|
|
< Day Day Up > |
|
6.3 Plug-In ModelsMany applications that need to be extended use a model called a plug-in. Both web browsers and web servers use plug-ins to display specialized content. A plug-in is an application component that can be installed into an existing application and configured by nonprogrammers. These are the key elements of the plug-in:
Most applications hard-wire services to objects or components that use the service. You can't do that with a plug-in. The calling application needs to know to look for the plug-in without any compile-time knowledge about it. Let's put the Inventor's Paradox into practice and generalize the problem to include any service. 6.3.1 Plug-Ins at a Lower LevelYou can generalize the plug-in model to most configurable services. For example, think about a typical J2EE application with a data access object. For the DAO to work, you need to supply a data source. You probably don't want to create and manage the data source within the DAO because you've doubtless got other DAOs and you'd like them to work together. Within your application code, configure a data source and use it to get a connection. Your application code will then somehow get the connection to your DAO. Most developers choose a hard-wired approach:
Either way, you have a hardwired connection. The application code drives implementations of a DAO, data source, and connection (Figure 6-7). This approach is sound but limited. Figure 6-7. Some traditional J2EE applications have application logic that controls implementations of a DAO, a data source, and a connection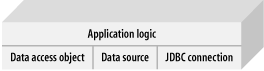 Both solutions have fundamental drawbacks. You must couple ideas that do not belong together. In this case, you couple the ideas of a data source, a connection, and a DAO together. You leave it to the application programmer to tediously manage and coordinate the resources. For example, the application needs to open and close connections appropriately. Further, the application is now hardcoded to use specific implementations of each of these three ideas. You need to change code to change the services that the application uses. Good developers solve this problem with one or two mechanisms: the service locator or dependency injection (also called inversion of control). Both approaches work, but one does a better job of insulating configuration and extension from the developer. 6.3.1.1 Service locatorsThe most common J2EE solution is to add a layer of abstraction called a service locator. As you've probably seen, this design pattern lets you register a data source in a hash table, database, or other data store. Applications combine the managing code to find and configure it into a single service called the service locator. Service providers can implement similar services at the interface level so that users can potentially replace like services with less impact. This idea does save some of the administrative burden and decouple your application from other concepts. But instead of completely decoupling the concepts, the burden simply shifts to a different componentbecause the application must still register services with the locator. This design pattern is the fundamental driver behind JNDI. As with most design patterns, the service locator is a workaround for limitations within J2EE. It's an often-cumbersome way of solving the problem that relies on code rather than configuration, which is potentially limiting. 6.3.1.2 Inversion of controlAnother possibility is an inversion of control container. Figure 6-8 shows the implementation. You can have the application programmer code an individual Java bean for the DAO and identify key services. The programmer identifies necessary services and specifies individual fields for those services, such as a data source. The programmer can then build a configuration file, describing how to create and populate individual instances. The configuration file resolves dependencies at that time through data provided in the configuration file. For example, the DAO needs a data source, which it can query for a connection. The assembler reads the configuration file and creates a data source and a DAO, then wires them together simply by using Java reflection to set a parameter. You can see why many people prefer the term dependency injection to inversion of control. Figure 6-8. Lightweight inversion of control containers relieve applications of creation and assembly of objects.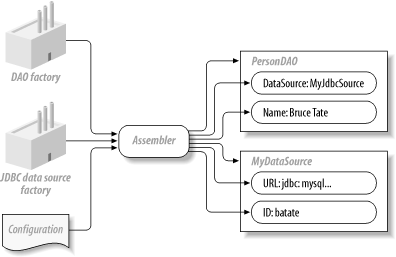 Keep in mind that the inversion of control container does do some work for you, but your objects can live without it. This capability comes in handy as you build test cases. For example, to test the application in Figure 6-8, create a data source and provide it to your DAO manually. Your bean doesn't depend on an individual data source or on Spring. The end result is a decoupled object that's easy to code, test, extend, and use. 6.3.2 The Role of InterfacesInterfaces play a critical role in this design philosophy. You can treat each service (or resource) as an interface. If a bean uses a resource, it relies on an interface rather than a base class with inheritance. You can then configure it to use any bean that implements that interface. If this isn't clear to you, think of the metaphor that gave the plug-in its nameelectrical appliances. A description of the plug is an interface (it has a positive and negative lead and a ground, for instance). You can build applications (appliances), or sockets (services), based on the interface. The applicationsuch as an electric drillimplements the interface as a plug. You can now use the appliance with any socket that supports that interface. In the same way, you can use a different service with any application that supports the interface. To take it one step further, a skilled person can take:
Given these building blocks, that person could use the instruction manual to wire the appliances together for use in hotels around the world. That's the role of dependency injection. It takes a configuration file (the instruction manual) and inserts plugs (Java beans implementing interfaces) into sockets (typed fields of applications that code to that interface). |
|
|
< Day Day Up > |
|