| [ Team LiB ] |
|
5.3 Resource PoolA resource pool is a collection of precreated objects that can be loaned out to save the expense of creating them many times. Examples of resource pools are everywhere in J2EE. When a connection comes in, a thread is retrieved from a thread pool to handle the request. If the processing requires an EJB, one may be allocated from a pool of EJBs. And if the EJB requires access to a database, the connection will come fromsurprise!a connection pool. Pools are so prevalent because they solve two problems simultaneously: they improve scalability by sharing the cost of instantiating complex resources over multiple instances, and they allow precise tuning of parallelism and memory use. To illustrate, let's discuss the classic use case for pools: database connections. The process of connecting to a database, especially a remote one, can be complex and costly. While it may only require a single method call, instantiating a database connection may involve any or all of the following steps:
After all of these steps, the connection is finally ready to use. It's not just expensive in terms of time, either. The connection object must store many of the options it is passed, so each connection requires a fair bit of memory, too. If connections are not shared, the connections and costs grow with the number of requests. As the costs add up, the need to create and maintain database connections limits the number of clients that an application can support. Obviously, sharing connections is a must for scalability, but sharing has costs, too. At the extreme, you could develop an entire application with a single database connection shared between all the clients. While this effectively removes the cost of creating the database connection, it limits parallelism since access to the database must be synchronized in some way. Sharing database connections also prevents individual components of the application from engaging in transactions (see Chapter 10). A better solution is to create a number of connections that are shared in a common "pool" between clients. When a client needs access to a database, the client takes a connection from the pool and uses it. When the client is done, it returns the connection so another client can use it. Because the connections are shared, the startup and maintenance costs are amortized over many clients. The number of connections has an upward boundary, so the creation and maintenance costs don't spiral out of control. Another major advantage of pools is that they create a single point for effective tuning. Putting more objects in the pool uses more memory and increases startup time, but usually means you can support more clients. Conversely, a smaller pool often improves scalability by preventing a single operation from hogging memory and CPU time. By changing the pool parameters at runtime, the memory and CPU usage can be tailored to each system the application runs on. 5.3.1 The Resource Pool PatternThe Resource Pool pattern can be applied to many costly operations. Pools show the most benefits for objects like database connections and threads that have high startup costs. In these cases, the pattern amortizes the startup costs over multiple objects. But pools can also be adapted for operationslike parsingthat simply take a long time, allowing fine-grained control of memory and CPU usage. Figure 5-6 shows a generalization of a resource pool. Figure 5-6. The Resource Pool pattern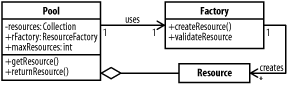 The Pool object is responsible for creating, maintaining, and controlling access to the Resource objects. A client calls the getResource( ) method to get an instance of the resource. When it is finished, it uses the returnResource( ) method to add the resource back to the pool. The pool uses a Factory object to create the actual resources. By using a factory, the same pool can work for many different kinds of objects. The factory's createResource( ) method is used to generate new instances of a resource. Before a resource is reused, the pool calls the factory's validateResource( ) method to reset the resource to its initial state. If, for example, the resource is a database connection that has been closed, the validateResource( ) method can simply return false to have a new connection added to the pool instead. For further efficiency, the factory may even try to repair the returned objectsay, by reopening the database connection. This is sometimes called a recycler method. There are really no limits on the Resource class itself. The contents and use of a resource must be coordinated between the creator of the pool and the various clients. Usually, pools only store one type of object, but this is not required. Advanced implementations of pools sometimes even allow a filter to be provided to the getResource( ) method in order to specify desired criteria of the resource. 5.3.2 Implementing a Resource PoolWithin a servlet engine, a pool of threads handles requests. Each request is handled by a single thread from this pool, which accesses shared instances of servlets to generate the result. In most application servers, the number of threads in the thread pool is configurable at runtime. The number of threads is a critical variable for tuning the scalability of your web application: if the pool is too small, clients will be rejected or delayed; if the pool is too large, the server can't to keep up and the application runs slowly. Just because the servlet threads are already pooled does not mean we are done with pools. The servlet thread pool represents the most coarse-grained pool possible. Using a single pool assumes that the same thing limits all requests: for example, the speed of XML parsing or connecting to the database. In reality, different requests are usually limited by different operations. Having a separate pool for XML parsers and database connections could allow the total number of threads to be increased, with the limits placed at parsing or connection time, depending on the type of request. As the pattern description suggests, implementing a resource pool in Java is quite simple. We would like our resource pool to be generic, so that we can easily create a pool of any object by writing an appropriate factory. Obviously, our pool needs to be thread-safe, as we assume that multiple threads will access it simultaneously (any pool used in a servlet environment will face this situation). Example 5-5 shows a simple pool implementation. Example 5-5. ResourcePool.javaimport java.util.*;
public class ResourcePool {
private ResourceFactory factory;
private int maxObjects;
private int curObjects;
private boolean quit;
// resources we have loaned out
private Set outResources;
// resources we have waiting
private List inResources;
public ResourcePool(ResourceFactory factory, int maxObjects) {
this.factory = factory;
this.maxObjects = maxObjects;
curObjects = 0;
outResources = new HashSet(maxObjects);
inResources = new LinkedList( );
}
// retrieve a resource from the pool
public synchronized Object getResource( ) throws Exception {
while(!quit) {
// first, try to find an existing resource
if (!inResources.isEmpty( )) {
Object o = inResources.remove(0);
// if the resource is invalid, create a replacement
if(!factory.validateResource(o))
o = factory.createResource( );
outResources.add(o);
return o;
}
// next, create a new resource if we haven't
// reached the limit yet
if(curObjects < maxObjects) {
Object o = factory.createResource( );
outResources.add(o);
curObjects++;
return o;
}
// if no resources are available, wait until one
// is returned
try { wait( ); } catch(Exception ex) {}
}
// pool is destroyed
return null;
}
// return a resource to the pool
public synchronized void returnResource(Object o) {
// Something is wrong. Just give up.
if(!outResources.remove(o))
throw new IllegalStateException("Returned item not in pool");
inResources.add(o);
notify( );
}
public synchronized void destroy( ) {
quit = true;
notifyAll( );
}
}
Example 5-5 assumes the very simple factory interface we sketched earlier: public interface ResourceFactory {
public Object createResource( );
public boolean validateResource(Object o);
}
To see resource pools in action, let's look at an operation that is used frequently but rarely pooled: XML parsing. Like database connections, XML parsers can be expensive to create and maintain. By using a pool of parsers, we not only share the cost of creating them, we can control how many threads are performing expensive XML parsing operations at any given time. To create a pool of parsers, all we have to build is the XMLParserFactory shown in Example 5-6. Example 5-6. XMLParserFactoryimport javax.xml.parsers.*;
public class XMLParserFactory implements ResourceFactory {
DocumentBuilderFactory dbf;
public XMLParserFactory( ) {
dbf = DocumentBuilderFactory.newInstance( );
}
// create a new DocumentBuilder to add to the pool
public Object createResource( ) {
try {
return dbf.newDocumentBuilder( );
} catch (ParserConfigurationException pce) {
...
return null;
}
}
// check that a returned DocumentBuilder is valid
// and reset parameters to defaults
public boolean validateResource(Object o) {
if (!(o instanceof DocumentBuilder)) {
return false;
}
DocumentBuilder db = (DocumentBuilder) o;
db.setEntityResolver(null);
db.setErrorHandler(null);
return true;
}
}
To use our pooled XML parsing mechanism, a simple client might look like: public class XMLClient implements Runnable {
private ResourcePool pool;
public XMLClient(int poolsize) {
pool = new ResourcePool(new XMLParserFactory( ), poolsize);
...
// start threads, etc.
Thread t = new Thread(this);
t.start( );
...
// wait for threads
t.join( );
// cleanup
pool.destroy( );
}
public void run( ) {
try {
// get parser from pool
DocumentBuilder db = (DocumentBuilder)pool.getResource( );
} catch(Exception ex) {
return;
}
try {
...
// do parsing
...
} catch(Exception ex) {
...
} finally {
// make sure to always return resources we checkout
pool.returnResource(db);
}
}
}
Resource pools look good on paper, but do they actually help for XML parsing? And if we are going to use them, how do we choose the correct size? Let's take a minute to look at the real-world use and performance of pools. An important step in using a pool is sizing it properly. For our test systems, we used a two-CPU server and a six-CPU server, both with plenty of memory; we expected to be able to handle a fair number of threads. Using a sample program similar to the one outlined above, we looked at how long it took to parse a 2,000-line XML file with various combinations of number of threads and pool size. Table 5-1 shows the optimal pool size for each thread count on each server. It's not surprising that for a CPU-limited task like XML parsing, the optimal pool size is generally pretty close to the number of CPUs in the system. For an I/O-limited task, like reading data from the network, we would expect very different results.
Now that we have optimal pool sizes worked out, we can see the scalability improvements. We tried two variations of the sample program, one with the optimal pool size, and one with no pool, and compared the time required per thread. Figure 5-7 shows the results of our experiment. Figure 5-7. XML parsing speed with and without a pool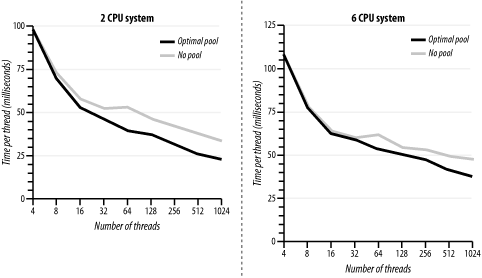 The pool gives a significant advantage, especially when more than 32 threads are active. These results fit into our theory that pools increase scalability for CPU-intensive tasks by limiting the overhead of switching between too many tasks at once. It should not be surprising that in addition to the speed gains we saw with pools, there was also much less variation between different trials with the same number of threads when pools were in use. In this chapter, we looked at three patterns that increase the scalability of the presentation tier. The Asynchronous Page pattern shows how to cache data when it is read from external sources. The Caching Filter pattern describes how to cache entire pages as they are generated. The Resource Pool pattern creates a pool of expensive objects that can be loaned out. All these patterns also allow the developer to tune the application, balancing memory and CPU use for the entire system. |
| [ Team LiB ] |
|