| [ Team LiB ] |
|
11.7 Messaging and IntegrationFor the final section of this chapter, we're going to look at patterns that focus on integrating messaging into an enterprise environment. Of course, all of the patterns in this chapter affect integration to some degree. The Message Façade pattern, for instance, is sometimes known as a messaging adapter, allowing nonmessaging-aware applications to participate in message-based data exchanges. The patterns in this section focus on how to route messages between systems, and on what might be done with the content once they've arrived. 11.7.1 Pipes and Filters PatternMany applications involve multiple processing. For example, placing an order might require reserving stock at the warehouse, processing payment, and shipping. In a fully integrated enterprise, you might be able to do all of this in one system and at one time, but most companies aren't entirely integrated. Reserving stock might require someone to physically visit the warehouse, and payment processing might involve purchase order approvals or lengthy credit checks. In these cases, it makes sense to decouple the activities into separate components and connect them with messaging. The Pipes and Filters pattern allows us to link a set of message handlers (filters, in this parlance) via a series of pipes. The pattern itself is an old one,[6] and has been applied in a variety of contexts. Anyone who has "piped" the content of one program to another (cat textfile.txt | more, for example) should be familiar with the general concept. After each processing stage completes, the message is sent along another channel to the next handler in the sequence (Figure 11-8).
Figure 11-8. Message with intermediate processing By implementing each stage of the message handler activity as a separate process, you gain a lot of flexibility in the way the steps are performed. New functions can be inserted as additional filters without requiring major modifications. As with standalone message handlers, the individual components can be tested much more easily. And, in conjunction with the competing consumers pattern, you can parallelize the more time-consuming elements of message processing. If the payment phase requires dialing out on a modem, for instance, you can buy a few more modems and set up a few more payment servers to help speed up the process. Neither JMS nor JavaMail provides a simple mechanism to pass one message through a series of processing steps. Instead, each filter needs to pass the message on to the next filter in the sequence. The simplest way to implement this process is to provide each filter with its own channel. To prevent confusion, it's helpful to provide an external resource, such as a database or XML configuration file, that tells each filter where to send its output. The following XML describes a message chain for the order fulfillment example (you'll need to write your own code in order to parse and use it). All each filter needs to know to determine the next destination is its own name. New filters can be inserted into the XML wherever required. <messagechain name="orderfulfillment">
<filter name="reservation" queue="reservations"/>
<filter name="payment" queue="payment"/>
<filter name="shipping" queue="shipping"/>
</messagechain>
Look familiar? This is a messaging application of the Service to Worker pattern from Chapter 4. This technique also makes it easier to use a filter in multiple different pipes and filters chains. As long as the message contains the name of the pipes and filters sequence it's currently passing through, the individual steps can consult the XML to determine the next step for the appropriate chain (so the payment filter can pass to a shipping filter in one chain and a "build a widget" filter in another chain). To minimize queue profusion, you can also use the publish-subscribe pattern, and have all of the message handlers subscribe to a single queue (see the Competing Consumers pattern, above). Each handler implements a message selector that filters out all of the incoming messages that it doesn't support. Once the handler is done processing, it puts the message back on the queue for handling by the next step. Figure 11-9 shows an example. Figure 11-9. Message selector used to distribute messages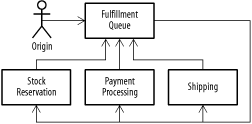 This approach works because JMS message selectors, when used with a queue, will leave all unselected messages on the queue for retrieval by other clients. As long as the selection criteria used by each filter are mutually exclusive, you can add as many filters as your MOM server will allow listeners, and you only need to maintain a single queue. 11.7.2 Content-Based Routing PatternDevelopers often face a disconnect between the interface they wish to offer the user and the fundamental reality of their IT environment. This situation often comes up when two organizations merge or when new and legacy environments coexist. Imagine a large company with three or four expense-management systems. The company wants to introduce a standard, web-based expense report system for all employees. One option is to write some complicated servlets, probably building business delegates for each system and using a business delegate factory to decide, according to the employee, where to dispatch the request. This isn't a bad approach, but it does have a few drawbacks. Maintaining four business delegates isn't too difficult, since you'd have to manage that code anyway, but it's not completely flexible, either. Changing the criteria by which reports are routed to the appropriate system or adding a new system entirely will likely require changes to the core application. If you're using messaging to communicate with the expense-reporting systems, you need to maintain message channels to each system and make sure the web application knows about them. If you don't use messaging, you have to deal with the users' complaints when one system is down and their reports can't be processed. The Content-Based Routing pattern solves this problem by providing a single point of receipt for messages associated with a particular use case. Using this particular pattern allows applications to send a message to a single destination, and have that message routed appropriately, based on its content. In the expense management example, the central recipient receives all expense report requests from every system that needs to send one, examines each request, and then redirects the message to the appropriate system based on the criteria provided. Changes can be centralized with new systems, and plugged in as needed. It's called content-based routing because we route the messages based on their actual content. In the example above, the CBR implementation would be responsible for querying an employee directory to determine which expense report system should receive the message. Content-based routing can be used in situations where publish-subscribe messaging is too simple-minded. In this case, we could set up a message channel that all the expense systems subscribe to, and just have the systems ignore messages that they can't process. But this provision doesn't guarantee that the message will be processed, since it's conceivable that every system will ignore it. At the individual system level, it becomes difficult to sort out real errors from messages that were intended for other systems. The additional validity check provided by the router allows you to handle unprocessable messages in a clean fashion. Figure 11-10 shows a system that implements a content-based router to handle expense reports. The web app sends a message to the expense report router, which looks at the message, determines the division that the submitted belongs to, and routes it appropriately. The software division doesn't have a system, so a message is sent to a clerk. Based on our personal experience with expense report systems, it's clear that all of these systems route a certain percentage of reports straight to oblivion, so we implement that, too. Figure 11-10. Content-based routing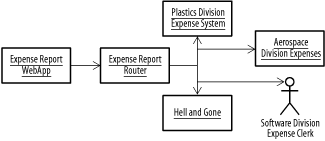 The content-based routing approach can also be used as part of a pipes and filters processing system. In the example illustrated below, the payment processing stage might route a message to different destinations based on the success or failure of the payment activity. Figure 11-11 shows a simple example: an order flow process first reserves an item in the warehouse (to prevent concurrency problems if someone else tries to buy it while the transaction is in process); then, it processes payment. The payment processor sends a message to a CBR which, depending on success or failure, either routes the order to the Shipping service or to a Stock Release message façade. Figure 11-11. Content-based routing and pipes and filters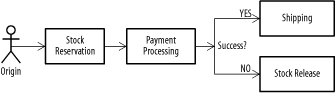 This approach allows us to easily add or remove payment types from the systema useful piece of functionality in a changing business environment. It also allows us to reuse the payment component, since we don't have to teach it how to resolve the consequences when payment fails: it just needs to add some information to the message, indicating success or failure, and send it on. 11.7.3 Content Aggregator PatternContent-based routing allows applications to send a message to a single address, but what about systems where multiple different types of messages are used to fulfill the same use case? If your message format is standardized, simple messaging, like point-to-point or publish-subscribe, will often do. But things get ugly when you can't standardize on a single message type. Single applications can end up supporting multiple incoming-message formats and even transport mechanisms. The result is a brittle aggregation of difficult to maintain systems. The Content Aggregator pattern is the inverse of a Content-Based Router pattern. When one system is being fed by messages from a variety of other systems, incoming messages are sent to a centralized aggregator, which transforms them into a common format and forwards them to an alternate destination, where the real processing is done. The component doing the heavy lifting only needs to implement a single incoming-message interface. Consider the expense report example again: the financial systems from the various divisions in the company can send messages to a content aggregator, which standardizes them and forwards them to a centralized, corporate financial-reporting system. The result is generally less code duplication, since the heavy lifting (processing the message at the target) only needs to be written and tested once. The content transformation components are generally much easier to write; as a result, they are often less error-prone and easier to test. When the message content is in XML, aggregators can often be implemented using XSL transformations. These transformations make the whole system more flexible and (potentially) easier to maintain. A content aggregator can be used in conjunction with a content-based router, giving a system one way in and one way out. 11.7.4 Control Bus PatternThe integrated enterprise creates some command and control problems. How do you tell if every system is online? Can you send commands to multiple systems at once? Or rearrange the routing of messages between systems to maximize throughput or deal with capacity problems? These are fairly intractable problems, but we can use a messaging architecture to solve some of them by linking command and control actions via the Control Bus pattern. A control bus implementation consists of one or more message channels spanning a collection of related applications. Administrative clients send command messages to the bus, and either receive responses or monitor the bus for status reports from the various applications involved. Not every message sent over a control bus needs to be intelligible to every system connected to the bus. Typical uses of a control bus are:
Figure 11-12 shows a simple control bus implementation, which uses two publish-subscribe channels, one for control messages and one for information messages. The applications receive messages on the control channel and send messages on the information channel. In this example, we have an administrative console sending messages and a logging server retrieving them. There's nothing to stop both applications from being a member of both channels. Figure 11-12. Control bus spanning three applications with logging and control channels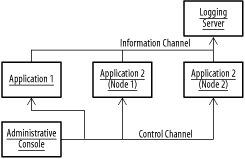 Security is important with control buses, particularly when they provide command access to lifecycle activities, or can be interrogated to provide valuable information. It's important not to leave a back door open. Control data, in particular, should never travel over the Internet without encryption. Logging data may (or may not!) be less sensitive. A control bus can be implemented using MOM or email, depending on the requirements of the current application. Email has the advantage of allowing a human being to control one end of the message exchange, which can lead to dramatic savings in message client development costs. |
| [ Team LiB ] |
|