| [ Team LiB ] |
|
2.1 Relational ConceptsBefore we approach the details of relational data architecture, it helps to establish a base understanding of relational concepts. If you are an experienced database programmer, you will probably want to move on to the next section on normalization. In this section, we will review the key concepts behind relational databases critical to an in-depth understanding of relational data architecture.
2.1.1 The Relational ModelA database is any collection of related data. The files on your hard drive and the piles of paper on your desk all count as databases. What distinguishes a relational database from other kinds of databases is the mechanism by which the database is organizedthe way the data is modeled. A relational database is a collection of data organized in accordance with the relational model to suit a specific purpose. Relational principles are based on the mathematical concepts developed by Dr. E. F. Codd that dictate how data can be structured to define data relationships in an efficient manner. The focus of the relational model is thus the data relationships. In short, by organizing your data according to the relational model as opposed to the hierarchical principles of your filesystem or the random mess of your desktop, you can find your data at a later date much easier than you would have had you stored it some other way. A relationship in relational parlance is a table with columns and rows.[1] A row in the database represents an instance of the relation. Conceptually, you can picture a table as a spreadsheet. Rows in the spreadsheet are analogous to rows in a table, and the spreadsheet columns are analogous to table attributes. The job of the relational data architect is to fit the data for a specific problem domain into this relational model.
2.1.2 EntitiesThe relational model is one of many ways of modeling data from the real world. The modeling process starts with the identification of the things in the real world that you are modeling. These real world things are called entities. If you were creating a database to catalog your music library, the entities would be things like compact disc, song, band, record label, and so on. Entities do not need to be tangible things; they can also be conceptual things like a genre or a concert.
An entity is described by its attributes. Back to the example of a music library, a compact disc has attributes like its title and the year in which it was made. The individual values behind each attribute are what the database engine stores. Each row describes a distinct instance of the entity. A given instance can have only a single value for each attribute. Table 2-1 describes the attributes for a CD entity and lists instances of that entity.
You could, of course, store this entire list in a spreadsheet. If you wanted to find data based on complex criteria, however, the spreadsheet would present problems. If, for example, you were having a "Johnny Rotten Night" party featuring music from the punk rocker, how would you create this list? You would probably go through each row in the spreadsheet and highlight the compact discs from Johnny Rotten's bands. Using the data in Table 2-1, you would have to hope that you had in mind an accurate recollection of which bands he belonged to. To avoid taxing your memory, you could create another spreadsheet listing bands and their members. Of course, you would then have to meticulously check each band in the CD spreadsheet against its member information in the spreadsheet of musicians. 2.1.3 ConstraintsWhat constitutes identity for a compact disc? In other words, when you look at a list of compact discs, how do you know that two items in the list are actually the same compact disc? On the face of it, the disc title seems as if it might be a good candidate. Unfortunately, different bands can have albums with the same title. In fact, you probably use a combination of the artist name and disc title to distinguish among different discs. The artist and title in our CD entity are considered identifying attributes because they identify individual CD instances. In creating the table to support the CD entity, you tell the database about the identifying attributes by placing a constraint on the database in the form of a unique index or primary key. Constraints are limitations you place on your data that are enforced by the DBMS. In the case of unique indexes (primary keys are a special kind of unique index), the DBMS will prevent the insertion of two rows with the same values for the entity's identifying attributes. The DBMS would prevent, for example, the insertion of another row with values of 'Ramones' and 'Mania' for the artist and title values in a CD table having artist and title as a unique index. It won't matter if the values for all of the other columns differ.
Constraints like unique indexes help the DBMS help you maintain the overall data integrity of your database. Another kind of constraint is formally known as an attribute domain. You probably know the domain as its data type. Choosing data types and indexes along with the process of normalization are the most critical design decisions in relational data architecture. 2.1.3.1 IndexesAn index is a constraint that tells the DBMS about how you wish to search for instances of an entity. The relational model provides for three main kinds of indexes:
We can examine the impact of indexes by creating the CD entity as a table in a MySQL database and using a special SQL command called the EXPLAIN command. The SQL to create the CD table looks like this: CREATE TABLE CD (
artist VARCHAR(50) NOT NULL,
title VARCHAR(100) NOT NULL,
category VARCHAR(20),
year INT
);
The EXPLAIN command tells you what the database will do when trying to run a query. In this case, we want to look at what happens when we are looking for a specific compact disc: mysql> EXPLAIN SELECT * FROM CD
-> WHERE artist = 'The Cure' AND title = 'Pornography';
+-------+------+---------------+------+---------+------+------+------------+
| table | type | possible_keys | key | key_len | ref | rows | Extra |
+-------+------+---------------+------+---------+------+------+------------+
| CD | ALL | NULL | NULL | NULL | NULL | 10 | where used |
+-------+------+---------------+------+---------+------+------+------------+
1 row in set (0.00 sec)
The important information in this output for now is to look at the number of rows. Given the data in Table 2-1, we have 10 rows in the table. The results of this command tell us that MySQL will have to examine all 10 rows in the table to complete this query. If we add a unique index, however, things look much better: mysql> ALTER TABLE CD ADD UNIQUE INDEX ( artist, title );
Query OK, 10 rows affected (0.20 sec)
Records: 10 Duplicates: 0 Warnings: 0
mysql> EXPLAIN SELECT * FROM CD
-> WHERE artist = 'The Cure' AND title = 'Pornography';
+-------+-------+---------------+--------+---------+-------------+------+
| table | type | possible_keys | key | key_len | ref | rows |
+-------+-------+---------------+--------+---------+-------------+------+
| CD | const | artist | artist | 150 | const,const | 1 |
+-------+-------+---------------+--------+---------+-------------+------+
1 row in set (0.00 sec)
mysql>
The same query can now be executed simply by examining a single row.
Unfortunately, the artist and title probably make a poor unique index. First of all, there is no guarantee that a band will actually choose distinct names for its albums. Worse, in some circumstances, bands have chosen to have the same album carry different names. Public Image Limited's Compact Disc is an example of such an album. The cassette version of the album is called Cassette. Even if artist and title were solid identifying attributes, they still make for a poor primary key. A primary key must meet the following requirements:
In addition to these requirements, good primary keys have the following characteristics:
It is very common for people to find attributes inherent in an entity and chose one or more of those identifying attributes as a primary key. Perhaps the best example of this practice is the use of an email address as a primary key. Email addresses, however, can and do change. A change to a primary key attribute can cause an instance to become inaccessible to anyone with old information about the instance. In plain English, it can break your application. Another example of a common primary key with meaning is a U.S. Social Security number. It is supposed to be unique. It is never supposed to change. You, however, have no control over its uniqueness or whether it changes. As it turns out, sometimes the uniqueness of Social Security numbers is violated. In addition, they do sometimes change. Furthermore, in many cases, the law restricts your ability to share this information. It is therefore best to choose a primary key with no external meaning; you will control exactly how it is used and have the full power to enforce its uniqueness and immutability.
The solution is to create a new attribute to serve as the primary identifier for instances of an entity. For the CD table, we will call this new attribute the cdID. The SQL to create the table then looks like this: CREATE TABLE CD (
cdID INT NOT NULL,
artist VARCHAR(50) NOT NULL,
title VARCHAR(100) NOT NULL,
category VARCHAR(20),
year INT,
PRIMARY KEY ( cdID ),
INDEX ( artist, title ),
INDEX ( category ),
INDEX ( year )
);
Ideally, you always search on unique indexes. In the real world, however, you will select on attributes like the year or genre that are not unique. You can still help the database organize the underlying data storage by creating plain indexes. In general, you want any attribute you commonly search on to be indexed. An index does, however, come with some downsides:
In other words, if you have a table on which you perform a significant number of write operations, you want to minimize your indexes to those attributes that appear frequently in queries. Finally, as you have already seen, you can have indexesincluding primary keysthat are formed out of any number of identifying columns so long as those columns together sufficiently identify a single entity instance. It is always a good idea, however, to build primary keys out of the minimal number of columns possible.
2.1.3.2 DomainsThe proper choice of data type is another critical aspect of relational data architecture. It constrains the kind of data that can be stored for a given attribute. By creating an email attribute as a text value, you prevent people from storing numbers in the field. A time-oriented domain like a SQL DATE enables you to perform time arithmetic on date values. The domains that exist in a relational database depend on the DBMS of choice. Those that support the SQL specification generally support a core set of data types. Just about every database engine comes with its own, proprietary data types. When modeling a system, you should use SQL-standard data types. Primary keys deserve special consideration when you are putting domain constraints on an entity. Because they are the primary mechanism for getting access to an entity instance, it is important that the database is able to do quick matches against primary key values. In general, numeric types form the best primary keys. I recommend the use of 64-bit, sequentially generated integers for primary key columns. The only exception is for lookup tables. A lookup table is a small table with a known, finite set of data like a table containing a list of states or, with respect to the music library example, a set of genres. In the case of lookup tables, they more often than not have codes against which you will do most lookups. For example, you will almost always retrieve the state of Maine from a State table by its abbreviation ME. It therefore makes more sense to use fixed character data types like SQL's CHAR for primary keys in lookup tables. The length of these fixed character values should be no more than a few characters.
The data types for other kinds of attributes vary with the diversity in the kinds of data you will want to store in your databases. These days, many databases even support the creation of user-defined data types. These pseudo-object data types prove particularly useful in the development of Java database applications. 2.1.4 RelationshipsThe creation of relationships among the entities in the database lies at its heart. These relationships enable you to easily answer the question, "On what compact discs in my library did Johnny Rotten play?" Unlike other models, the relational model does not create hard links between two entities. In the hierarchical model, a hard relationship exists between a parent entity and its child entities. The relational model, on the other hand, creates relationships by matching a primary key attribute in one entity to a foreign key attribute in another entity. The relational model supports three kinds of entity relationships:
With any of these relationships, one side of the relationship may be optional. An optional relationship allows the foreign key to contain NULL values to indicate the relationship does not exist for that row. 2.1.4.1 One-to-one relationshipsThe one-to-one relationship is the most rare relationship in the relational model. A one-to-one relationship says that for every instance of entity A, there is a corresponding instance of entity B. It is so rare that its appearance in a data model should be met with skepticism as it generally indicates a design flaw. You indicate a one-to-one relationship in the same way you indicate a one-to-many relationship.
2.1.4.2 One-to-many relationshipsA one-to-many relationship means that for every instance of entity A, there can be multiple instances of entity B. As Figure 2-1 shows, the "many" side of the relationship houses the foreign key that points to the primary key of the "one" side of the relationship. Figure 2-1. A One-to-Many Relationship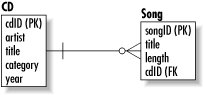 Table 2-2 lists data from a Song table whose rows are dependent on rows in the CD table.
Under this design, one compact disc is associated with many songs. The placement of cdID into the Song table as a foreign key indicates the dependency on a row of the CD table. In databases that manage foreign key constraints, this dependency will prevent the insertion of songs into the Song table that do not already have a corresponding CD. Similarly, the deletion of a disc will cause the deletion of its associated songs. You should note, however, that not all database engines support foreign key constraints. Of those that do support them, you often have the option of turning them on or off.
You now have a proper relationship between compact discs and their songs. To ask which songs are on a particular compact disc, you need to ask the Song table which songs have the disc's cdID. Assuming you are looking for all songs from the disc Garbage (cdID 2), the SQL to find the songs looks like this: SELECT songID, title FROM Song WHERE cdID = 2; More powerfully, however, you can ask for all songs from a compact disc by the disc title: SELECT Song.songID, Song.title FROM Song, CD WHERE CD.title = 'Last Rights' AND CD.cdID = Song.cdID; The last part of the query where the cdID was compared in both tables is called a join. A join is where the implicit relationship between two tables becomes explicit. 2.1.4.3 Many-to-many relationshipsA many-to-many relationship allows an instance of entity A to be associated with multiple instances of entity B and an instance of entity B to be associated with multiple instances of entity A. These relationships require the creation of a special table to manage the relationship. You may hear these tables referred to by any number of names: composite entities, join tables, cross-reference tables, and so forth. This extra table creates the relationship by having the primary keys of each table in the relationship as foreign keys. It then uses the combination of foreign keys as its own compound primary key. If, for example, we had an Artist table in our music library, we indicate a many-to-many relationship between an Artist and a CD through an ArtistCD join table. Table 2-3 shows this special table.
You can now ask for all of the compact discs by Garbage: SELECT CD.cdID, CD.title FROM CD, ArtistCD, Artist WHERE ArtistCD.cdID = CD.cdID AND ArtistCD.artistID = Artist.artistID AND Artist.name = 'Garbage';
Another useful aspect of join tables is that you can use them to contain information about a relationship. If, for example, you wanted to track guest artists on albums, where would you store that information? It really is not an attribute of an artist or a compact disc. It is instead an attribute of the relationship between the two entities. To capture this information, you would therefore add a column to ArtistCD called guest. Finding which compact discs on which Sting appeared as a guest artist would then be as simple as: SELECT CD.cdID, CD.title FROM CD, ArtistCD, Artist WHERE ArtistCD.cdID = CD.cdID AND ArtistCD.artistID = Artist.artistID AND Artist.name = 'Sting' AND ArtistCD.guest = 'Y'; 2.1.5 NULLNULL is a special value in relational databases that indicates the absence of a value. If you have a pet store site that gathers information on your users, for example, you may track the number of pets your users have. Without the concept of NULL, you have no proper way to indicate that you do not know how many pets a user has. Applications commonly resort to nonsense values (like -1) or unlikely values (like 9999) as a substitute for NULL.
Though the basic concept of NULL is pretty straightforward, beginning database programmers often have trouble figuring out how NULL works in database operations. A basic example would come about by adding a new column to our Song table that is a rating. It can be NULL since it is unlikely anyone wants to rate every single song in their library. The following SQL may not do what you think: SELECT songID, title FROM Song WHERE rating = NULL; No matter what data is in your database, this query will always return zero rows. Relational logic is not Boolean; it is three-value logic: true, false, and unknown. Most NULL comparisons therefore result in NULL since a NULL comparison is indeterminate under three-value logic. SQL provides special mechanisms to test for NULL in the form of IS NULL and IS NOT NULL so that it is possible to ask for the unrated songs: SELECT songID, title FROM Song WHERE rating IS NULL; |
| [ Team LiB ] |
|
