|
|
< Day Day Up > |
|
6.2 Tools for ExtensionWhen I worked at a startup called AllMyStuff, we researched reporting tools. We wanted a tool that our users could drop into our framework and report on data that we gathered. We wanted to be able to work the reports into our user interface and we wanted the tool to use our existing data structures. Sales reps from various companies all said, "No problem. Our framework is completely extensible." As you might expect, that wasn't the case. Of course, we wanted to extend the reporting tools in a variety of ways. Some of the extensions were minor. We needed the product to support our customers' databases. Most supported JDBC and all supported major database vendors. In other cases, we wanted to extend the reporting packages in ways that the original designers had not intended. We found that supporting a Java API was not nearly enough. We needed the user interface to live with ours without source code changes. We needed to integrate the security of the reporting package to the security of the application. We wanted our customers to be able to access extensions through configuration rather than coding changes. When you're planning to build an extensible framework in the Java environment, you've got an incredibly broad selection of tools to choose from. The continuum of techniques ranges from requiring massive, invasive change to nothing more than configuration changes. In Figure 6-3, I identify four types of extension based on the level of effort it takes to extend the framework. The hardestand most usefultype of extension to provide requires no code changes or installation. The application automatically recognizes the need to change and does the work. Norton Antivirus auto-update provides this type of support. The next-most stringent model requires only scripting or configuration. All other support is included or retrieved automatically. The next option, the plug-in, requires the user to provide and configure a compatible module. That's a very useful and common design for enterprise programming, and the one that will get most of our focus in this chapter. Finally, other modes of extension require coding changes. I won't spend as much time with these. The tools that you use to provide each type of support overlap but are different. Figure 6-3. Different models of extension place different burdens on the user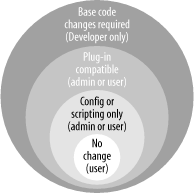 6.2.1 StandardsYour first tool is a clear understanding of the key standards that improve extension. Using these and exposing relevant configuration can give you an important head start. This is the paradox: by choosing standards, you will limit your own choices, but you'll dramatically improve the choices that your customers can make after deployment time. The most critical standards for you are external touch points, like user interfaces, databases, transactions, or communication. Table 6-1 shows some important standards that you may choose to support. If you need a service in one of these areas, consider the corresponding standard.
Be careful: remember, you are what you eat. If you choose EJB CMP because it's the most pervasive standard for persistence, you're completely missing the point of this book. Choose an implementation that works for you and works well. 6.2.2 ConfigurationConfiguration has long been the bane of Java developers everywhere. Most developers focus on reuse strategies that involve coding changes, such as introducing an API. If you're like most developers, you probably save configuration issues for the end of a projectbut if you don't want to force developers to handle all possible extensions, you must address configuration early. Many developers choose to write configuration libraries themselves because so many Java libraries and tools have been so poor for so long. Configuration problems have plagued J2EE as well. In the recent past, EJB, JNDI, and J2EE security have all had vastly different configuration strategies, formats, and models. Recent Java developers have faced these problems:
Recently, developers have learned more, and other options have surfaced that allow much better control. Although they're not perfect, there's a much broader set of choices. You can choose from several strategies. There are too many solutions to count, but at least three look promising:
Study every solution with the same diligence that you'd use for choosing any other major framework. Without effective configuration, your only option for extension is programming intervention. In this chapter, I look briefly at two possible solutions: the Java Preferences API and to a lesser extent, Apache Digester. 6.2.2.1 Client-side configuration with Java PreferencesThe standard Java API for configuration is the Java Preferences API. As you'll see, it's designed primarily for client-side use, but lightweight server-side applications may make some use of it as well. It's designed independently of the backend data store. It lets you store system level properties and properties for individual usersthus, then name Preferences. Preferences databases are stored in two different trees: one for the user and one for the system. Your primary window into a preferences data store is the node. You could decide to read the top node out of either preferences store, the system, or the user, but if you did so, different applications would potentially step on each other. The customary solution is to group preferences together under a package, as in Figure 6-4. You can get the top-level node for the user tree, for any given package, like this: Preferences node = Preferences.userNodeForPackage(getClass( )); Figure 6-4. The Preference API supports two different trees, for the user and the system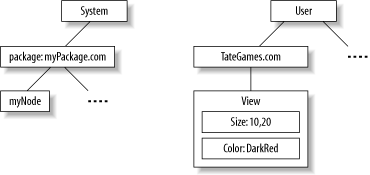 Then you can use the Preference API to load and save preferences. You can always create additional tree nodes to organize things further but for simple applications, just store preference properties directly at the package level. For example, to get the "BackgroundColor" preference to "White": node.putString("BackgroundColor", "White");Preferences are simply name-value pairs. The first parameter is the key and the second is the value of the preference. You can use Strings, other primitive types, or byte arrays. The Preference API does not support complex objects. You'll read a preference in much the same way. As you'd expect, you look up a preference by its key value. For example, to read the default high score for a game: node.getInt("HighScore", 0);Here, the first parameter is once again the key but the second is a default, just in case the backend data store is not available. By default, the data is stored in different places on different operating systems. The Windows system (Windows 2000 and beyond) uses the registry. The Linux version uses a file. You can also import or export a preference file as XML with exportSubtree and exportNode. Exporting a subtree includes children; exporting a node only exports a single level. For example, to dump the current user's node for a package: Preferences prefs = Preferences.userNodeForPackage(getClass( ));
FileOutputStream outputStream = new FileOutputStream("preferences.xml");
prefs.exportSubtree(outputStream);I haven't shown the whole API, but you have enough to get started. You may be wondering why the preferences may be appropriate for the client, but less so for the server. Here are the most important reasons:
If you want to use a configuration service for a more sophisticated server-side application, I recommend that you look beyond the properties and Preferences APIs. In the next section, you'll see a high-level overview of the solution used by many Apache projects. 6.2.2.2 Server-side configuration with Apache DigesterThe Apache project has a set of common Java utilities grouped into the Commons project. One of the tools, Digester, pareses XML files, helps map them onto objects, and fires rules based on patterns. It's helpful any time you need to parse an XML tree and especially useful for processing configuration files. Figure 6-5 shows how it works. You start with a configuration file, then add patterns and associated rules to Digester. When Digester matches a pattern, it fires all associated rules. You can use the prepackaged rules provided by Digester, or you can write your own. Figure 6-5. Apache's digester makes it easy to parse configuration files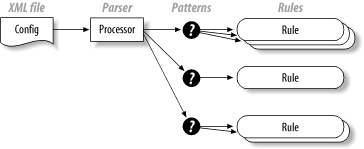 For the most part, you're going to want Digester to create objects that correspond to your configuration tree. You also might want it to do special things to your objects when it encounters them, like open a connection or register a data source. Here's how to process a configuration file with Digester:
myLogConfig = digester.parse( ); I like the Digester framework because it's simple and lets you create a transparent model for your configurationyou can separate the configuration from the configuration implementation. That means you're not lobbing DOM trees all over your application. 6.2.3 Class LoadingConfiguration lets administrators rather than programmers specify what an application should look like. Often, you'll want to allow the administrators to configure classes that you might not have anticipated when you build your application, or even classes that don't exist yet. In fact, that's the whole pointgiving the users the ability to extend a system in ways you might not foresee. It's called delayed binding. The problem with delayed binding is this: if you don't know the name of the class, you can't create it with a constructor. You'll need to load the class yourself or use a tool such as Spring or Digester that will do it for you. Fortunately, class loading and reflection give you enough horsepower to get the job done. Many developers never use dynamic class loading, one of the Java language's most powerful capabilities. It's deceptively simple. You just load a class and use it to instantiate any objects that you need. You're free to directly call methods that you know at compile time through superclasses or interfaces, or methods that you don't know until runtime through reflection. 6.2.3.1 Loading a class with Class.forNameSometimes, loading a class is easy. Java provides a simple method on Class called ForName(String className) that loads a class. Calling it invokes a class loader to load your named class. (Yes, there's more than one class loader. I'll get into that later.) Then, you can instantiate it using newInstance( ). For example, to create a new instance of a class called Dog, use the following lines of code: Class cls = Class.forName("Dog");6.2.3.2 Invoking methodsNow you've loaded a class; the next step is to use it. You've got several choices. First, you might invoke static methods on the class, like main. You don't need a class instance to do that. Invoking the main method looks like this: myArgs = ... Method mainMethod = findMain(cls); mainMethod.invoke(null, myArgs); Your next option is to create an instance and then call direct methods of known superclasses or interfaces. For example, say you know that you've loaded an Animal class or a class that supports the Animal interface. Further, Animal supports a method called speak, which takes no arguments. You can cast your new instance to Animal as you instantiate it. Understand that your class must have a default constructor that initializes your object appropriately, because you can't pass constructor arguments this way. Here's how you would create an instance of Animal and access its properties: Animal dog = (Animal)cls.newInstance( );
dog.setName("Rover");
dog.speak( );When I'm doing configuration of a service, I like to use the interface approach. An interface best captures the idea of a service. Other times, you're instantiating a refined concept, like a servlet (Tomcat) or component (EJB). For these purposes, subclasses work fine. Many Java services use a simple class loading and an interface or abstract class:
Your next option is to use reflection to access fields or call methods, as in Chapter 4. Using this technique, you'll need to know the name and signature of the method that you want to call. Remember, Java allows overloading (methods that have the same name but different signatures). For the most abstract configuration possible, you may well need reflection to invoke methods or access properties. For example, Hibernate and Spring both use configuration and reflection to access persistent properties. The Digester framework also uses reflection within many of its rules. All of these techniques depend on dynamic class loading to do the job. It's time to dive into some more details. 6.2.3.3 Which class loader?Java 2 recently added a lot of flexibility to the class loader. The changes also added some uncertainty. Here's how it works:
That sounds easy enough. The problem is that Java 2 supports more than one class loader, as shown in Figure 6-6. Three different hierarchies load three major types of files. The system loader loads most applications and uses the class path. The extension loader loads all extensions, and the bootstrap loader loads core Java classes in rt.jar. Figure 6-6. The Java 2 class loader has three major loaders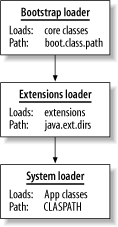 The Java runtime obviously needs special treatment. Since the Java runtime is not yet alive when it starts, Sun provides a basic bootstrap loader to load the Java runtime. It does not load any application logic at all. Only the most basic Java classesthose in rt.jarare loaded by the Bootstrap class loader. It doesn't have a parent. Many users complained that class paths were getting too long as the number of Java extensions grew. To simplify Java extensions, Sun provided an environment variable that pointed to a set of directories (specified in the environment variable java.ext.dirs) to hold all Java extensions. That way, when you want to add a service, like JNDI, you can just drop your .jar into Java's extensions directory. The system loader is often the loader that your applications will use. If you don't specify a loader and you are not a Java extension, you're likely going to get the system loader as your ultimate parent. The most important thing to keep in mind is that your classes may not have the same parent. If you're loading an extension, it may well use a different loader and check a different class path. If you're loading extensions from an application, for example, your class loader will have a different ancestor chain. You may have also run across similar problems when using applications like Tomcat or Ant, which rely on class paths and environment variables other than the CLASSPATH environment variable. You don't have to rely on luck. If you want to be sure that the new class will use the same class loader chain as your current thread, specify a class loader when you use Class.forName. You can get the context class loader for your current thread like this: cl=Thread.getContextClassLoader( ); You can even set the current thread's context class loader to any class loader you choose. That means all participants in the thread can use the same class loader to load resources. By default, you get the app class loader instance. The short version is that Class.forName(aName) usually works. If it doesn't, do a little research and understand which class loader you're using. You can get more details about class loading in an excellent free paper by Ted Neward at http://www.javageeks.com/Papers/ClassForName/ClassForName.pdf. Alternatively, some of the resources in the Bibiliography chapter of this book (Halloway, for instance) are outstanding resources. 6.2.4 What Should You Configure?After you've mastered the basics for configuration and class loading, consider what pieces of your applications need configuration. Several important decisions will guide you. 6.2.4.1 Fundamental conceptsThe first step in deciding what to configure is to understand the fundamental concepts involved. You might just use them as an aid to your planning or you might use them to help you organize your configuration implementation. After you've decided on the fundamental concepts of your system, begin to choose the ones that you'd like to try to configure. Chapter 3 emphasized the principle "Do one thing and do it well." For extensibility, the key is to keep orthogonal concepts separatenot just in code but in configuration. If you're working from a good design and a good configuration service, it will be easy to organize and expose the most critical services. Keep the code for individual concepts independent so you can consider each concept individually. For example, if you're considering your data layer, you may decide to expose your data source, a database name, a schema name, and your database authentication data. You may decide to separate your transaction manager, since that may be useful to your user base should they decide to let your application participate in an existing transaction. Keep the Inventor's Paradox in mind. It will help you separate important concepts in your configuration. You can often generalize a configuration option. The Spring framework discussed in Chapter 8 supports many examples of this. 6.2.4.2 External touch pointsAll applications access the outside world. You were probably taught very early in your career to insulate your view from the rest of your application. Often, you can get great mileage out of insulating other aspects of your application, as well. For example, you may link to proprietary applications that manage inventory, handle e-commerce, or compute business rules. In any of these instances, it pays to be able to open up the interface to an application. One of the most useful configuration concepts is to allow your customer to tailor external touch points. In order to do so, define the way you use your service. You don't always need to explicitly configure the service. You may instead decide to configure a communications mechanism for an XML message or wire into a standard such as a web service. The important thing is to allow others to use your application without requiring major revision. Whether you enable JMS or some type of RPC, you'll be able to easily change the way your clients communicate with your system. Frameworks like Spring handle this type of requirement very well. 6.2.4.3 External resourcesNearly all enterprise applications need resources. It's best to let your clients configure external services whenever they might need to change them. Data sources (especially those with connection pools), transaction monitors, log files, and RPC code all need customization, and it's best to do so from a central configuration service. Sometimes, configuring external touch points requires more than just specifying and configuring a service. Occasionally, you must build a custom architecture to plug in specialized services with special requirements. These types of services require an architecture called a plug-in. |
|
|
< Day Day Up > |
|