| [ Team LiB ] |
|
12.2 Architectural AntipatternsThe first class of antipatterns we will look at is architectural in nature. These antipatterns are not J2EE-specific: they affect many Java applications and the Java APIs themselves. They are included in a book on J2EE because they affect highly scalable, long-running applicationsmeaning they are of particular relevance to J2EE developers. 12.2.1 Excessive LayeringIf you've read the preceding chapters, you've probably noticed that design patterns tend to suggest adding layers. Façades, caches, controllers, and commands all add flexibility and even improve performance, but also require more layers. Figure 12-1 shows a rough sketch of the "typical" J2EE application. Even in this simplified view, each request requires processing by at least seven different layers. And this picture doesn't even show the details of each individual layer, which may themselves contain multiple objects. Figure 12-1. A standard J2EE application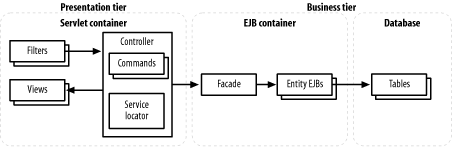 Unfortunately, in a high-level, object-oriented environment like J2EE, the layers we add are not the only layers that exist. We've already talked about containersthe servlet and EJB containers are the main onesand how they provide advanced services, generally through layers of their own. The underlying containers are themselves built on top of Java's APIs; the APIs are still a few layers away from the JVM, which interact through layered system libraries with the operating systemwhich finally talks to the actual hardware. If you look at stack traces from a running JVM, it is not surprising to see a Java application with a call stack well over 100 methods deep! It's easy to see how a CPU that can execute billions of instructions a second can get bogged down running the J2EE environment. It's also easy to think that with all these layers, adding a few of our own can't possibly make any difference. That's not the case, however. Think of the structure as a pyramid: every call to a container method requires two or four calls to the underlying Java API, which requires eight Java instructions, and so forth and so on. The layers we add are far more expensive than many of the preexisting layers. An example of the Excessive Layering antipattern is a common scenario that we call the "Persistence Layer of Doom." While abstracting database access away from business logic has so many benefits that we hesitate to say anything negative about the process, hiding SQL from other components has one serious problem: expensive activities (such as accessing a network or filesystem for a database query) start to look like cheap activities (such as reading a field from a JavaBean). Developers working on the presentation tier will inevitably call the expensive functions frequently, and end up assuming the entire business tier is horribly slow. We'll talk more about this problem later in this chapter when we discuss the Round-Tripping antipattern. 12.2.1.1 Reducing layersBecause it's easy to add layers to a J2EE application, it's important to understand which ones are necessary and which are excessive. Unfortunately, there's no generic answer, since the correct number of layers depends on the type and expected use of an application. When deciding whether to add layers, we have to balance the costs with the benefits they provide. The cost of layers can be expressed in terms of design time, code complexity, and speed. The benefits are twofold. Layers that provide abstract interfaces to more specific code allow cleaner, more extensible code. Layers such as caches, which optimize data access, can often benefit an application's scalability. While we can't provide a generic solution to layering problems, we can offer a few hints as to what level of layering is appropriate for generic types of J2EE applications:
Communication and documentation are our best weapons. When layers are added for performance, document which calls are expensive, and, where possible, provide alternative methods that batch requests together or provide timeouts. When layers are added for abstraction, document what the layer abstracts and why, especially when using vendor-specific methods (see the "Vendor Lock-In" sidebar). These steps assure that our layers enhance extensibility or improve performance instead of becoming an expensive black hole.
12.2.2 Leak CollectionAutomated memory management is one of Java's most important features. It is also somewhat of an Achilles's heel. While a developer is free to create objects at will, she does not control when or how the garbage collector reclaims them. In some situations, objects that are no longer being used may be kept in memory for much longer than necessary. In a large application, using excess memory in this way is a serious scalability bottleneck. Fortunately, by taking into account how the garbage collector actually works, we can recognize common mistakes that cause extra objects. The Java Virtual Machine uses the concept of reachability to determine when an object can be garbage-collected. Each time an object stores a reference to another object, with code like this.intValue = new Integer(7), the referent (the Integer) is said to be reachable from the object referring to it (this). We can manually break the reference, for example by assigning this.intValue = null. To determine which objects can be garbage-collected, the JVM periodically builds a graph of all the objects in the application. It does this by recursively walking from a root node to all the reachable objects, marking each one. When the walk is done, all unmarked objects can be cleaned up. This two-phase process is called mark and sweep. If you think of references as strings that attach two objects together, the mark and sweep process is roughly analogous to picking up and shaking the main object in an application. Since every object that is in use will be attached somehow, they will all be lifted up together in a giant, messy ball. The objects ready for garbage collection will fall to the floor, where they can be swept away. So how does this knowledge help us avoid memory leaks? A memory leak occurs when a string attaches an object that is no longer in use to an object that is still in use. This connection wouldn't be so bad, except that the misattached object could itself be connected to a whole hairball of objects that should otherwise be discarded. Usually, the culprit is a long-lived object with a reference to a shorter-lived object, a common case when using collections. A collection is an object that does nothing more than organize references to other objects. The collection itself (a cache, for example) usually has a long lifespan, but the objects it refers to (the contents of the cache) do not. If items are not removed from the cache when they are no longer needed, a memory leak will result. This type of memory leak in a collection is an instance of the Leak Collection antipattern. In Chapter 5, we saw several instances of caches, including the Caching Filter pattern. Unfortunately, a cache with no policy for expiring data constitutes a memory leak. Consider Example 12-1, a simplified version of our caching filter. Example 12-1. A simplified CacheFilterpublic class CacheFilter implements Filter {
// a very simple cache
private Map cache;
public void doFilter(ServletRequest request,
ServletResponse response, FilterChain chain)
throws IOException, ServletException {
...
if (!cache.containsKey(key)) {
cache.put(key, data);
}
// fulfill the response from the cache
if (cache.containsKey(key)) {
...
}
}
public void init(FilterConfig filterConfig) {
...
cache = new HashMap( );
}
}
Nowhere in this code is there a remove( ) call to match the put( ) call that adds data to the cache. Without a cache expiration policy, the data in this cache will potentially use all the available memory, killing the application. 12.2.2.1 Reclaiming lost memoryThe hardest part of dealing with Java memory leaks is discovering them in the first place. Since the JVM only collects garbage periodically, watching the size of the application in memory isn't very reliable. Obviously, if you're seeing frequent out-of-memory type errors, it's probably too late. Often, commercial profiling tools are your best bet to help keep an eye on the number of objects in use at any one time. In our trivial example, it should be clear that adding data to the cache and never removing it is a potential memory leak. The obvious solution is to add a simple timer that cleans out the cache at some periodic interval. While this may be effective, it is not a guarantee: if too much data is cached in too short a time, we could still have memory problems. A better solution is to use a Java feature called a soft reference, which maintains a reference to an object but allows the cached data to be garbage-collected at the collector's discretion. Typically, the least-recently used objects are collected when the system is running out of memory. Simply changing the way we put data in the cache will accomplish this: cache.put(key, new SoftReference(data)); There are a number of caveats, the most important being that when we retrieve data, we have to manually follow the soft reference (which might return null if the object has been garbage-collected): if (cache.containsKey(key)) {
SoftReference ref = (SoftReference) cache.get(key);
Object result = ref.get( );
if (result == null) {
cache.remove(key);
}
}
Of course, we could still run out of memory if we add too many keys to the cache. A more robust solution uses a reference queue and a thread to automatically remove entries as they are garbage-collected. In general, the most effective way to fight memory leaks is to recognize where they are likely to be. Collections, as we have mentioned, are a frequent source of leaks. Many common featuressuch as attribute lists and listenersuse collections internally. When using these features, pay extra attention to when objects are added and removed from the collection. Often, it is good practice to code the removal at the same time as the addition. And, of course, make sure to document pairs of adds and removes so that other developers can easily figure out what you did. |
| [ Team LiB ] |
|