteLine("{0} nodes matched.", iterator.Count); while (iterator.MoveNext( )) { Console.WriteLine(iterator.Current.LocalName); } writer.Close( );
6.2.3 Navigating a Non-XML Document with XPathOne of the most interesting and unique aspects of .NET's XML implementation is the fact that you can read non-XML data as if it were XML by creating subclasses of its abstract types. You saw this already in XmlReader and XmlWriter. Because you can read an XmlDocument from any XmlReader, it follows that you can call that XmlDocument's SelectSingleNode( ) and CreateNavigator( ) methods to navigate the document via XPath. You can also create an XPathDocument from any XmlReader, and use its CreateNavigator( ) method. In addition to that, however, you can also create a custom implementation of XPathNavigator to navigate any source document with XPath. 6.2.3.1 Using a custom XmlReaderYou've already created and used XmlPyxReader in Chapter 4. Since XmlPyxReader is just like any other instance of XmlReader, you can pass it to XPathDocument's constructor and navigate it using XPath: XmlReader reader = new XmlPyxReader(filename); XPathDocument document = new XPathDocument(reader); XPathNavigator navigator = document.CreateNavigator( ); XPathNodeIterator iterator = navigator.Select(xpathExpression); Console.WriteLine("{0} nodes matched.", iterator.Count); while (iterator.MoveNext( )) { Console.WriteLine(iterator.Current.LocalName); } writer.Close( ); 6.2.3.2 Using a custom XPathNavigatorThe next possibility is to skip over the custom XmlReader and go directly to a custom XPathNavigator. Like custom XmlReaders, custom XPathNavigators have numerous methods and properties to implement. You've already seen that Angus Hardware uses XML files to manage their purchase orders. But what about when they want to manage the purchase orders at a higher level? For example, POs may come in from any of several clients, and they should be managed by the date on which they arrive. Angus Hardware's IT department maintains POs in a filesystem, with a structure as shown in Figure 6-1. Figure 6-1. Purchase order directory structure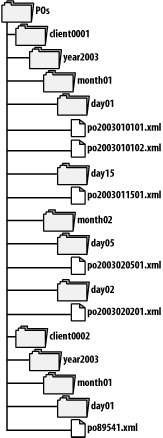 Obviously, they'd like to be able quickly to find particular invoices, either by client or by date. What they need is a custom XPathNavigator. First, some design specifics. Each directory and PO file in the PO tree will be represented as an element. None of these elements have attributes. At the very lowest level, the PO XML file itself will be represented as an element with a name in the form ponumber. I'm going to show you one way to write a custom XPathNavigator to navigate a filesystem using XPath. I'll go through this code one section at a time, beginning with the constructors for the FileSystemNavigator class: public FileSystemNavigator( ) {
rootDir = new DirectoryInfo(Environment.CurrentDirectory);
state.Push(new FileSystemState(rootDir));
}
public FileSystemNavigator(string path) {
rootDir = new DirectoryInfo(path);
state.Push(new FileSystemState(rootDir));
}
private FileSystemNavigator(FileSystemInfo d) {
rootDir = (DirectoryInfo)d;
state.Push(new FileSystemState(rootDir));
}
The three constructors should handle all the cases of interest: the default, which uses the current directory; one that takes a string, which is the path name; and one that takes a FileSystemInfo representing the root directory of the file structure. FileSystemInfo is the base type from which both FileInfo and DirectoryInfo are derived. The three private instance variables hold the following: the root directory, for later reference; an XmlNameTable, which will be used externally for atomized name comparisons; and a Stack, holding the current node and its ancestors as the document is navigated: private DirectoryInfo rootDir; private XmlNameTable nameTable = new NameTable( ); private Stack state = new Stack( ); CurrentState is a property I've defined for convenience. It returns the current FileSystemState (an internal class which you'll see on the next page) by calling Peek( ) on the state instance variable: private FileSystemState CurrentState {
get {
return (FileSystemState)state.Peek( );
}
}
These two GetChildren( ) convenience methods, the instance version of which calls the static version, know how to return only the child nodes that you're interested in. For example, if the current node is the year2002 element, you're only interested in seeing its elements whose names begin with month, not any other files or directories that happen to be in the year2002 directory: private FileSystemInfo [ ] GetChildren( ) {
return GetChildren(CurrentState.Entry);
}
internal static FileSystemInfo [ ] GetChildren(FileSystemInfo entry) {
if (entry is DirectoryInfo) {
DirectoryInfo dir = (DirectoryInfo)entry;
if (dir.Name == "POs") {
return dir.GetDirectories("client*");
} else if (dir.Name.StartsWith("client")) {
return dir.GetDirectories("year*");
} else if (dir.Name.StartsWith("year")) {
return dir.GetDirectories("month*");
} else if (dir.Name.StartsWith("month")) {
return dir.GetDirectories("day*");
} else if (dir.Name.StartsWith("day")) {
return dir.GetFiles("po*.xml");
} else {
return dir.GetDirectories("POs");
}
}
return new FileSystemInfo [0];
}
The Clone( ) method is required in order to implement the ICloneable interface, which is inherited from XPathNavigator: public override XPathNavigator Clone( ) {
FileSystemNavigator fsn = new FileSystemNavigator(CurrentState.Entry);
fsn.nameTable = this.nameTable;
return fsn;
}
The rest of the methods override XPathNavigator's abstract methods and properties. In the interest of saving space, I've not reproduced the ones that unconditionally return empty string instances (BaseURI, XmlLang, Value, GetAttribute( ), GetNamespace( ), Prefix NamespaceURI) or false (HasAttributes, MoveToAttribute( ), MoveToFirstAttribute( ), MoveToNextAttribute( ), MoveToNamespace( ), MoveToFirstNamespace( ), MoveToNextNamespace( ). MoveToId( )). Since the filesystem model is not described with a URL, and isn't itself XML, the pseudo-elements have no value, and the model does not include attributes or namespaces, these methods and properties are irrelevant. In this model, each node is either the root or an element. If the current directory is the root directory, the type must be XPathNodeType.Root. Otherwise, it is XPathNodeType.Element: public override XPathNodeType NodeType {
get {
if (state.Count == 1)
return XPathNodeType.Root;
else
return XPathNodeType.Element;
}
}
Each element's Name is simply the name of the current FileSystemInfo entry. Since the filesystem has no namespace, the Name is the same as the LocalName. Within LocalName, the name is added to the nameTable instance variable so that atomized string comparisons use the XmlNameTable properly: public override string LocalName {
get {
string name = CurrentState.Entry.Name;
nameTable.Add(name);
return name;
}
}
public override string Name {
get {
return LocalName;
}
}
The NameTable property simply returns the nameTable instance variable. public override XmlNameTable NameTable {
get {
return nameTable;
}
}
Any node with no children is empty. The HasChildren property uses the GetChildren( ) convenience method to get, and count, the child nodes: public override bool IsEmptyElement {
get {
return !HasChildren;
}
}
public override bool HasChildren {
get {
return (GetChildren( ).Length > 0);
}
}
The MoveTo*( ) methods make sure that the FileSystemState at the top of the stack always reflects the right information. To do this, it changes the Entry and Position variables, as necessary. Additionally, MoveToParent( ) pops the FileSystemState off the top of the stack, and MoveToFirstChild( ) pushes a new one on. MoveToRoot( ) and MoveToDocumentElement( ) clear the stack and push a new FileSystemState on, representing the top of the tree: public override bool MoveToNext( ) {
if (CurrentState.Position < CurrentState.Siblings.Length - 1) {
CurrentState.Entry = CurrentState.Siblings[++CurrentState.Position];
return true;
} else {
return false;
}
}
public override bool MoveToPrevious( ) {
if (CurrentState.Position > 0) {
CurrentState.Entry = CurrentState.Siblings[--CurrentState.Position];
return true;
} else {
return false;
}
}
public override bool MoveToFirst( ) {
CurrentState.Position = 0;
CurrentState.Entry = CurrentState.Siblings[CurrentState.Position];
return true;
}
public override bool MoveToFirstChild( ) {
FileSystemInfo [ ] children = GetChildren( );
if (children.Length > 0) {
state.Push(new FileSystemState(children[0]));
return true;
} else {
return false;
}
}
public override bool MoveToParent( ) {
if (CurrentState.Entry == rootDir) {
return false;
} else {
state.Pop( );
return true;
}
}
public override void MoveToRoot( ) {
state.Clear( );
state.Push(new FileSystemState(rootDir));
}
public bool MoveToDocumentElement( ) {
MoveToRoot( );
return true;
}
public override bool MoveTo( XPathNavigator other ) {
if (other is FileSystemNavigator) {
FileSystemNavigator fsn = (FileSystemNavigator)other;
state = fsn.state;
return true;
}
return false;
}
IsSamePosition( ) compares this XPathNavigator to another one, returning true if they share the same XmlImplementation and XmlDocument, and if they both share the same context node: public override bool IsSamePosition( XPathNavigator other ) {
if (other is FileSystemNavigator) {
FileSystemNavigator fsn = (FileSystemNavigator)other;
if (CurrentState == fsn.CurrentState) {
return true;
}
}
return false;
}
As I've already described, the FileSystemState class is used internally in the FileSystemNavigator to hold the data about a filesystem entry, which is represented as a node in the XML tree, and about its siblings: internal class FileSystemState {
public FileSystemInfo Entry;
public int Position;
public FileSystemInfo [ ] Siblings;
public FileSystemState(FileSystemInfo dir) {
Entry = dir;
Position = 0;
if (dir is DirectoryInfo) {
Siblings = FileSystemNavigator.GetChildren(((DirectoryInfo)dir).Parent);
} else {
Siblings = FileSystemNavigator.GetChildren(((FileInfo)dir).Directory);
}
}
public override bool Equals(object other) {
FileSystemState state = other as FileSystemState;
if (state != null && state.GetHashCode( ) == GetHashCode( )) {
return true;
} else {
return false;
}
}
public override int GetHashCode( ) {
return Entry.GetHashCode( ) | Position.GetHashCode( );
}
}
Example 6-3 shows the complete FileSystemNavigator program. Example 6-3. FileSystemNavigatorusing System;
using System.Collections;
using System.IO;
using System.Xml;
using System.Xml.XPath;
public class FileSystemNavigator : XPathNavigator {
// Constructors
public FileSystemNavigator( ) {
rootDir = new DirectoryInfo(Environment.CurrentDirectory);
state.Push(new FileSystemState(rootDir));
}
public FileSystemNavigator(string path) {
rootDir = new DirectoryInfo(path);
state.Push(new FileSystemState(rootDir));
}
private FileSystemNavigator(FileSystemInfo d) {
rootDir = (DirectoryInfo)d;
state.Push(new FileSystemState(rootDir));
}
// Private instance variables
private DirectoryInfo rootDir;
private XmlNameTable nameTable = new NameTable( );
private Stack state = new Stack( );
// private properties
private FileSystemState CurrentState {
get {
return (FileSystemState)state.Peek( );
}
}
// private methods
private FileSystemInfo [ ] GetChildren( ) {
return GetChildren(CurrentState.Entry);
}
internal static FileSystemInfo [ ] GetChildren(FileSystemInfo entry) {
if (entry is DirectoryInfo) {
DirectoryInfo dir = (DirectoryInfo)entry;
if (dir.Name == "POs") {
return dir.GetDirectories("client*");
} else if (dir.Name.StartsWith("client")) {
return dir.GetDirectories("year*");
} else if (dir.Name.StartsWith("year")) {
return dir.GetDirectories("month*");
} else if (dir.Name.StartsWith("month")) {
return dir.GetDirectories("day*");
} else if (dir.Name.StartsWith("day")) {
return dir.GetFiles("po*.xml");
} else {
return dir.GetDirectories("POs");
}
}
return new FileSystemInfo [0];
}
// public methods, from ICloneable
public override XPathNavigator Clone( ) {
FileSystemNavigator fsn = new FileSystemNavigator(CurrentState.Entry);
fsn.nameTable = this.nameTable;
return fsn;
}
// public methods, from XPathNavigator
public override string BaseURI {
get {
return String.Empty;
}
}
public override string XmlLang {
get {
return String.Empty;
}
}
public override XPathNodeType NodeType {
get {
if (state.Count == 1)
return XPathNodeType.Root;
else
return XPathNodeType.Element;
}
}
public override string LocalName {
get {
string name = CurrentState.Entry.Name;
nameTable.Add(name);
return name;
}
}
public override string NamespaceURI {
get {
return nameTable.Add(string.Empty);
}
}
public override string Name {
get {
return LocalName;
}
}
public override string Prefix {
get {
return nameTable.Add(string.Empty);
}
}
public override string Value {
get {
return string.Empty;
}
}
public override bool IsEmptyElement {
get {
return !HasChildren;
}
}
public override XmlNameTable NameTable {
get {
return nameTable;
}
}
public override bool HasAttributes {
get {
return false;
}
}
public override string GetAttribute( string localName, string namespaceURI ) {
return string.Empty;
}
public override bool MoveToAttribute( string localName, string namespaceURI ) {
return false;
}
public override bool MoveToFirstAttribute( ) {
return false;
}
public override bool MoveToNextAttribute( ) {
return false;
}
public override string GetNamespace(string prefix) {
return String.Empty;
}
public override bool MoveToNamespace(string prefix) {
return false;
}
public override bool MoveToFirstNamespace(XPathNamespaceScope namespaceScope) {
return false;
}
public override bool MoveToNextNamespace(XPathNamespaceScope namespaceScope) {
return false;
}
public override bool HasChildren {
get {
return (GetChildren( ).Length > 0);
}
}
public override bool MoveToNext( ) {
if (CurrentState.Position < CurrentState.Siblings.Length - 1) {
CurrentState.Entry = CurrentState.Siblings[++CurrentState.Position];
return true;
} else {
return false;
}
}
public override bool MoveToPrevious( ) {
if (CurrentState.Position > 0) {
CurrentState.Entry = CurrentState.Siblings[--CurrentState.Position];
return true;
} else {
return false;
}
}
public override bool MoveToFirst( ) {
CurrentState.Position = 0;
CurrentState.Entry = CurrentState.Siblings[CurrentState.Position];
return true;
}
public override bool MoveToFirstChild( ) {
FileSystemInfo [ ] children = GetChildren( );
if (children.Length > 0) {
state.Push(new FileSystemState(children[0]));
return true;
} else {
return false;
}
}
public override bool MoveToParent( ) {
if (CurrentState.Entry == rootDir) {
return false;
} else {
state.Pop( );
return true;
}
}
public override void MoveToRoot( ) {
state.Clear( );
state.Push(new FileSystemState(rootDir));
}
public bool MoveToDocumentElement( ) {
MoveToRoot( );
return true;
}
public override bool MoveTo( XPathNavigator other ) {
if (other is FileSystemNavigator) {
FileSystemNavigator fsn = (FileSystemNavigator)other;
state = fsn.state;
return true;
}
return false;
}
public override bool MoveToId( string id ) {
return false;
}
public override bool IsSamePosition( XPathNavigator other ) {
if (other is FileSystemNavigator) {
FileSystemNavigator fsn = (FileSystemNavigator)other;
if (fsn.CurrentState == CurrentState) {
return true;
}
}
return false;
}
}
internal class FileSystemState {
public FileSystemInfo Entry;
public int Position;
public FileSystemInfo [ ] Siblings;
public FileSystemState(FileSystemInfo dir) {
Entry = dir;
Position = 0;
if (dir is DirectoryInfo) {
Siblings = FileSystemNavigator.GetChildren(((DirectoryInfo)dir).Parent);
} else {
Siblings = FileSystemNavigator.GetChildren(((FileInfo)dir).Directory);
}
}
public override bool Equals(object other) {
FileSystemState state = other as FileSystemState;
if (state != null && state.GetHashCode( ) == GetHashCode( )) {
return true;
} else {
return false;
}
}
public override int GetHashCode( ) {
return Entry.GetHashCode( ) | Position.GetHashCode( );
}
}
Now you can navigate the PO directory structure using XPath with the previous code, with one small change to the program in Example 6-2: XPathNavigator navigator = new FileSystemNavigator( );
XPathNodeIterator iterator = navigator.Select(xpathExpression);
Console.WriteLine("{0} nodes matched.", iterator.Count);
while (iterator.MoveNext( )) {
Console.WriteLine(iterator.Current.LocalName);
}
writer.Close( );
|
| [ Team LiB ] |
|
