| [ Team LiB ] |
|
9.3 Finding ResourcesA presentation tier is only as good as the data it has to present. In some applications, finding data is as simple as instantiating the appropriate business delegate and calling a method. But life gets complicated when an application grows to encompass a range of resources that are spread across a number of services. To help manage distributed components, J2EE specifies that they should be connected via the Java's directory API, JNDI. JNDI is a simple, standard API that allows communication with a variety of directories such as LDAP and NDS. Using a directory server, clients are somewhat shielded from the complexities of distributed environments. The canonical J2EE picture is shown in Figure 9-10. Figure 9-10. A distributed J2EE environment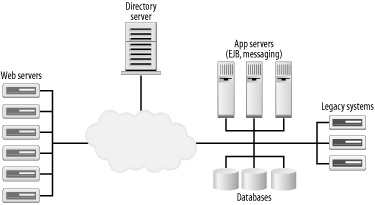 The nice thing about a directory is that a client can get a reference to a resource anywhere on the network, remote or local, with a single lookup. This decouples the client from a particular server implementation. Of course, there is no such thing as a free lunch, and anyone who has actually built a distributed J2EE environment knows that all we have done is shift a development headache to a deployment headache. Finding resources on the network has performance implications. Connecting to a remote EJB might first require querying the directory server for the EJB's location. While the cost may not seem substantial, we effectively double the number of connections required for a given operation. When we add the costs for connecting to databases, message queues, legacy applications, and web services, connecting to the directory server becomes a bottleneck. 9.3.1 The Service Locator PatternThe Service Locator pattern simplifies connecting to remote services, while minimizing the costs associated with these connections. A ServiceLocator object acts as an intelligent connection from the presentation tier to the various remote services. The service locator is the application's central point of access for directory services. A more advanced locator may use pools and caches to improve efficiency. Figure 9-11 shows the classes involved in the Service Locator pattern. Figure 9-11. Service locator classes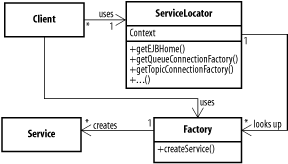 The service locator's client may be a presentation-tier object, such as a servlet that needs access to business data, or a business tier object. When a client needs access to some object in the directory, it calls the appropriate method on the service locator for that service. The locator then uses the directory or an internal cache to find the service's factory and return it to the client. The client can use this factory to create an instance of the service. Factory objects are responsible for creating instances of services. For EJBs, the factories are the home interfaces for each bean. For JMS queues, they are the TopicConnectionFactory and QueueConnnectionFactory objects associated with each topic or queue. DataSource objects produce database connections. A locator might seem like a roundabout way to access services, but it has distinct advantages. In a complicated environment, connecting to a directory server can be an involved process, requiring connection parameters and credentials. Scattering lookups throughout the application makes switching directories a real headache. Having a single, central service locator means there's a single piece of code to modify when the underlying directory changes. The biggest advantage, however, is in efficiency. As we keep mentioning, the ServiceLocator is an ideal location for a cache. By caching mappings between directory names and objects, the locator can prevent many queries to the directory. This speeds up the client and allows more clients to access a single directory. 9.3.2 Service Locator VariationsThe connection between the presentation tier and the underlying business tiers is a critical one. In most systems, the vast majority of requests that comes in to the presentation tier require some connection to the business tier. Anything that reduces the cost of this connection will provide an overall gain in scalability. Because it abstracts access to the business tier, the service locator is the logical place to tune connections to the backend. Here are a few variations on the basic service locator that help it handle certain situations:
One of the main problems with caching in a ServiceLocator is keeping the cache up-to-date. When a service is moved or goes away, the clients are stuck getting invalid objects from the locator's cache. To fix this problem, the locator must validate the objects in its cache. Validating objects as they are returned to clients might seem logical, but requiring remote requests removes the efficiency gained by using caching. Instead, the locator is usually designed to validate cached objects with a low priority thread that runs in the background. This precautionary step won't catch every bad object, but it will catch most of them, and the client can always request a new one if a bad object slips through the cracks; the incidence is low enough that you still realize major gains.
The task of maintaining connections to services on a network can be a difficult one. In a complicated environment, services can come and go, and move from server to server. Keeping up with dynamic services using static methods such as those presented here can be nearly impossible. While it is outside the scope of J2EE, Jini technology centers around an elegant architecture for connecting network services. Jini can greatly simplify the deployment and maintenance challenges presented by a dynamic, distributed system. 9.3.3 Implementing a Service LocatorThe most common implementation of service locators is for EJBs. In this case, the ServiceLocator contains a method called getEJBHome( ), which, given a JNDI directory name and a class name, returns an EJBHome object. When a servlet needs access to an EJB, it calls the service locator instead of making its own call to JNDI to locate the EJB's home object. The locator returns the EJBHome, and the client uses it to create, update, or delete EJB. These interactions are shown in Figure 9-12. Figure 9-12. Looking up an EJB using a locator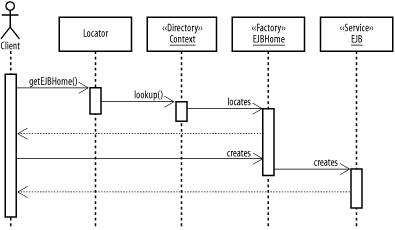 Implementing the simple ServiceLocator is quite easy. Example 9-7 shows a ServiceLocator that looks up EJBs in a JNDI directory based on the name and class passed in. While it does cache the lookup results, it does no validation of the initial input and no maintenance of the cached objects. Example 9-7. The ServiceLocator classpublic class ServiceLocator {
private static ServiceLocator instance;
private HashMap cache;
private Context context;
// return the singelton service locator
public static ServiceLocator getInstance( )
throws ServiceLocatorException {
if (instance == null)
instance = new ServiceLocator( );
return instance;
}
// Creates a new instance of ServiceLocator
private ServiceLocator( ) throws ServiceLocatorException {
cache = new HashMap( );
// initialize the shared context object
try {
context = new InitialContext( );
} catch(NamingException ne) {
throw new ServiceLocatorException("Unable to create " + "initial context", ne);
}
}
// get an EJB from the cache or directory service
public EJBHome getRemoteEJB(String name, Class type)
throws ServiceLocatorException {
// see if it's in the cache
if (cache.containsKey(name)) {
// cache HomeHandle objects since they are maintained
// by the container
HomeHandle hh = (HomeHandle)cache.get(name);
try {
return hh.getEJBHome( );
} catch(RemoteException re) {
// some kind of problem -- fall through to relookup below
}
}
// access to the shared context as well as modifications
// to the HashMap must be synchronized. Hopefully the
// majority of cases are handled above
synchronized(this) {
try {
Object rRef = context.lookup(name);
EJBHome eh = (EJBHome)PortableRemoteObject.narrow(rRef, type);
cache.put(name, eh.getHomeHandle( ));
return eh;
} catch(Exception ex) {
throw new ServiceLocatorException("Unable to find EJB",ex);
}
}
}
}
Creating a client to use this locator is equally simple. For an EJB for patient records in a hospital, we might use: ServiceLocator sl = ServiceLocator.getInstance( );
PatientHome ph = (PatientHome)sl.getRemoteEJB("Patient",
PatientHome.class);
Patient p = ph.create( );
...
We do not cache EJBHome objects at all, but rather instances of the derived HomeHandle class. The HomeHandle is a container-specific object that can be used to get an EJBHome object in a persistent way. When the HomeHandle's getEJBHome( ) method is called, it is up to the container to find the latest version of the EJBHome object. Home handles can even be serialized and stored on disk. As with any container-implemented field, your mileage will vary depending on your vendor. Most containers are pretty good about maintaining home handles, although they are not to be trusted when resources move from server to server. Also, note the use of fine-grained synchronization. From the documentation, we learn that the InitialContext object is not thread-safe at all, while the HashMap object is safe to read from multiple threads, but not to write. This means that the first blockreading the map and returning a cached objectdoes not require any synchronization. By synchronizing only what we need instead of the whole method, we allow the majority of cases to be fulfilled from the cache even while a lookup is in progress. In this implementation, we chose to only cache EJB Home objects, not EJBs themselves. Obviously, some EJBs are easier to cache then others. Session EJBs are usually only relevant for the life of a single session, so it doesn't often make sense to cache them. It's more logical to cache entity EJBs, but the cache must be kept up-to-date when they are accessed by multiple sources. |
| [ Team LiB ] |
|