| [ Team LiB ] |
|
10.1 Transaction ManagementHere's a common situation that arises in enterprise development: you need to perform a set of actions as if they were a single action.[1] In real life, the simplest transactions take place within one resource, such as a database, and within a very short period of time. A bank transaction implemented by changing values for a particular field in two different rows of a table, via two update statements executed one after the other, is a simple transaction. You don't want to record the value of one update without the other. Even if the chance of something interferingmoney automatically being deducted to pay a bill between the two updates, for instanceis small, it's a chance that can't be taken. To make life even more exciting, the odds of something going wrong increase dramatically when you start coordinating the transaction across space (multiple databases, messaging systems, EJBs, etc.) and time (multiple user requests to a web application).
Complex activities call for complex transactions. Let's take the ubiquitous stock-trading system example: for a brokerage firm to execute a buy order, it must charge a user's account, execute the trade, and send various confirmation messages. The confirmation messages shouldn't be sent without the trade, the account shouldn't be charged without the trade, and the trade shouldn't be executed without confirmations being sent. Each activity in the chain might involve a different system or technology, yet the entire process needs to be treated as one concrete business activity. Each activity might also consist of a subtransaction; for example, charging an account involves checking for sufficient funds and then transferring funds to a different account. 10.1.1 About TransactionsA transaction is an activity that changes the state of a system in a particular way. The purpose of formalized transaction management is to make sure that a system is altered in a manner that ensures the underlying state of the system is always valid. A transaction, therefore, is made up of a series of operations that result in a valid change of a system's state. The simplest use for transactions is for preventing incomplete operations. If an activity calls for two SQL statements to run, enclosing them in a transaction ensures that either both run, or neither; if the second statement fails, the entire transaction will be rolled back, undoing the effects of the first statement. If each SQL statement succeeds, the transaction will be committed, permanently updating the state of the systems. The other benefit of using a transaction is to ensure that the overall view of the system is always in a consistent state, even when multiple transactions are in process. Without proper transactions, even if every activity completes successfully, an application faces three subtle threats: dirty reads, nonrepeatable reads, and phantom reads. A dirty read occurs when two or more processes attempt to work on the same data at the same time. Imagine a transaction that reads two properties, A and B, from an object, performs a calculation, and updates a third property, C. If another transaction modifies A and B after the first transaction has read A but before it has read B, the computed value of C will not only be out-of-date, it may be entirely invalid! Figure 10-1 shows what can happen. Figure 10-1. Two transactions in conflict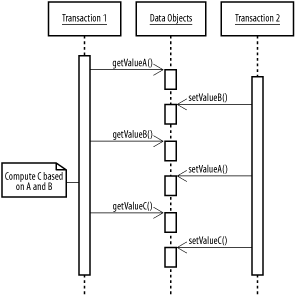 When the transactions are complete, the value of the C property on the data object has been computed based on the original A and the new value for B. This was never a valid value for C! The same problem can arise if you're using database tables rather than objects (and, in fact, that version of the problem happens more often; if nothing else, you can synchronize on an object). A nonrepeatable read is similar to a dirty read, in that the problem comes from two transactions working with the same data at the same time. In this case, the first transaction might read a table that is subsequently modified by another transaction. If the first transaction reads the table again, it finds a new value. The original read, therefore, is nonrepeatable: the transaction can execute the same query multiple times and receive different answers. The difference between a nonrepeatable read and a dirty read is that in a nonrepeatable read, the transaction that changes the data has completed. Systems can therefore allow nonrepeatable reads without also allowing dirty reads (in which the change becomes visible as soon as it is made within the transaction, rather than when the transaction is committed). Phantom reads occur when one transaction is reading data while another transaction is modifying the same data. For example, imagine a program runs an SQL SELECT statement to retrieve a set of rows from the database, and then runs the same statement again a few seconds later. If another process has subsequently inserted rows into the table, the second query will return rows that weren't present in the first query. Conversely, if rows are deleted by the other transaction, they won't show up on the second query. This is sometimes acceptable, but not always: since the same query returns different results, the application doesn't have access to a consistent view of the database in order to do its work. Phantom reads differ from nonrepeatable reads in that they deal with the presence of data altogether rather than the contents of the data being read. 10.1.2 ACID Transaction PatternWe've discussed two requirements of transaction management: performing multiple actions as one and ensuring the consistency of an underlying resource (generally a database). The ACID Transaction pattern defines four properties that can be used to implement a transaction. These four properties create a framework of operations that meets the needs we discussed in the previous section.[2]
A transaction that meets the ACID requirements is:
Transactions must be atomic because we want every action within the transaction to succeed or fail as a unit. If a transaction reserves inventory, charges a credit card, and ships the inventory, we want to make sure the reserved inventory is still available if the credit card charge fails. Transactions must be consistent because we need the state of the system to be correct after each activity. A system that has inventory reserved but no plans to ship it isn't in the correct state. The business rules within the domain model must be satisfied at the beginning and end of every transaction, regardless of whether the transaction succeeds. Saying a transaction is isolated means that the transaction in progress is invisible to other transactions until it has been committed. This property, in particular, ensures that the overall view of the database remains consistent. Each transaction is shielded from dirty, nonrepeatable, and phantom reads, ensuring that any data loaded from the underlying resources was valid at least at one point in time. Keep in mind that there's no guarantee that the data is still valid: if another transaction started and finished while the first transaction was still in effect, the first transaction may be working from an older, though possibly consistent, set of data. We'll look at strategies for dealing with this issue in the next section of this chapter. Finally, the durability property ensures that after a transaction is completed it will persist in the system. Of course, there's no absolute guaranteesomebody could take a sledgehammer to the database serverbut the result of the transaction will be visible to all subsequent transactions. 10.1.2.1 Transaction isolationPerfect transaction isolation is expensive. By allowing dirty reads, nonrepeatable reads, phantom reads, or some combination of the three, applications can reap greatly improved performance. It's not difficult to see why: avoiding these problems requires either keeping track of multiple versions of data, or requiring the system to delay some transactions until others have finished, or some combination of both. Some applications require perfect transaction isolation, but many, possibly most, don't. For performance reasons, applications often want to break the perfect isolation that a pure ACID transaction would enjoy. JDBC supports four transaction isolation modes (five if you count turning it off). They are, in order from least stringent to most stringent:
Of course, not all databases support each level. Oracle, for example, does not support the READ_UNCOMMITTED or REPEATABLE_READ isolation levels. Since isolation levels are set on a per connection level, it's possible to use different isolation levels across an application. Read-only SQL can use TRANSACTION_NONE; applications doing multipart updates that aren't likely to affect other transactions can use READ_COMMITTED; and data analysis activities that demand a consistent view can use SERIALIZABLE. 10.1.2.2 System and business transactionsVirtually any interaction with the domain model underlying an application can be represented as a transaction. Complex operations can be treated as a single transaction or split into several smaller transactions. When we write about transactions in design documentation, we often split them into system transactions and business transactions: the former approach is for the implementation details, and the latter is for the business modeling activity. Business transactions will be instantly recognizable to the end user: they include actions such as withdrawing money from an account, finalizing a purchase, or submitting an order. These transactions have fundamental constraints your application must abide by. Business transaction boundaries flow logically from your use cases and requirement specifications. Each business transaction is made up of one or more system transactions. A system transaction is implemented by the underlying resource layer, whether it's a database, EJB, messaging system, or something else. The tools for handling system transactions are provided by the Java APIs that access the particular infrastructure. Most programmers who've worked with database backends have been exposed to JDBC's transaction management API, which implements database level transactions. The following code shows how to use JDBC's transaction management support. This code fragment starts a transaction (by turning off automatic commits on the Connection), attempts to run two SQL statements, each of which modifies the database, and then commits the transaction after both statements have run. If either statement fails (as indicated by an SQLException), the transaction is rolled back. A finally block cleans up database objects and closes the connection, regardless of whether the transaction succeeded. Connection con = null;
Statement stmt = null;
PreparedStatement pstmt = null;
try {
con = dataSource.getConnection( ); // retrieve from a javax.sql.DataSource
con.setAutoCommit(false);
stmt = con.createStatement( );
stmt.executeUpdate("INSERT INTO VALUABLE_DATE (NUMVAL) VALUES (42)");
pstmt = con.prepareStatement("UPDATE VITAL_DATA SET DATA = ? WHERE ID=33");
pstmt.setString(1, "This is really important"");
pstmt.executeUpdate( );
// commit the transaction
con.commit( );
} catch (SQLException e) {
try {
con.rollback( );
} catch (SQLException se) {} // report this in severe cases
e.printStackTrace( ); // handle it better
} finally {
if(stmt != null)
try { stmt.close( ); } catch (SQLException ignored) {}
if(pstmt != null)
try { pstmt.close( ); } catch (SQLException ignored) {}
if (con != null)
try { con.close( ); } catch (SQLException e) {}
}
The details of the system transactions may be opaque to the end users. This is because many complex applications make a set of changes to a variety of resources, including multiple databases, messaging systems, and proprietary tools, in the process of fulfilling one user request. A business transaction, which maps much closer to a use case, is more recognizable to the end user, and may consist of several system transactions linked in various ways. One of the primary purposes of the EJB API was to blur the line between system and business transactions. EJBs make it easier to link system transactions involving multiple resources; in fact, the process is largely transparent to the programmer. A single call to a method on a session façade can start a system transaction that encompasses all of the activities within a business transaction, and includes multiple databases, messaging systems, and other resources. If we aren't using an EJB environment, we'll need to build business transactions out of multiple system transactions. If we're using two databases, we'll need a system transaction for each one. We'll also need system transaction resources for anything else we want to include in the transaction. The JMS API, for instance, includes a transaction management idiom that's similar to the one in JDBC: the JMS Session interface, which is analogous to the JDBC Connection interface, provides a commit( ) method and a rollback( ) method. A business delegate implementing a business transaction can start as many system transactions as it needs. If every transaction completes successfully, each system transaction is committed. If any transaction fails, your code can roll back all of them. 10.1.3 Transactions and ObjectsGraphs of objects are not naturally amenable to transactions. Unless transaction capability is baked into an environment at a very low level, capturing the web of relations between the different objects is very difficult. Modifying an object in a meaningful way often involves creating or destroying references to a variety of other objects. A single business transaction often creates or modify customers, orders, line items, stock records, and so on. Transaction control across a single object, however, is relatively easy. When you don't have to worry about dynamically including external objects in a transaction, it's a (relatively!) simple matter to record changes to objects. Databases don't face this problem because the relationships between tables are defined by key relationships (if you're not familiar with primary keys, turn back to Chapter 8). A transaction might include edits to five or six different tables in a database and those edits might affect the relations between entities, but as far as commits and rollbacks are concerned, the relationships don't matter. In the end, the application is ultimately responsible for maintaining the consistency of the data. Consistency can be maintained by declaring "constraints" on the database that disallow updates and inserts that don't meet a particular set of conditions, or by enforcing the business rules at the application logic level by forbidding entry of invalid or inappropriate data. The EJB specification provides transaction support at the object level by assigning a primary key to each entity bean. References between objects are handled not by direct Java references, but by the application server, using the keys. This method allows the application server to monitor each object for changes in internal state and changes in its relationship with other objects. Entity beans can be included in a running transaction as they are touched upon by application code. For example, an EJB stateless session bean can be declared as TX_REQUIRED, which requires the EJB container to create a transaction (or join an existing transaction) whenever a method is invoked on the bean. Initially, the transaction will not encompass any objects on the server. As code execution goes forward, any entity beans requested by the session bean will be included in the transaction. If the session bean method executes successfully, all of the changes will be committed to the system. If the method fails, any changes made to any transaction-controlled objects will be rolled right back. 10.1.4 Transactional Context PatternIn an EJB environment, transaction management is taken care of transparently. By setting transaction levels on session and entity beans and accessing database connections and other resources through the application server, you get most of your transaction support automatically. If a method on a session façade fails in mid-execution, all of the entity bean changes it made are undoneany JMS messages are unsent, and so on. If you're not running in an environment that handles transactions for you, you need to build them yourself. Since 95% or more of enterprise transaction management code involves the database, the standard approach is to use the transaction functionality that is built into the JDBC API and the underlying databases. Transactions can then be handled at the DAO level: each DAO method starts a new transaction, updates the database, and commits the transaction. Handling transactions at the DAO or PAO level, though, can be limiting. For one thing, the transaction boundary generally does not lie at the DAO level. Instead, transactions usually sit at the business delegate/session façade level. This level is, of course, the use case level. Since a business delegate might call several DAOs in the course of completing its activities, and might even call other business delegates, handling transactions at this level is not going to give us the degree of control we want: if the last DAO fails, the changes made by the first DAOs remain in the database, leaving the application in an inconsistent and incorrect state. The Transactional Context pattern allows us to spread a transaction across multiple, otherwise unrelated objects. A transactional context is an environment that business logic and data access components execute inside. It controls access to transaction control resources such as database connections, and is responsible for starting, stopping, committing, and rolling back transactions. As we stated, the EJB environment itself provides a transactional context, but if you're not using an application server, it's possible to write your own. For simple applications, the business delegate itself can serve as the transactional context for the DAO objects it uses. All the software really needs to do is decouple the DAO objects from the code to retrieve database connections from the application's connection pool. The business delegate can retrieve the connection itself, set up the transaction, and pass the same connection into a series of DAOs or other business delegates. As long as the DAOs don't call any transaction management code themselves (the JDBC setAutoCommit( ), commit( ), and rollback( ) methods), all activities against the database will be included in the same transaction. Failures at any point can be used to roll back the transaction for all the affected components. This approach works fine for simple activities and within DAOs, but it breaks down for larger scale applications. For one thing, the business delegate object is now aware of transaction management in all its gory (well, not too gory) details. It's perfectly appropriate for the business delegate to be aware of the business constraints surrounding a transaction, but less appropriate for it to be responsible for implementing them. If nothing else, the ability to easily switch back and forth between local business delegates and remote EJB session façades vanishes: the EJB specification specifically disallows independent transaction control. A more elegant implementation involves placing control of the transaction context with an outside object that is known to the business delegates, DAOs, and other components. Figure 10-2 shows how it works. Figure 10-2. Business delegate and DAOs using transactional context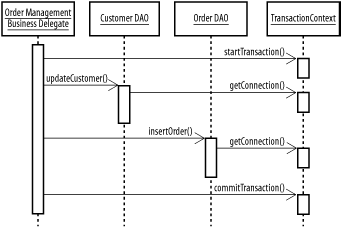 In this example, the business delegate informs the context control object that it wishes to start a transaction. The context object obtains a connection and starts the database transaction. It then passes the connection to any other object, such as the two DAOs, that have access to it. The DAOs use the connection, and their activities are included in the transaction. After calling all the DAOs it needs, the business delegate commits the transaction. 10.1.4.1 Implementing transactional context with business delegatesIn Chapter 9, we discussed business delegates and business delegate factories, and promised that we'd provide a way to easily integrate transactions without requiring a full EJB environment. Many applications are small enough to run in a simple web container such as Jakarta Tomcat. In these cases, where business logic is embedded in business delegates and DAOs, we need to manage our own transactions within business delegates. Our solution is to associate a database connection with a web application's request scope. When a request comes into the web server, we assign a single JDBC Connection object to support every database-related activity from the start of the request to the end of the request. This allows us to declare a transaction that spans multiple objects, which is similar to the behavior an EJB server would provide. This approach requires one decision: which level of the application should have knowledge and control of the transaction boundary? Earlier we placed this responsibility at the DAO level when dealing with DAOs in non-EJB environments. In this case, we need to put the responsibility at the business delegate or even the business delegate factory level. The first step is to provide an idiom for sharing a connection across multiple objects. This procedure might seem daunting, since it's easy to imagine having to pass connection references from object to object. In fact, it's pretty simple, at least in the servlet world. Since each servlet request takes place on its own thread, we can use Java's ThreadLocal class to build a static ConnectionManager object that can be associated with a particular request.[3] The connection manager provides part of our transactional context. Example 10-1 shows an implementation, which includes methods for setting and retrieving the current connection.
Example 10-1. ConnectionManager.javaimport java.sql.Connection;
public final class ConnectionManager
{
private static final ThreadLocal currentConnection = new ThreadLocal( );
static Connection setConnection( Connection connection ) {
Connection priorConnection = (Connection)currentConnection.get( );
currentConnection.set( connection );
// We return the prior connection, if any, to give the application
// the opportunity to deal with it, if so desired. It's important
// that all database connections be properly closed.
return priorConnection;
}
public static Connection getConnection( ) {
return (Connection)currentConnection.get( );
}
}
Once the connection has been set up, using the connection manager is easy: just call the getConnection( ) method when you need a connection. Unlike a JNDI connection pool, you don't call the close( ) method when you're done with the connection; the system does it for you (Example 10-2), so closing it prematurely just makes trouble for the next block of code that needs to use it. Here's a simple example of correct usage:[4]
Connection con = ConnectionManager.getConnection( );
try {
con.setAutoCommit(false);
// Do SQL
con.commit( );
con.setAutoCommit(true);
} catch (SQLException e) {
// Report somehow
// Rollback exception will be thrown by the invoke method
con.rollback( );
con.setAutoCommit(true);
}
The only rule is that you have to finish with the connection in the same scope you retrieved it: if you stash a reference to the connection in a place where it might be accessed by another thread, the other thread has no guarantee of the connection's transactional state or even validity. For example, if you retrieve the connection within a persistence method attached to a domain object, you can't cache that Connection object within the domain object for use later: if other methods need it, they must retrieve it from the ConnectionManager itself. The safest possible version of this strategy would wrap the connection in a wrapper object that simply passed all of the methods in the Connection interface through to the actual connection object, with the exception of the close( ) method. Now that we have the connection manager, we need to associate a connection with our thread. We do this via a servlet filter, shown in Example 10-2. The filter is responsible for interacting with a JNDI data source and opening and closing connections. Example 10-2. ConnectionFilter.javaimport java.io.IOException;
import javax.servlet.*;
import java.sql.*;
import javax.sql.*;
import javax.naming.*;
public class ConnectionFilter implements Filter {
private DataSource dataSource = null;
/**
* Create a datasource from a parameter defined in web.xml.
*/
public void init(FilterConfig filterConfig) throws ServletException {
try {
InitialContext iCtx = new InitialContext( );
Context ctx = (Context) iCtx.lookup("java:comp/env");
dataSource = (DataSource)
ctx.lookup(filterConfig.getInitParameter("JNDI_datasource"));
} catch (Exception e) {
ServletException se = new ServletException( );
// Uncomment in JDK 1.4 for easier troubleshooting.
// se.initCause(e);
throw se;
}
}
public void destroy( ) {
}
/** Retrieve a connection, run the filter chain, and return the connection.
* */
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
Connection con = null;
try {
con = dataSource.getConnection( );
// Set the connection, and retrieve the previous connection for
// disposal
Connection previousCon = ConnectionManager.setConnection(con);
if(previousCon != null)
try { previousCon.close( ); } catch (SQLException e) {}
// Run the rest of the filter chain.
chain.doFilter(request, response);
// Make sure we disassociate the connection, just in case.
ConnectionManager.setConnection(null);
} catch (SQLException e) {
ServletException se = new ServletException(e);
throw se;
} finally {
if (con != null)
try { con.close( ); } catch (SQLException e) {}
}
}
}
This approach has a side benefit, by the way: if your application needs a connection in several places during the course of a single request, using the ConnectionManager instead of repeated JNDI requests means less code and a slight performance boost. We could stop now that we have a connection manager associated with our threads. Each business delegate that wants a transaction that spans multiple DAOs or transactionally ignorant subdelegates can retrieve the connection, set the transaction status, run its code, and commit or roll back as appropriate. However, we've placed a lot of responsibility for implementing transactions on the business delegates, which is probably not a good thing. Instead, we can push responsibility all the way up to the business delegate factory, using the proxy approach introduced in Chapter 9. The TransactionWrapper class shown in Example 10-3 decorates an object with an InvocationHandler that wraps each method call in a transaction (again, see Chapter 9 for an introduction). Coupled with the ConnectionManager, we now have a complete transactional context implementation: a way of sharing the transaction environment and a way of controlling the transaction status. Example 10-3. TransactionWrapper.javaimport java.lang.reflect.InvocationHandler;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
import java.sql.Connection;
final class TransactionWrapper {
/**
* Decorates a business delegate object with a wrapper. The
* object returned by this method will implement all of the interfaces
* originally implemented by the target.
*
* @param The Business Delegate to wrap
* @return The business delegate wrapped in this wrapper
*/
static Object decorate(Object delegate) {
return Proxy.newProxyInstance(delegate.getClass().getClassLoader( ),
delegate.getClass().getInterfaces( ),
new XAWrapperHandler(delegate));
}
static final class XAWrapperHandler implements InvocationHandler {
private final Object delegate;
XAWrapperHandler(Object delegate) {
// Cache the wrapped delegate, so we can pass method invocations
// to it.
this.delegate = delegate;
}
/** Invoke the method within a transaction. We retrieve a connection,
* set auto commit to false (starting the transaction), run the original
* method, commit the transaction, and return the result. If any
* exceptions are thrown (SQLException or not) we roll the transaction
* back.
*
* Note that we don't use a finally block to reset the connection to
* autocommit mode. This approach gives us a better idea of the root
* cause of any error. In JDK 1.4, we might modify the catch block
* to attach the original Throwable as the root cause for any exception
* thrown by the rollback() and setAutoCommit( ) methods. */
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
Object result = null;
Connection con = ConnectionManager.getConnection( );
try {
con.setAutoCommit(false);
result = method.invoke(delegate, args);
con.commit( );
con.setAutoCommit(true);
} catch (Throwable t) {
// Rollback exception will be thrown by the invoke method
con.rollback( );
con.setAutoCommit(true);
throw t;
}
return result;
}
}
}
The final step is to modify our business delegate factory to wrap an object instance in a transaction wrapper, as we did in Chapter 9. If you've read the code closely, you'll see that we commit the database transaction after every method invocation. Proxy handlers wrap the object from the view of application, but not from within the object itself (unless you do some complicated passing of self-references, which is pretty hard to manage). So you don't need to worry about your methods spawning a new transaction for each internal method call. Figure 10-3 shows the chain of method invocations for a simple example: the application calls the getCustomer( ) method on the proxy object; the proxy object calls the invoke( ) method of our InvocationHandler, which in turn calls the original object. If the original object calls methods on itself, they won't be passed through the invocation handler. Figure 10-3. Application, invocation handler, and wrapped object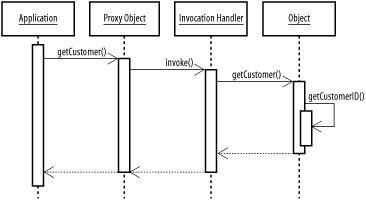 This behavior has two implications. First, we don't have to worry about the business delegate creating new transactions by calling its own methods, since those calls don't go through the proxy. Second, if we want to nest business delegates we must ensure that the nested delegates are not wrapped in the proxy when the parent delegate retrieves them. This may involve providing two different object creation methods on the business delegate factory: one to create a wrapped object that generates a new transaction with each method invocation, and one to create an unwrapped version that joins existing transactions. Nesting business delegates only comes up sometimes, but many, if not most, business delegates will call multiple DAO methods in the course of a single business delegate method. That's why we wrap at the business delegate level rather than the DAO level. |
| [ Team LiB ] |
|