GROUP BY is used in combination with aggregate functions to calculate statistical values. The columns referred to by GROUP BY are sometimes called dimension columns. CUBE and ROLLUP are used to summarize the value further to show subtotals and totals. The differences between CUBE and ROLLUP are:
CUBE generates subtotals for all combinations of values in dimension columns.
ROLLUP generates subtotals for a hierarchy of values in dimension columns.
For example, if you want to find out the sale value of Orders, then you would run the following query:
SELECT SUM( [Order Details].UnitPrice *
[Order Details].Quantity *
(1 - [Order Details].Discount)
) as [Sale Value]
FROM [Order Details]
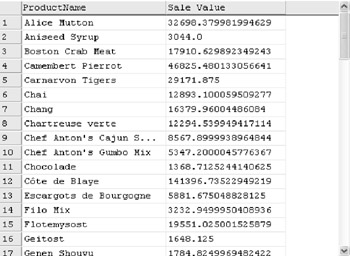
This is a simple query and will return just one value. Now let’s do something more complicated and try to find the sale value for each product.
The result will show the total for ProductName. We are assuming that ProductName is unique for each product. Figure D-3 shows a small part of a sample result set.
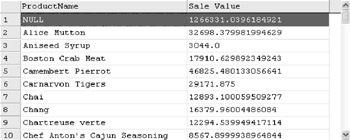
The result, however, does not show total sale value. To do this, you need to use ROLLUP or CUBE. The result is the same for both because there is only one non-aggregate column.
SELECT Products.ProductName,
SUM( [Order Details].UnitPrice *
[Order Details].Quantity *
(1 - [Order Details].Discount)
) as [Sale Value]
FROM [Order Details]
INNER JOIN Products
ON [Order Details].ProductID = Products.ProductID
GROUP BY Products.ProductName WITH ROLLUP
ORDER BY Products.ProductName
The result produces an extra row with a value of null for ProductName and the grand total for sale value. See Figure D-4.
With CUBE and ROLLUP, null means all values for that particular column. We can modify the query so that it reflects that fact.
SELECT CASE WHEN
(GROUPING(Products.ProductName) = 1)
THEN '<-- ALL -->'
ELSE
ISNULL(Products.ProductName, 'UNKNOWN')
END AS [Product Name],
SUM( [Order Details].UnitPrice *
[Order Details].Quantity *
(1 - [Order Details].Discount)
) as [Sale Value]
FROM [Order Details]
INNER JOIN Products
ON [Order Details].ProductID = Products.ProductID
GROUP BY Products.ProductName WITH ROLLUP
ORDER BY [Product Name]
Now null is replaced by <-- ALL -->.
| Note |
GROUPING (<Column Name>) is an aggregate function that returns a value of 1 when the row is added by either the CUBE or ROLLUP operator or 0 when the row is not the result of CUBE or ROLLUP. |
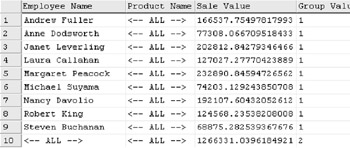
Let’s expand the example to include “Employee Name.” Employee Name is a computed field made up of FirstName and LastName. To match to unique employees we use the Employees table primary key, EmployeeID, in the GROUP BY. GROUP BY restricts the column that you can use in the SELECT section without the use of an aggregate function to only those referred to in the GROUP BY section of the script. To overcome this limitation, we can use the aggregate function MIN or MAX (minimum value and maximum value, respectively) on FirstName and LastName. Since for any given EmployeeID, the FirstName and LastName are the same; then the actual value for FirstName and LastName is returned. We can also include a special field that we can use for sorting so that all the totals are together. Obviously, the one with the biggest group value is the grand total.
SELECT CASE WHEN
(GROUPING(Employees.EmployeeID) = 1)
THEN '<-- ALL -->'
ELSE
ISNULL( max( Employees.FirstName) + ' ' +
max(Employees.LastName),
'UNKNOWN')
END as [Employee Name] ,
CASE WHEN
(GROUPING(Products.ProductName) = 1)
THEN '<-- ALL -->'
ELSE
ISNULL(Products.ProductName, 'UNKNOWN')
END AS [Product Name],
SUM( [Order Details].UnitPrice *
[Order Details].Quantity *
(1 - [Order Details].Discount)
) as [Sale Value],
GROUPING(Employees.EmployeeID)
+ GROUPING(ProductName) as [Group Value]
FROM Employees
INNER JOIN Orders
ON Employees.EmployeeID = Orders.EmployeeID
INNER JOIN
[Order Details]
ON Orders.OrderID = [Order Details].OrderID
INNER JOIN Products
ON [Order Details].ProductID = Products.ProductID
GROUP BY Employees.EmployeeID, Products.ProductName WITH
ROLLUP
ORDER BY [Group Value],
[Employee Name],
Products.ProductName
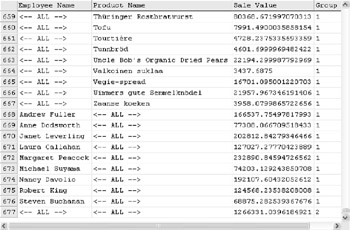
The additional rows generated by ROLLUP are shown in Figure D-5.
As you can see in the figure above, the sample data I used resulted in 600 rows being generated. ROLLUP finds all combinations of Employee Name against Product Name. If we use CUBE instead, more additional rows will be generated because CUBE will generate all possible combinations of Employee Name against Product Name and also all possible combinations of Product Name against Employee Name.
As you can see in Figure D-6, with the sample data I used, CUBE generated 677 rows compared to the 600 rows by ROLLUP.
Since CUBE generated a lot of data and might be difficult to read, the best way to use CUBE is to make it into a view and then use the view to see only the part of the data that you are interested in.
if exists
(select * from sysobjects where id = object_id(N'[CUBE
EmployeeProduct]')
and OBJECTPROPERTY(id, N'IsView') = 1)
drop view [CUBE EmployeeProduct]
GO
CREATE VIEW [CUBE EmployeeProduct]
AS
SELECT CASE WHEN
(GROUPING(Employees.EmployeeID) = 1)
THEN '<-- ALL -->'
ELSE
ISNULL( max( Employees.FirstName) + ' ' +
max(Employees.LastName),
'UNKNOWN')
END as [Employee Name] ,
CASE WHEN
(GROUPING(Products.ProductName) = 1)
THEN '<-- ALL -->'
ELSE
ISNULL(Products.ProductName, 'UNKNOWN')
END AS [Product Name],
SUM( [Order Details].UnitPrice *
[Order Details].Quantity *
(1 - [Order Details].Discount)
) as [Sale Value],
GROUPING(Employees.EmployeeID)
+ GROUPING(ProductName) as [Group Value]
FROM Employees
INNER JOIN Orders
ON Employees.EmployeeID = Orders.EmployeeID
INNER JOIN
[Order Details]
ON Orders.OrderID = [Order Details].OrderID
INNER JOIN Products
ON [Order Details].ProductID = Products.ProductID
GROUP BY Employees.EmployeeID, Products.ProductName WITH
CUBE
GO
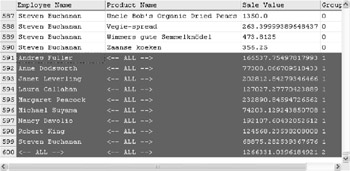
Once you have created the view, you can reduce the amount of data returned.
SELECT * FROM [CUBE EmployeeProduct]
WHERE [Product Name] = '<-- ALL -->'
ORDER BY [Group Value],
[Employee Name]
The result is shown in Figure D-7.