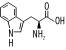| [ Team LiB ] |
|
2.1 The Central Dogma of Molecular BiologyMost courses in molecular biology begin with the Central Dogma of Molecular Biology, which describes the path by which information contained in DNA is converted to protein molecules with specific functions. Stated simply, the Central Dogma is: "from DNA to RNA to protein." Figure 2-1 shows a more complete diagram of this process and will be referenced throughout this section. Figure 2-1. The Central Dogma of Molecular Biology: DNA to RNA to protein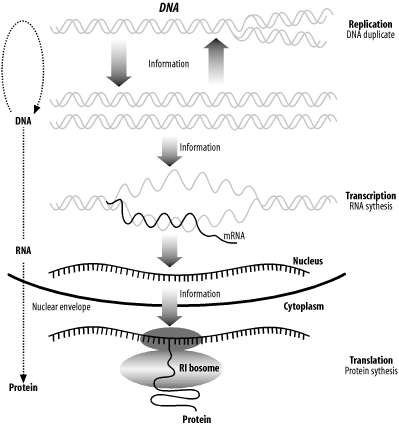 2.1.1 DNAThe hereditary material that carries the blueprint for an organism from one generation to the next is called deoxyribonucleic acid. It is much more commonly referred to by its acronym, DNA. Every time cells divide, the DNA is duplicated in a process called DNA replication. The entire DNA of an organism is called its genome, and genomes are sometimes called "the book of life" (especially with respect to the human genome). Reading and understanding the various books of life is one of the most important quests of the genomic age. Modern medicine, agriculture, and industry will increasingly depend on an intimate knowledge of genomes to develop individualized medicines, select and modify the most desirable traits in plants and animals, and understand the relationships among species. The language of DNA is complicated. Over the last 50 years, scientists have begun to decipher it, but it is still largely a mystery. Although the language is elusive, the alphabet is simple, consisting of just four nucleotides: adenine, cytosine, guanine, and thymine. For simplicity in both speech and on the computer, they are usually abbreviated as A, C, G, and T. DNA usually exists as a double-stranded molecule, but we generally talk about just one strand at a time. Here's an example of a DNA sequence that is six nucleotides (nt) long: GAATTC DNA has polarity, like a battery, but its ends are referred to as 5-prime (5´) and 3-prime (3´) rather than plus and minus. This nomenclature comes from the chemical structure of DNA. While it isn't necessary to understand the chemical structure, the terminology is important. For example, when people say "the 5´ end of the gene," they mean the beginning of the gene. We usually display DNA sequence as we read text, left to right, and the convention is that the left side is the 5´ end and the right side is the 3´ end. In addition to the 4-letter alphabet, there is also a 15-letter DNA alphabet used to describe nucleotide ambiguities (Table 2-1). The most common noncanonical DNA symbol is N, which stands for an unknown nucleotide. Other common ones include R and Y.
The pairing rule of DNA is that A pairs with T, and C pairs with G. It is very easy to determine the sequence of the complementary strand of any DNA sequence. In double-stranded form, the 6 base pairs (bp) of DNA above looks like this: GAATTC CTTAAG In this example, if you read the bottom strand backward, it is the same as the top strand read forward. Such palindromes are often of biological interest. This particular one is the recognition site for an enzyme called EcoRI that cuts DNA at this sequence. This is an example of how information can be gleaned simply from analyzing the primary sequence. Palindromes and other patterns often give clues to the function of small stretches of DNA. But why is DNA double stranded? The answer is because the molecule is chemically more stable that way, and the double-stranded structure also allows some error correction if a base is accidentally damagedfor example by UV irradiation from too much sunlight. (This is a good reason to wear sunscreen.) DNA by itself doesn't do much. It's just a storehouse for information. For the computer scientists in the audience: think of the genome as a hard disk with RAID mirroring that stores A's, C's, G's, and T's instead of 1s and 0s. Before we continue with the Central Dogma, we'll discuss genes. What is a gene? Like many complicated problems, this is a question for which five experts would give you six different answers. For our purposes, a gene is a functional unit of the genome (a purposefully vague definition). Most genes contain instructions for producing proteins at a certain time and in a certain space. Some genes have very narrow windows of activity, while others are ubiquitous. Not all genes code for proteins, however. Some genes produce RNAs that aren't translated into proteins and are therefore called noncoding RNAs (ncRNA). So we've already deviated from the Central Dogma. Molecular biology is filled with rules that are constantly violated. (In fact, that's one of the first rules!) Molecular biology is also filled with names and acronyms that may be new to you. To help you keep track of them, this book includes most of them in the Glossary. 2.1.2 RNAAs mentioned earlier, DNA doesn't do much on its own. The excitement starts when DNA is copied into RNA by a protein called RNA polymerase in a process called transcription. Chemically, RNA is a lot like DNA except that it uses uracil instead of thymine and is single stranded instead of double stranded. The RNA alphabet is A, C, G, and U, and an RNA molecule might look like this: GAAUUC What happens to the RNA transcript from a gene? If it is a transfer RNA (tRNA), ribosomal RNA (rRNA), or other ncRNA, it may undergo some chemical modifications, but the gene product remains as an RNA molecule. RNAs corresponding to protein coding genes are called messenger RNAs (mRNA). 2.1.3 ProteinProteins make up the "buildings" and "machines" inside a cell. They are chemically very different from DNA and RNA because they are composed of amino acids (often abbreviated aa) rather than nucleic acids. Proteins have a useful property: they can fold into very specific three-dimensional shapes that are dependent on their amino acid sequences. Thus, the amino acid sequence determines the shape of the protein and the shape determines the function. A protein shaped like a stiff rod may be used as a structural support. Collagen and keratin are such proteins and make skin and hair durable. A protein with a hook may be used as a part of a ratcheting motor. A good example of this is myosin, which is found in muscle cells. Therefore, while DNA and RNA are largely used to store and send information, proteins make things happen. The protein alphabet commonly contains 20 symbols, A, C, D, E, F, G, H, I, K, L, M, N, P, Q, R, S, T, V, W, and Y. The names, abbreviations, and structures of the amino acids are shown in Table 2-2.
Using one-letter symbols, a protein sequence might be written like this: MLVGSRA Like DNA and RNA, proteins also have polarity, and the nomenclature comes from the chemical structure. Here again, the convention is to display the sequence from left to right. In proteins, the left end is called the N-terminus and the right end is called the C-terminus. Thus, when people say, "the N-terminus is often removed after translation," they're talking about the beginning of the protein. Remember that all proteins start with the amino acid methionine (M). This is another of the universal laws of molecular biology, and like all biological laws, it is occasionally violated. The sequences of proteins are one-dimensional, but their shapes are three-dimensional, or four-dimensional if you take into account that they're not frozen in time and can change their shape depending on their environment. It's worth remembering because most of this book talks about proteins as one-dimensional sequences and not shapes, and this approximation is frequently at odds with reality. Let's take a brief sojourn into protein folding and structure to see why this is. First, just to make sure you get your daily dose of jargon, the sequence of amino acids is called the 1° structure of the protein (this is read as "primary structure," not "1st degree"). Proteins in aqueous solution usually have a globular structure; that is, they aren't sprawled out all over the place but adopt a compact structure. How do they get this way? Many proteins fold into their final structure by themselves because it represents the "easiest" shape they can adopt. But some proteins need a little help, and they receive assistance from other proteins in the cell called chaperones. Amino acid chemistry is beyond the scope of this chapter, but note that amino acids can be classified as hydrophobic ("fears water") or hydrophilic ("likes water"). Hydrophobic amino acids are like oils: they don't mix well with water and prefer to clump together in blobs rather than disperse. When a protein folds, the hydrophobic parts tend to aggregate. This creates a globular structure in which the inside is composed of hydrophobic amino acids, and the exterior is composed of hydrophilic amino acids. Of course, the complete story is much more complicated, but this provides a convenient way to think about protein folding and structure. Although proteins come in many different shapes and sizes, if you look closely at the structure, you can find recurring structural themes that biologists call 2° (secondary) structure. The most common themes are the a-helix, b-sheet, and random coil. In Figure 2-2, these themes are represented as cylinders, arrows, and squiggly lines. Figure 2-2. Structure of immunoglobulin domain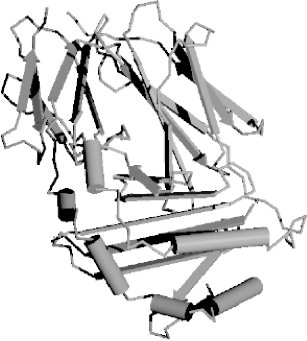 2.1.4 The Genetic CodeHow is the information in DNA and RNA translated to protein sequence? A complex machine composed of proteins and ncRNAs called the ribosome reads an mRNA sequence and writes a protein sequence. The mRNA is read three nucleotides at a time. The nucleotide triplets are called codons. Each codon corresponds to a single amino acid. The mapping from codons to amino acids is called the genetic code, and its discovery is one of the great achievements in molecular biology. The genetic code is one of the universal laws of molecular biology (and, as you should expect, is sometimes broken). Because codons are three nucleotides long and there are four possible nucleotides at each position, it follows that there are 64 (43) possible codons. However, there are only 20 amino acids. Thus there is redundancy in the genetic code and in turn, the code is often described as degenerate. Figure 2-3 shows the standard nuclear genetic code (there are more than a dozen different genetic codes, mostly from different mitochondrial genomes). If you look closely at the redundancies, you will find patterns. For example, the third position of a codon is often insignificant; A, C, G, or T all lead to the same translation. When this isn't the case, A and G are usually synonymous, as are C and T. It so happens that A and G belong to the same chemical class, called purines, and C and T belong to another class, called pyrimidines, so this makes sense in a biochemical way. There are other neat patterns, such as any codon with a T in the middle translates to a hydrophobic amino acid. In addition to the amino acids, there are three stop codons. When a ribosome sees a stop codon, translation terminates, and the protein is released to go about its business. As mentioned before, all proteins start with the amino acid methionine. This has only one codon, ATG, and so ATG is often called the start codon. Figure 2-3. Standard codon translation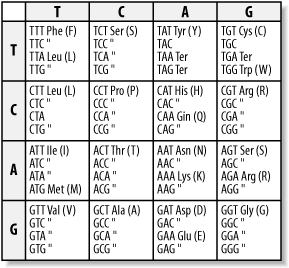 Consider the following nucleotide sequence. TTTATATCACAC If you translate this from the first letter, you get the protein sequence: FISH But what if you translate it from the second nucleotide? You get a different protein sequence (note that the fractional codon AC at the end of the DNA translates to threonine no matter what the next nucleotide is): LYHT Because codons are three nucleotides long, you can translate DNA in three different reading frames. Since DNA is double stranded, there are really six reading frames for every piece of DNA. So if someone hands you a DNA sequence and asks you to translate it, you may have a little trouble. |
| [ Team LiB ] |
|