| [ Team LiB ] |
|
5.2 Data ReplicationMicrosoft has introduced a number of new terms for Active Directory replication, and most of them will be completely unfamiliar to anyone new to Active Directory. To properly design replication, you need to understand how replication works, but more to the point, you need to understand how replication works using these new terms, which are used throughout both Microsoft's documentation and its management tools. Here is the list of the terms you'll encounter as we explain replication. These definitions will make more sense later.
5.2.1 A Background to MetadataData That Governs the Replication ProcessActive Directory replication enables data transfer between NCs on different servers without ending up in a continuous replication loop or missing any data. To make this process work, each NC holds a number of pieces of information that specifically relate to replication within that particular NC. So the replication data for the Schema NC is held in the Schema NC and is separate from the replication data for the Configuration NC, which is held in the Configuration NC.
5.2.1.1 The High-Watermark Vector and orginating/replicated updatesEach server has a separate Update Sequence Number (USN) for each NC. The USN is stored as a 64-bit value in the Active Directory database and is indexed for rapid searching. This value is used to indicate how many updates have actually taken place to an NC on a particular server and is known as the High-Watermark Vector. Each server also maintains a record of the updates that it made to its NC for a particular USN. This allows other servers to request individual changes based on particular USNs. Replication distinguishes between two types of update:
So if you use the Active Directory Users and Computers snap-in to create five users on Server A, Server A's USN is incremented five times, once for each originating update. If Server A receives six more changes from Server B, Server A's USN is incremented six more times, once for each of the six replicated updates.
To summarize, each server in a forest holds at least three NCs (Domain, Configuration, and Schema), and each of these has a High-Watermark Vector USN. 5.2.1.2 High-Watermark Vector tableEach server also maintains a list of the High-Watermark Vectors for all its replication partners. This table is updated only during replication. If we have a server with two partners, each partner maintains the High-Watermark Vector for my server. If a change occurs on my server, the High-Watermark Vector on my server is updated, but the High-Watermark Vectors on my partners are not updated until the next replication cycle. 5.2.1.3 Up-To-Date VectorEach server also maintains the USN that represents the last originating write for the NC on itself. This is known as the Up-To-Date Vector. If the USN on a server for a particular NC was 2000, and the server made an originating write to that NC, both the High-Watermark Vector and the Up-To-Date Vector USN would become 2001. If, subsequently, the server received five replicated writes, the Up-To-Date Vector would stay at 2001, while the High-Watermark Vector would become 2006. Obviously, if a server never has an originating write, the Up-To-Date Vector USN is never set for that server. 5.2.1.4 Up-To-Date Vector tableEach server also maintains a list of the Up-To-Date Vectors for every server that has ever made an originating write. This is known as the Up-To-Date Vector table. If Server A makes an originating write, it creates an Up-To-Date Vector for itself and adds it to the Up-To-Date Vector table. When it next replicates with all of its partners, it passes its Up-To-Date Vector table to those partners. The highest originating write value for a server is thus passed around to all servers in an NC.
As the tables have to uniquely identify the server in addition to the USN, each entry in both sets of tables stores the GUID of the server along with the USN value. 5.2.1.5 RecapThe following list summarizes the important points of this section:
While each server has a GUID, so does the Active Directory database (NTDS.DIT). This latter GUID is used to identify the server's Active Directory database in replication calls. The GUID is initially the same as the server GUID but changes if Active Directory is restored on that server.
5.2.2 How an Object's Metadata Is Modified During ReplicationTo see how the actual data is modified during replication, consider a four-stage example:
This four-step process is shown in Figure 5-1. The diagram depicts the status of the user object on both Server A and Server B during the four time periods that represent each of the steps. Now use Figure 5-1 to follow a discussion of each of the steps. Figure 5-1. How metadata is modified during replication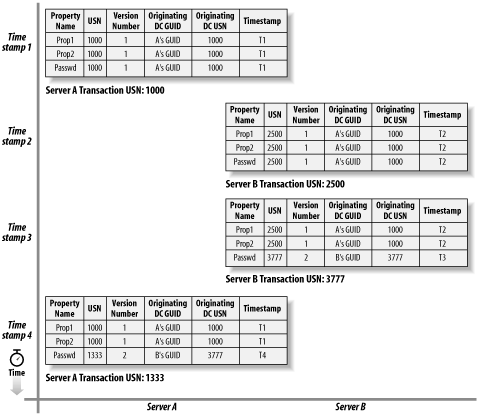 5.2.2.1 Step 1Initial creation of a user on Server AWhen you create a user on Server A, Server A is the originating server. During the Active Directory database transaction representing the creation of the new user on Server A, a USN (1000) is assigned to the transaction. The user's uSNCreated and uSNChanged properties are automatically set to 1000 (the USN of the transaction corresponding to the user creation). All of the user's properties are also initialized with a set of data as follows:
This tells you that the user was created during transaction 1000 on this server (uSNCreated = 1000). It also tells you that the user was last changed during transaction 1000 (uSNChanged = 1000). You know that the properties for the user have never been modified from their original values (property version numbers = 1), and these values were set at transaction 1000 (property's USN = 1000). Finally, you know that each property was last set by the originating server Server A during transaction 1000 (originating-server GUID and originating-server USN). The preceding example showed two per-object values and five per-property values being changed. While uSNChanged and uSNCreated are real properties on each object in AD, properties of an object can only have values and cannot hold other properties, like a version number. In reality, all of the per-property replication metadata (Property Version Number, Time-Changed, Originating-DC-GUID, Originating-USN, Property-USN) for every property of any object is encoded together as a single byte string and stored as replPropertyMetaData, a nonreplicated property of the object.
5.2.2.2 Step 2Replication of the originating write to Server BLater, when this object is replicated to Server B, Server B adds the user to its copy of Active Directory as a replicated write. During this transaction, USN 2500 is allocated, and the user's uSNCreated and uSNChanged properties are modified to correspond to Server B's transaction USN (2500). This tells you that the user was created during transaction 2500 on this server (uSNCreated = 2500). It also tells you that the user was last changed during transaction 2500 (uSNChanged = 2500). You know that the properties for the user have never been modified from their original values (property version numbers = 1), and these values were set at transaction 2500 (property's USN = 2500). Finally, you know that each property was last set by the originating server Server A during transaction 1000 (originating-server GUID and originating-server USN). 5.2.2.3 Step 3Password change for the user on Server BNow an originating write (a password change) occurs on Server B's replicated-write user. Some time has passed since the user was originally created, so the USN assigned to the password change transaction is 3777. When the password is changed, the user's uSNChanged property is modified to become 3777. In addition, the password property (and only the password property) is modified in the following way:
Looking at the user object, you can now see that the object was last changed during transaction 3777 and that that transaction represented a password change that originated on Server B. 5.2.2.4 Step 4Password change replication to Server AThis step is similar to Step 2. When Server A receives the password update during replication, it allocates the change transaction a USN of 1333.
During transaction 1333, the user's uSNChanged property is modified to correspond to Server A's transaction USN. This tells you that the user was created during transaction 1000 on this server (uSNCreated = 1000). It also tells you that the user was last changed during transaction 1333 (uSNChanged = 1333). You know that all but one of the properties for the user have retained their original values (property version numbers = 1), and these values were set at transaction 1000 (property's USN = 1000). Finally, you know that all but one of the properties were last set by the originating server Server A during transaction 1000 (originating-server GUID and originating-server USN). The password was modified for the first time since its creation (password version number = 2) during transaction 1333 (password's USN = 1333), and it was modified on Server B during transaction 3777 (originating-server GUID and originating-server USN). That's how object and property metadata is modified during replication. Let's now take a look at exactly how replication occurs. 5.2.3 The Replication of a Naming Context Between Two ServersIn the following examples, there are five servers in a domain: Server A, Server B, Server C, Server D, and Server E. It doesn't matter what NC they are replicating or which servers replicate with which other servers (as they do not all have to inter-replicate), because the replication process for any two servers will be the same nonetheless. Replication is a five-step process:
5.2.3.1 Step 1Replication with a partner is initiatedReplication occurs between only two servers at any time, so let's consider Server A and Server B, which are replication partners. At a certain point in time indicated by the replication schedule on Server A, Server A initiates replication for a particular NC with Server B and requests any updates that it doesn't have. This is a one-way update transfer from Server B to Server A. No new updates will be passed to Server B in this replication cycle, as this would require Server B to initiate the replication. Server A initiates the replication by sending Server B a request to replicate along with five pieces of important replication metadata, i.e., data relating to the replication process itself. The five pieces are:
The maximum object updates and property values are very important in limiting network bandwidth. If one server has had a huge volume of updates since the last replication cycle, limiting the number of objects replicated out in one go means that network bandwidth is not inordinately taken up by replicating those objects in one huge sweep. Instead, the replication is broken down into smaller chunks over multiple replication cycles. This step is illustrated in Figure 5-2, which shows that while the initiation of the replication occurs from an NC denoted as xxxx on Server A (where xxxx could represent the Schema, the Configuration, or any domain), the actual replication will occur later from Server B to Server A. High-Watermark Vector is abbreviated as HWMV and Up-To-Date Vector as UTDV. Figure 5-2. Initiating replication with Server B for NC xxxx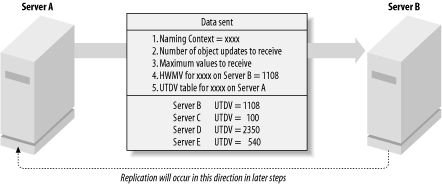 5.2.3.2 Step 2The partner works out what updates to sendServer B receives all this metadata and works out which updates it needs to send back for this NC. First, Server B finds its own High-Watermark Vector for its copy of the NC and then compares the two High-Watermark Vectors. Assuming that there have been some updates, Server B instantly knows how many updates have happened since Server A last replicated with Server B. This has to be true, as Server A would have been updated with Server B's High-Watermark Vector during the last replication cycle. So, any difference between the two vectors now must represent changes on Server B since the last replication, and Server B knows which individual USNs Server A is missing. Assuming also for now that the number of updates does not exceed the maximums specified by Server A in its metadata, Server B can supply all of the missing updates to Server A. However, this entire set of updates may not need to go to Server A if Server A has had some of them replicated already from other servers. Server B now needs some way of knowing which updates Server A has already seen, so that it can remove those items from the list of updates to send. That's where the Up-To-Date Vector table comes in. For each update that could potentially be sent, Server B checks two pieces of data attached to the object that was updated: the GUID of the server that originated the update (the Originating-DC-GUID) and the USN associated with that update on the originating server (the Originating-USN). For example, a password change to a user may have been replicated to Server B and recorded as USN 1112, but it may in fact have originated on Server D as USN 2345. Server B cross-references the originating server's GUID with Server A's Up-To-Date Vector table to find Server A's Up-To-Date Vector for the originating server. If the Up-To-Date Vector recorded in the table for the originating server is equal to or higher than the USN attached to the update on Server B, Server A must have already seen the update. This has to be true, because Server A's Up-To-Date Vector table is used to indicate the highest originating-writes that Server A has received. Let's say that Server B has four updates for Server A: one originating write (Server B USN: 1111) and three replicated writes (Server B USNs 1109, 1110, and 1112). The reason there are four is that 1112 is the last update made on Server B in this example, and Server A's HWMV for xxxx on Server B from Figure 5-1 is 1108. So, look for updates starting at 1109 up to the last update on Server B, which is 1112. The first two replicated writes (Server B USNs 1109 and 1110) originated on Server E (Server E USNs 567 and 788), and one (Server B USN 1112) originated on Server D (Server D USN 2345). This is shown in Table 5-1.
According to Figure 5-2, Server A already has Server D's 2345 update because Server A's Up-To-Date Vector for Server D is 2350. So, both Server A and Server B already have Server D's 2345 update, and there is no need to waste bandwidth sending it over the network again. The act of filtering updates that have already been seen to keep them from being continually sent between the servers is known as propagation dampening. Now that you know how the High-Watermark Vector table and Up-To-Date Vector table help Server B to work out what updates need to be sent, let's look at the exact process that Server B uses to work out what data is required. When Server B receives a request for updates from Server A, it starts by making a copy of its Up-To-Date Vector table for Server A. Having done that, it puts the table to one side, so to speak, and does a search of the entire NC for all objects with a uSNChanged value greater than Server A's High-Watermark Vector for Server B. This list is then sorted into ascending uSNChanged order. Next, Server B initializes an empty output buffer to which it will add update entries for sending to Server A. It also initializes a value called Last-Object-USN-Changed. This will be used to represent the USN of the last object sent in that particular replication session. This value is not an attribute of any particular object, just a simple piece of replication metadata. Server B then enumerates the list of objects in ascending uSNChanged order and uses the following algorithm for each object:
During the enumeration, if the requested limit on object update entries or values is reached, the enumeration terminates early and a flag known as More-Data is set to true. If the enumeration finishes without either limit being hit, then More-Data is set to false. 5.2.3.3 Step 3The partner sends the updates to the initiating serverServer B identifies the list of updates that it should send back based on those that Server A has not yet seen from other sources. Server B then sends this data to Server A. In addition, if More-Data is set to false, one extra piece of metadata is sent back as well. The returned information from Server B is:
This is shown in Figure 5-3. Figure 5-3. Server B sends the updates to Server A for NC xxxx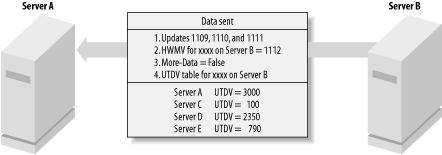
5.2.3.4 Step 4 The initiating server processes the updatesServer A receives the data. For each update entry it receives, Server A allocates a USN and starts a database transaction to update the relevant object in its own copy of the Active Directory database. If this update represents a change to an object (rather than an object deletion, for example), the object's uSNChanged property is set to the USN of this transaction. The database transaction is then committed. This process continues for each update entry that was received. After all the update entries have been processed, Server A's High-Watermark Vector for Server B is set to the Last-Object-USN-Changed received from Server B. In other words, Server A now knows that it is up to date with Server B, up to the last change just sent over. The Last-Object-USN-Changed that Server A receives allows it to know the last update that Server B has made. This will be used in the next replication cycle. In the previous example, the highest update sent across to Server A is USN 1111. Server B's USN 1112 update is not actually sent since Server A has already seen it. However, the Last-Object-USN-Changed returned by Server B with the data would still be 1112 and not 1111. 5.2.3.5 Step 5The initiating server checks whether it is up to dateServer A now checks the More-Data flag. If More-Data is set to true, Server A goes back to step 1 to start replication with Server B again and request more updates. If More-Data is set to false, every update must have been received from Server B, and finally Server A's Up-To-Date Vector table is itself updated. The Up-To-Date Vector table allows Server A to identify which updates Server B has seen and thus by replication which updates it has now seen. Server A does not replace its Up-To-Date Vector table with the one it was sent. Instead, it checks each entry in the received table and does one of two things. If the entry for a server is not listed in its own Up-To-Date Vector table, it adds that entry to its own table. This allows Server A to know that it has now been updated to a certain level for a new server. If the entry for a server is listed in Server A's Up-To-Date Vector table, and the value received is higher, it modifies its own copy of the table with the higher value. After all, it has now been updated to this new level by Server B, so it had better record that fact. Table 5-2 shows Server A's Up-To-Date Vector table and High-Watermark Vector for the xxxx Naming Context before Step 1 and after Step 5.
5.2.3.6 RecapThe following main points summarize replication between Naming Contexts:
5.2.4 How Replication Conflicts Are ReconciledWhile the replication process is fine on its own, there are times when conflicts can occur because two servers perform irreconcilable operations between replication cycles. For example, Server A creates an object with a particular name at roughly the same time that Server B creates an object with the same name. Both can't exist at the same time in Active Directory, so what happens to the two objects? Does one get deleted or renamed? Do both get deleted or renamed? What about an administrator moving an object on Server D to a new Organizational Unit while at the same time on Server B that Organizational Unit is being deleted? What happens to the soon-to-be orphaned object? Is it deleted along with the Organizational Unit or moved somewhere else entirely? Consider a final example: if an admin on Server B changes a user's password while the user himself changes his password on Server C, which password does the user get? All of these conflicts need to be resolved within Active Directory during the next replication cycle. The exact reconciliation process and how the final decision is replicated back out depend on the exact conflict that occurred. 5.2.4.1 Conflict due to identical property changeIn this case, the server starts reconciliation by looking at the version numbers of the two properties. Whichever property has the higher version number wins the conflict. If the property version numbers are equal, the server checks the timestamps of both properties. Whichever property was changed at the later time wins the conflict. If the property timestamps are equal, the originating server GUIDs are checked for both properties. As GUIDs must be unique, these two values have to be unique, so the server arbitrarily takes the property change from the originating server with the higher GUID as canon. 5.2.4.2 Conflict due to a move of an object under a now deleted parentThis is a fairly easy conflict to resolve. In this case, the parent is deleted, but the object is moved to the Lost and Found Container, which was specially set up for this scenario. The ADsPath of the Lost and Found Container for Mycorp is: LDAP://cn=LostAndFound,dc=mycorp,dc=com 5.2.4.3 Conflict due to creation of objects with names that conflictThe server starts reconciliation by looking at the version numbers of the two objects. Whichever object has the higher version number wins the conflict. If the object version numbers are equal, the server checks the timestamps of both objects. Whichever object was changed at the later time wins the conflict. If both object timestamps are equal, the originating server GUIDs are checked for both objects. The server simply takes the object change from the originating server with the higher GUID as canon. In this case, however, the object that failed the conflict resolution is not lost or deleted, but is renamed with a unique value. That way, at the end of the resolution, both objects exist, with one having its conflicting name changed to a unique value. The unique name consists of the following format: <DEFANGED_ObjectName<LineFeed>CNF:<DEFANGED_ObjectGUID>. 5.2.4.4 Replicating the conflict resolutionLet's say that Server A starts a replication cycle. First it requests changes from Server B and receives updates. Then Server A requests changes from Server C and receives updates. However, as Server A is applying Server C's updates in order, it determines that a conflict has occurred between the updates recently applied by Server B. Server A resolves the conflict according to the preceding guidelines, and finds in Server C's favor. Now, while Server A and Server C are correct, Server B still needs to be updated with Server C's value. To do this, when Server B next requests updates from Server A, it receives, among others, the update that originated on Server C. Server B then applies the updates it receives in sequence, and when it gets to the update that originated on Server C, it detects the same conflict. Server B then goes through the same conflict resolution procedure that Server A did and comes to the same result. Server B then modifies its own copy of the relevant NC to accommodate the change. Additional problems occur when changes are made on a server and it goes down prior to replicating the changes. If the server never comes back up to replicate changes, those changes are lost.
|
| [ Team LiB ] |
|
