With previous versions of ActiveX Data Objects (ADO), code written to work with relational data was different from code written to work with hierarchical data. This meant that you had two programming models to work with. In the .NET Framework, several classes in XML are integrated with classes in the ADO .NET architecture, unifying the two programming models. In .NET, the DataSet represents a relational data source in ADO .NET, whereas the XmlDocument implements the DOM in XML. The XmlDataDocument unifies the ADO .NET and XML by representing relational data from a DataSet and synchronizing it with the XML document model.
Before we move on, it is interesting to note that Microsoft SQL Server can also directly return result sets as XML. The following example returns all rows from the Employees table from the Northwind sample database encoded as nested XML:
SELECT * FROM Employees FOR XML AUTO, ELEMENTS
The partial result will be something like this:
<Employees> <EmployeeID>1</EmployeeID> <LastName>Davolio</LastName> <FirstName>Nancy</FirstName> <Title>Sales Representative</Title> <TitleOfCourtesy>Ms.</TitleOfCourtesy> <BirthDate>1948-12-08T00:00:00</BirthDate> <HireDate>1992-05-01T00:00:00</HireDate> <Address> 507 - 20th Ave. E. Apt. 2A</Address> …
You can make use of this feature in .NET if you wish:
Dim custXmlCMD As SqlCommand
'Define SQL Command that returns XML
custXmlCMD = _
New SqlCommand("SELECT * FROM Customers FOR XML AUTO,
ELEMENTS", northwindconnection)
'Execute the command directly into an XmlReader
Dim myXmlReader As System.Xml.XmlReader =_
custXmlCMD.ExecuteXmlReader()
Expect to see future versions of Microsoft SQL Server to support more XML functionality. The next version of MS SQL, code-named Yukon, will be integrated in the .NET Framework. The stored procedures will run on the .NET Common Language Runtime (CLR). In effect, all the .NET XML features will also be available in Yukon.
Using ADO .NET, you can fill a DataSet from an XML data source. The XML data source can be an XML stream or document. You can use an XML data source to supply the DataSet with data, schema information, or both. You can use the information supplied and combine it with existing data or schema in the DataSet.
ADO .NET also allows you to do the reverse. With a DataSet, you can create its XML representation, with or without its schema, in order to transport the DataSet across HTTP for use on other XML-enabled platforms. In the generated XML representation of the DataSet, data is written in XML and the schema is written using the XML Schema Definition (XSD) language, if it is included inline in the representation. This provides a convenient format for transferring DataSet contents to and from remote clients over standard existing Internet HTTP infrastructures.
The DataSet uses the DiffGram XML format to keep track of changes in XML data. This is particularly important in a stateless web environment where it is not practical to maintain a continuous connection to a database. The DiffGram format is used to identify current and original versions of data elements. The DataSet uses the DiffGram format to load, persist, and serialize its contents for transport across a network connection. The DataSet populates the DiffGram with all necessary information to accurately recreate the contents, though not the schema, of the DataSet. The DiffGram includes column values from both the original and the current row versions, row error information, and row order.
The DiffGram format that is used by the .NET Framework can be used as a basis for communication with other platforms. When sending and retrieving a DataSet from an XML web service, the DiffGram format is implicitly used, even though this is more or less transparent to the developer. With the ReadXml and WriteXml method, you can explicitly specify that the content to be read is a DiffGram or the content is to be written as a DiffGram.
The DiffGram format is divided into three sections: the current data, the original data, and an errors section.
<?xml version="1.0"?> <diffgr:diffgram xmlns:msdata="urn:schemas-microsoft-com:xml-msdata" xmlns:diffgr="urn:schemas-microsoft-com:xml-diffgram-v1" xmlns:xsd="http://www.w3.org/2001/XMLSchema"> <Data> ... </Data> <diffgr:before> </diffgr:before> <diffgr:errors> </diffgr:errors> </diffgr:diffgram>
The DiffGram format consists of the following blocks of data:
<Data> </Data>: The name of this element, <Data>, is used for illustration purposes only. In an actual DiffGram, the <Data></Data> block represents a DataSet or a row of a DataTable. Instead of the <Data></Data> block, the DiffGram format contains the current data, whether it has been modified or not. An element, or row, that has been modified is identified with the diffgr:hasChanges annotation.
<diffgr:before>: This block of the DiffGram format contains the original version of a row. Elements in this block are matched to elements in the <Data>
</Data> block using the diffgr:id annotation.
<diffgr:errors>: This block of the DiffGram format contains error information for a particular row in the <Data></Data> block. Elements in this block are matched to elements in the <Data></Data> block using the diffgr:id annotation.
The DiffGram also uses the following annotation that is defined in the DiffGram namespace urn:schemas-microsoft-com:xml-diffgram-v1:
id: Used to match the elements in the <diffgr:before> and <diffgr:errors> blocks to elements in the <Data> block. Values with the diffgr:id annotation are in the form [TableName][RowIdentifier] (for example: <products diffgr:id="Products1">).
parentId: Identifies which element from the <Data> block is the parent element of the current element. Values with the diffgr:parentId annotation are in the form [TableName][RowIdentifier] (for example: <Orders diffgr:parentId="Products1">).
hasChanges: Identifies a row in the <Data> block as modified. The hasChanges annotation can have one of the following three values:
inserted: Identifies an added row
modified: Identifies a modified row that contains an original row version in the <diffgr:before> block. Deleted rows will have an original row version in the <diffgr:before> block, but there will be no annotated element in the <Data> block.
descent: Identifies an element where one or more children from a parent-child relationship have been modified
hasErrors: Identifies a row in the <Data> block with a RowError. The error element is placed in the <diffgr:errors> block.
Error: Contains the error description text of the RowError for a particular element in the <diffgr:errors> block
There are also two other annotations that are used by DataSet when reading and writing contents as a DiffGram. They are defined in the namespace urn:schemas-microsoft-com:xml-msdata.
RowOrder: DataSet to preserve the row order of the original data and identify the index of a row in a particular DataTable
Hidden: Identifies a column as having a ColumnMapping property set to MappingType.Hidden. The attribute is written in the format msdata:hidden[ColumnName]="value".
For example:
<Products diffgr:id="Products1" msdata:hiddenSupplierTitle="Primary">.
Note that hidden columns are only written as a DiffGram attribute if they contain data. Otherwise, they are ignored.
Let’s look at a sample DiffGram. Below is the start or header section:
<diffgr:diffgram xmlns:msdata="urn:schemas-microsoft- com:xml-msdata" xmlns:diffgr="urn:schemas-microsoft- com:xml-diffgram-v1">
Below is the data section:
<ProductsDataSet>
<Products diffgr:id="Products1" msdata:rowOrder="0"
diffgr:hasChanges="modified">
<ProductID>SMCHEESE001</CustomerID>
<productname>Smelly Cheese</productname>
<price format="dollar">100.99</price>
<expirydate>01/01/2009</expirydate>
</Products>
<Products diffgr:id="Products2" msdata:rowOrder="1"
diffgram:hasErrors="true">
<ProductID>SFCHEESE001</CustomerID>
<productname>Soft Cheese</productname>
<price format="dollar">79.99</price>
<expirydate>01/01/2003</expirydate>
</Products>
<Products diffgr:id="Products3" msdata:rowOrder="2">
<ProductID>HLCHEESE001</CustomerID>
<productname>Holee Cheese</productname>
<price format="dollar">49.99</price>
<expirydate>01/12/2003</expirydate>
</Products>
</ProductsDataSet>
Below is the Diffgr section:
<diffgr:before>
<Products diffgr:id="Products1" msdata:rowOrder="0">
<ProductID>SMCHEESE001</CustomerID>
<productname>Smelly Cheese</productname>
<price format="dollar">150.99</price>
<expirydate>01/01/2009</expirydate>
</Products>
</diffgr:before>
<diffgr:errors>
<Products diffgr:id="Products2" diffgr:
Error="Optimistic concurrency violation.">
</Products >
</diffgr:errors>
</diffgr:diffgram>
In the sample DiffGram above, you should note that the price for Smelly Cheese has changed from $150.99 to $100.99. This is probably because this product does not sell very well. Also, Soft Cheese caused an error with the message “Optimistic concurrency violation.” This could probably be due to the fact that the record for Soft Cheese has changed since it was last retrieved from the database.
With ADO .NET, you can create a DataSet from an XML source and an XML document from a DataSet. You have great flexibility with how the data is read and the XML document is created.
The ReadXml method of the DataSet object is used to fill it with data from an XML data source.
The following table describes the ReadXml method:
|
Method |
Description |
|---|---|
|
ReadXml |
Filling the DataSet with data from an XML data source takes two arguments: the XML data source and an optional XmlReadMode. The data source can be a file, a stream, or an XmlReader object. |
The following table describes the values that XmlReadMode can have:
|
XmlReadMode |
Description |
|---|---|
|
Auto |
This is the default value. ReadXml examines the XML source and chooses the most appropriate option according to the following rules: |
|
ReadSchema |
Reads any inline schema and loads the data and schema in the DataSet. If the DataSet already contains a schema, new tables are added to the existing schema from the inline schema. If any tables in the inline schema already exist in the DataSet, an exception is thrown. |
|
IgnoreSchema |
Loads data onto the DataSet using the existing schema and ignoring any inline schema. Any data that does not conform to the schema is discarded. If the DataSet does not contain any schema, no data is loaded. If the data is a DiffGram, IgnoreSchema has the same functionality as DiffGram. |
|
InferSchema |
Ignores any inline schema, infers the schema from the structure of the XML data, and then loads the data. If the DataSet contains a schema, it is extended by adding new tables where there is no existing table or adding columns to existing tables. If an inferred table already exists with a different namespace or if any inferred columns conflict with existing columns, ReadXml throws an exception. |
|
DiffGram |
Reads a DiffGram and adds the data to the current schema. It merges new rows with existing rows using the unique identifier values to match rows. |
|
Fragment |
Reads multiple XML fragments until the end of the stream is reached. Fragments that match the DataSet schema are appended to their respective table. Any other fragments are discarded. |
ReadXml processes DTD schema differently. If the data source contains entries defined in a DTD schema and the data source is specified as a filename, a stream, or a non-validating XmlReader, ReadXml throws an exception. For XML data with DTD entries, you must first create an XmlValidatingReader object with the EntityHandling property set to ExpandEntities, and then use it as the data source to ReadXml. XmlValidatingReader will expand the entities before it is read by the DataSet.
We have seen how XML documents can be used as a data source for a DataSet. The DataSet can also generate XML data from the data and schema it contains. The XML can be generated with or without its schema. If you included schema information inline, then XML Schema Definition (XSD) language is used. The schema contains table definitions, relations, and constraints.
The following table describes the methods that you can use to write XML:
|
Method |
Description |
|---|---|
|
GetXml |
Returns the XML in a string and does not take any arguments. Only the data is returned. To get the schema, you must use the GetXmlSchema method. |
|
GetXmlSchema |
Returns the XML schema in a string and does not take any arguments |
|
WriteXml |
Writes the XML document on the specified data target, which takes two arguments. The first is the data target, and the second is an optional XmlWriteMode. The data target can be a stream, a file, or an XmlWriter object. |
As with ReadXml, WriteXml allows you great flexibility in how the XML document is created in the data target. When XML data is written from a DataSet, only the current version of the rows are written. You can, if you wish, specify that the data should be written as a DiffGram. This way, both original and current values for the rows are included.
The following table describes the values that XmlWriteMode can have:
|
XmlWriteMode |
Description |
|---|---|
|
IgnoreSchema |
This is the default value. The DataSet writes the XML data without an XML schema. |
|
WriteSchema |
Writes the current contents of the DataSet as XML with the relational structure as inline XML Schema |
|
DiffGram |
Writes the XML as a DiffGram, including original and current values of rows |
You can also specify how a column of a table is written in XML by changing the ColumnMapping property of the DataColumn object. The following table shows the different MappingType values that the ColumnMapping property can have and the effect on the output XML.
|
MappingType |
Effects on Output XML Data |
|---|---|
|
Element |
This is the default property value. The column is written as an XML element. The ColumnName is the name of the element, and the value of the current row for the column is written as the text, e.g., <ColumnName>Column Contents row</ColumnName>. |
|
Attribute |
The column is written as an XML attribute for the current row. The ColumnName is the name of the attribute, and the contents of the column are written as the value. |
|
SimpleContent |
The column contents are written as text in the XML element for the current row. You cannot use SimpleContent for columns of a table that have other columns set as element or have nested relations. |
|
Hidden |
The column is ignored and not written to the XML output. |
The ColumnMapping property is also used when writing the XML Schema of the DataSet.
The schema of a DataSet can be defined, just like its tables, columns, relations, and constraints. You can write this schema in XML Schema Definition (XSD) language. The XML Schema can be generated and transported with the data in an XML document, or it can be generated separately to a data target. A data target can be a file, a data stream, a string, or an XmlWriter object. The ColumnMapping property can be used, just as with XML, to specify how a table is represented in the XML Schema.
To write the schema, the WriteXmlSchema and GetXmlSchema methods of the DataSet are used. GetXmlSchema simply returns the schema in a string. It does not take any arguments. The WriteXmlSchema method requires one argument specifying the data target.
...
' Declare System.IO.StreamWriter
Dim xmlSW As System.IO.StreamWriter = _
New System.IO.StreamWriter("ProductsWriter.xsd")
' Write DataSet XML Schema to a file
ProductDS.WriteXmlSchema("ProductsFile.xsd")
' Write DataSet XML Schema to a StreamWriter
ProductDS.WriteXmlSchema(xmlSW)
' Close StreamWriter
xmlSW.Close()
' Write XML schema in a string
Dim XSDStringSchema As String = ProductDS.GetXmlSchema()
...
The generated XML Schema is also useful for generating typed DataSets. For more information about typed DataSets, please refer to the next section. The DataSet, along with late-bound access to values through weakly typed variables, provides access to data through strongly typed metaphors. This allows tables and columns, which form part of the DataSet, to be accessed using user-friendly names and strongly typed variables.
A typed DataSet is a class that is inherited from a DataSet. As well as inheriting all the methods, events, and properties of a DataSet, a typed DataSet also provides strongly typed methods, events, and properties in relation to the schema. This means that you can access columns by name instead of using collection-based methods. Using typed DataSets has the following advantages:
Development of a typed DataSet
Allows you to extend the power of the DataSet by overriding its methods or giving them more polymorphic behaviors
Enhances the readability of code
Makes use of Visual Studio .NET IntelliSense features (automatically completes codes as you type)
Catches type mismatch errors at compile time rather than at run time
From an XSD XML Schema, you can generate a strongly typed DataSet using the xsd.exe tool provided with the .NET Framework SDK.
The syntax for using xsd.exe is shown here:
xsd.exe /d /l:C# XSDSchemaFileName.xsd
/n:XSDSchema.Namespace
/d instructs xsd.exe to generate a DataSet, and /l: defines what language to use (C#, in this case). /n: is optional and instructs xsd.exe to also generate a namespace (in this case, XSDSchema.Namespace). The source file for the schema is defined as XSDSchemaFileName.xsd, and the output code will be in a file called XSDSchemaFileName.cs. Note that the extension will depend on the language used. The generated code can also be compiled as a module or library and used in an ADO .NET application.
The DataSet provides you with a relational view and access to data. The XML classes available in the .NET Framework provide you with a hierarchical view and access to data. Historically, the two models have been used separately. In the .NET Framework, you can have real-time synchronous access to both. The relational model represented by DataSet objects can be synchronized with the hierarchical model represented by XmlDataDocument objects.
Once a DataSet is set to synchronize with an XmlDataDocument, both objects, in effect, are sharing a single set of data. Changes made through one object are automatically reflected real-time in the other object. The ability to share data between the DataSet and the XmlDataDocument gives great flexibility by allowing access to services built around DataSet (such as Web Forms and Windows Forms controls) and XML services (such as XML Schema Definition (XSD) language, Extensible Stylesheet Language (XSL), XSL Transformations (XSLT), and XML Path Language (XPath)) all with one set of data.
You have different options from which to choose to synchronize a DataSet with an XmlDataDocument.
The first option you have is to populate a DataSet with relational data and schema and then synchronize it with a new XmlDataDocument. This option provides a hierarchical view to existing relational data sources.
' Create a DataSet
Dim aDataSet As DataSet = New DataSet
'*-------------------------------------------------------*
'* Add code here to populate DataSet with schema and data*
'*-------------------------------------------------------*
' Create XmlDataDocument and link it to a DataSet
Dim xmlDataDoc As XmlDataDocument = New
XmlDataDocument(aDataSet)
The other option is to populate a DataSet with XML Schema (which can generate a strongly typed DataSet), synchronize it with an XmlDataDocument, and then load the XmlDataDocument from an XML data source, such as an XML document. This provides the reverse option, which is a relational view to existing hierarchical data sources. The name of the tables and columns in the DataSet schema must match the names of the XML elements that you want to synchronize with. The matching is case-sensitive, and non-matching elements are ignored. This allows you to have a relatively small relational window view of part of a large XML document. While XmlDataDocument will preserve the whole XML document, only a portion of it (the portion you need) will be exposed through the DataSet.
' Declare and create the DataSet
Dim aDataSet As DataSet = New DataSet
'*-------------------------------------------------------*
'* Add code here to populate the DataSet with schema only*
'*-------------------------------------------------------*
' Create XmlDataDocument and link it to a DataSet
Dim xmlDataDoc As XmlDataDocument = New
XmlDataDocument(myDataSet)
' Load the XmlDataDocument with XML data
xmlDataDoc.Load("anXMLDocument.xml")
| Note |
You cannot load an XmlDataDocument if it is synchronized with a DataSet that contains data. In such a case, an exception will be thrown. |
So far, the options have been DataSet-centric; that is, you start from the DataSet first. A third option is XmlDataDocument-centric. You create a new XmlDataDocument and load it from an XML data source. You then access the relational view of the data using the DataSet property of the XmlDataDocument. As with the other options, the schema of the DataSet is important. The table and column names in the schema must match the names, in a case-sensitive manner, of the XML elements with which you want to synchronize.
' Create XmlDataDocument
Dim xmlDataDoc As XmlDataDocument = New XmlDataDocument
' Create the DataSet and link it to the XmlDataDocument
Dim aDataSet As DataSet = xmlDataDoc.DataSet
'*-------------------------------------------------------*
'* Add code here to populate the DataSet with schema *
'*-------------------------------------------------------*
' Load the XmlDataDocument with XML data
xmlDataDoc.Load("anXMLDocument.xml")
If the DataSet is populated from an XML data source using ReadXml, the returned XML using WriteXml may differ considerably from the original. The main reason is that DataSet does not maintain formatting, such as white spaces, or hierarchical information (remember that DataSet stores relational information), such as element order. The DataSet will also not contain elements that do not conform to the schema in the DataSet. This situation may not be a problem if you are only interested in the data, but if fidelity with the original XML document is required, then synchronization will maintain fidelity with the XML data source. Hierarchical element structure of the XML data source is maintained by XmlDataDocument, while at the same time allowing the required part of the data to be accessed through DataSet.
Results of synchronization between a DataSet and an XmlDataDocument may differ, depending on whether or not the DataRelation objects are nested.
In ADO .NET DataSet, relationships between tables are maintained and represented by the DataRelation. The parent-child relationships of columns are managed solely through relations. The tables and columns, as far as the DataRelation is concerned, are separate entities. In the hierarchical XML representation of data, the parent-child relationships are represented by nested child elements within parent elements. To facilitate nested relationships when a DataSet is synchronized with an XmlDataDocument, or even when XML is written through WriteXml, the DataRelation has a nested Boolean property with a default value of False. Setting the Nested property to True causes the child rows to be nested within the parent column when outputting XML data or synchronizing with XmlDataDocument.
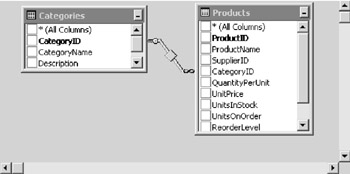
Consider the following figure and the tables’ relation in the Northwind sample database included with MS SQL 2000:
Now consider the following console application:
Imports System
Imports System.Xml
Imports System.Data
Imports System.Data.SqlClient
Module Module1
Sub Main()
' Establish connection to the database
Dim nwindConn As SqlConnection = _
New SqlConnection("Data Source=localhost;" & _
"Integrated Security=SSPI;Initial _
Catalog=Northwind;")
'Define a data adapter for category
Dim categoryDA As SqlDataAdapter = _
New SqlDataAdapter("SELECT CategoryID, _
CategoryName FROM Categories", nwindConn)
Dim productDA As SqlDataAdapter = _
New SqlDataAdapter("SELECT ProductID, _
CategoryID," & " ProductName, UnitPrice _
FROM Products", nwindConn)
'Open Database connection
nwindConn.Open()
'Create data set to hold data
Dim catDS As DataSet = New DataSet
("CategoryProducts")
'Populate DataSet with data from the two tables
categoryDA.Fill(catDS, "Categories")
productDA.Fill(catDS, "Products")
'Close connection
nwindConn.Close()
'Create the relationship between the two tables
Dim catProdcutRel As DataRelation = _
catDS.Relations.Add("catProdcut", _
catDS.Tables("Categories").Columns _
("CategoryID"), catDS.Tables _
("Products").Columns("CategoryID"))
'Write data as XML
catDS.WriteXml("NotNestedRelation.XML")
'Set Nested to true
catProdcutRel.Nested = True
'Write data as XML
catDS.WriteXml("NestedRelation.XML")
End Sub
End Module
Since the default for the Nested property of the DataRelation object is False, the child elements are not nested within the parent elements. The following code is generated in the NotNestedRelation.XML file.
<?xml version="1.0" standalone="yes"?>
<CategoryProducts>
...
<Categories>
<CategoryID>4</CategoryID>
<CategoryName>Dairy Products</CategoryName>
</Categories>
<Categories>
<CategoryID>5</CategoryID>
<CategoryName>Grains/Cereals</CategoryName>
</Categories>
<Categories>
<CategoryID>6</CategoryID>
<CategoryName>Meat/Poultry</CategoryName>
</Categories>
...
<Products>
<ProductID>2</ProductID>
<CategoryID>1</CategoryID>
<ProductName>Chang</ProductName>
<UnitPrice>19</UnitPrice>
</Products>
<Products>
<ProductID>3</ProductID>
<CategoryID>2</CategoryID>
<ProductName>Aniseed Syrup</ProductName>
<UnitPrice>10</UnitPrice>
</Products>
<Products>
<ProductID>4</ProductID>
<CategoryID>2</CategoryID>
<ProductName>Chef Anton's Cajun
Seasoning</ProductName>
<UnitPrice>22</UnitPrice>
</Products>
...
</CategoryProducts>
Both elements, Categories and Products, in the NotNestedRelation.XML file are siblings. However, in the NestedRelation.XML file, the Nested property of the DataRelation object is set to True. The XML output in the NestedRelation.XML file is different than that output in NotNestedRelation.XML file. The following code is generated in the NestedRelation.XML file:
<?xml version="1.0" standalone="yes"?>
<CategoryProducts>
<Categories>
<CategoryID>1</CategoryID>
<CategoryName>Beverages</CategoryName>
<Products>
<ProductID>1</ProductID>
<CategoryID>1</CategoryID>
<ProductName>Chai</ProductName>
<UnitPrice>18</UnitPrice>
</Products>
<Products>
<ProductID>2</ProductID>
<CategoryID>1</CategoryID>
<ProductName>Chang</ProductName>
<UnitPrice>19</UnitPrice>
</Products>
...
</Categories>
<Categories>
<CategoryID>2</CategoryID>
<CategoryName>Condiments</CategoryName>
<Products>
<ProductID>3</ProductID>
<CategoryID>2</CategoryID>
<ProductName>Aniseed Syrup</ProductName>
<UnitPrice>10</UnitPrice>
</Products>
<Products>
<ProductID>4</ProductID>
<CategoryID>2</CategoryID>
<ProductName>Chef Anton's Cajun
Seasoning</ProductName>
<UnitPrice>22</UnitPrice>
</Products>
...
</Categories>
...
</CategoryProducts>
As you can see, Products is now a child element of Categories.
For the most part, DataSet works mainly from the point of view that the source of the data is relational, and from this, we generate the XML data and schema. However, the DataSet can also do the reverse; that is, generate the relational schema from XML Schema (XSD) or even infer the schema from the XML data.
In general, a table is generated for each complexType child element nested in a complexType element in the XSD schema. The structure of the table depends on the definition of the complex type. The parent complexType element usually defines the DataSet itself. If the complexType element is further nested inside another complexType element, the nested complexType element will also generate a table and will be mapped to a DataTable object within the DataSet. This usually happens when there are nested relations.
Consider the following XSD schema:
<?xml version="1.0" standalone="yes"?>
<xs:schema id="CategoryProducts"
xmlns=""
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:msdata="urn:schemas-microsoft-com:xml-msdata">
<xs:element name="CategoryProducts"
msdata:IsDataSet="true">
<xs:complexType>
<xs:choice maxOccurs="unbounded">
<xs:element name="Categories">
<xs:complexType>
<xs:sequence>
<xs:element name="CategoryID"
type="xs:int"
minOccurs="0" />
<xs:element name="CategoryName"
type="xs:string"
minOccurs="0" />
<xs:element name="Products"
minOccurs="0"
maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="ProductID"
type="xs:int"
minOccurs="0" />
<xs:element name="CategoryID"
type="xs:int"
minOccurs="0" />
<xs:element name="ProductName"
type="xs:string"
minOccurs="0" />
<xs:element name="UnitPrice"
type="xs:decimal"
minOccurs="0" />
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:choice>
</xs:complexType>
<xs:unique name="Constraint1">
<xs:selector xpath=".//Categories" />
<xs:field xpath="CategoryID" />
</xs:unique>
<xs:keyref name="catProdcut"
refer="Constraint1"
msdata:IsNested="true">
<xs:selector xpath=".//Products" />
<xs:field xpath="CategoryID" />
</xs:keyref>
</xs:element>
</xs:schema>
With this schema, two tables will be created:
Categories(CategoryID, CategoryName) Products(ProductID, CategoryID, ProductName, UnitPrice)
The type of each column is converted to the appropriate .NET data type. The XSD schema also causes constraints and relations to be created.
Constraints are used to specify restrictions on elements and the values they can hold in any instance of the document. For example, if you specify the key constraint on CategoryID child element of the Categories element in the schema, the values of CategoryID in any document instance must be unique and cannot be Null. With XSD schemas, constraints are specified with elements and attributes. The common constraints used are:
Uniqueness defined by the unique element
A key specified by the key element
A reference key specified by the keyref element
With the unique element, you can also specify msdata attributes:
msdata:ConstraintName, where the value is used as the constraint name. Otherwise, the name attribute provides the value of the constraint name.
msdata:PrimaryKey: If the value is true, the constraint is created in the DataSet with the IsPrimaryKey property set to True.
...
<xs:unique name="Constraint1"
msdata:ConstraintName="UCatID"
msdata:PrimaryKey="true">
<xs:selector xpath=".//Categories" />
<xs:field xpath="CategoryID" />
</xs:unique>
...
The mapping process creates a unique constraint on the CategoryID column, as shown in the following DataSet:
DataSetName: CategoryProducts
TableName: Categories
ColumnName: CategoryID
AllowDBNull: False
Unique: True
ConstraintName: UCatID
Type: UniqueConstraint
Table: Categories
Columns: CategoryID
IsPrimaryKey: True
You can, however, have unique elements where msdata:PrimaryKey="false." In such a case, AllowDBNull will be True, meaning the column value needs to be unique or Null.
With the key element, you can also specify the same msdata attributes as with the unique element. The main difference is that with the key element, the AllowDBNull property in the DataSet constraint is always set to False. The IsPrimaryKey property depends on the value of the msdata:PrimaryKey attribute.
| Note |
Compound keys can be specified by adding another <xs:field/> element for each additional column in the key. |
With the keyref element, you establish relationships between elements in the document analogous to foreign keys in the relational data model. When mapping occurs, a foreign key is generated in the corresponding table in the DataSet and, by default, a relation, with the ParentTable, ChildTable, ParentColumn, and ChildColumn properties specified, is generated. The keyref element does not have the msdata:PrimaryKey attribute but can have additional msdata attributes:
msdata:ConstraintOnly: If the value is True, only a constraint is created in the DataSet; otherwise, both constraint and relation are created.
msdata:UpdateRule: Sets the UpdateRule constraint property to this value if specified; otherwise, the UpdateRule property is set to “Cascade.”
msdata:DeleteRule: Sets the DeleteRule constraint property to this value if specified; otherwise, the DeleteRule property is set to “Cascade.”
msdata:AcceptRejectRule: Sets the AcceptRejectRule constraint property to this value if specified; otherwise, the AcceptRejectRule property is set to “None.”
msdata:IsNested: Sets the IsNested relation property to this value if specified; otherwise, the IsNested property is set to “False.”
...
<xs:keyref name="catProdcut"
refer=" UCatID"
msdata:IsNested="true">
<xs:selector xpath=".//Products" />
<xs:field xpath="CategoryID" />
</xs:keyref>
...
The above will yield the following foreign key on the Products table:
ConstraintName: catProdcut Type: ForeignKeyConstraint Table: Products Columns: CategoryID RelatedTable: Categories RelatedColumns: CategoryID
There are three ways that DataSet relationships are specified in XSD:
By inference in nested complex types
Through msdata:Relationship annotation
Through an xs:keyref element without the msdata:ConstraintOnly attribute or with the msdata:ConstraintOnly value set to False
Nested complex types indicate a parent-child relationship, which was the case between Categories and Products in our previous example. We also have already seen keyref elements, so we will move on to msdata:Relationship in the annotation element.
...
<xs:annotation>
<xs:appinfo>
<msdata:Relationship name="CustomerProductRelation"
msdata:parent="Categories"
msdata:child="Products"
msdata:parentkey=" CategoryID"
msdata:childkey=" CategoryID"/>
</xs:appinfo>
</xs:annotation>
...
The above produces about the same result as the keyref example. However, the values of the constraint are not set. These are values, such as IsPrimaryKey and AllowDBNull, that you need to set using the constraint elements.
In certain situations, you might end up with an XML document that does not contain any inline schema nor is it one provided in a separate file. The DataSet can, however, still generate a schema from the XML document by analyzing the basic structure of the XML and inferring the schema.
The first step in the inference process is to determine the tables. ADO .NET first determines which elements represent tables. The remaining XML columns and relations are inferred. This is done by the following inference rules:
Elements that have attributes are inferred as tables.
Elements that have child elements are inferred as tables.
Elements that repeat are inferred as a single table.
Root elements with no attributes and no child elements inferred as columns are inferred as a DataSet. Otherwise, the root element is inferred as a table.
Attributes are inferred as columns.
Non-repeating elements with no attributes or child elements are inferred as columns.
Elements inferred as tables that are nested within other elements also inferred as tables cause a nested DataRelation to be inferred between the two tables. A primary key column named "TableName_Id" is inferred, added to both tables, and used by the DataRelation. A ForeignKeyConstraint is also inferred between the two tables using the "TableName_Id" column.
When elements are inferred as tables that contain text but have no child elements, a new column named "TableName_Text" is inferred for the text of each of the elements.
The inference process, however, is non-deterministic. Different instances of the same XML document intended to have the same schema can generate different schemas.
Consider:
<RootElement> <AnElement>a text value</AnElement> <AnElement>another text value</AnElement> </RootElement>
This infers DataSet: RootElement, table: AnElement because AnElement element is repeating.
Now consider:
<RootElement> <AnElement>a third text value</AnElement> </RootElement>
This infers DataSet: NewDataSet, table: RootElement, column: AnElement because AnElement element does not have attributes, is not repeating, and has no child elements.