| [ Team LiB ] |
|
3.3 JDBC Transaction ManagementNo matter what style of database programming you select or what persistence model you follow, transactions will always be the most fundamental element in database programming. Consequently, we will be returning to transaction management repeatedly over the course of this book. For now, it is time to lay the foundation for that database programming by showing the basics of transaction management in Java code. 3.3.1 Basic Transaction ManagementIn any programming language, basic transaction management is indicating the start and end of a transaction as well as handling any errors that come up during the transaction. In JDBC, a transaction begins implicitly whenever you create a statement of any kind. It ends when you call commit( ) in the Connection instance. Finally, you abort the transaction and return the database to its initial state by calling rollback( ) in the Connection instance. The Connection governs all of this transaction management. You therefore cannot use statements from different Connection instances in the same transaction. You also have to tell the connection that your application is managing transactions; otherwise, it will commit every statement after you send it to the database. The following code executes two updates in a single transaction and rolls back on any errors: public void transfer(Account targ, float amt) {
Connection conn = null;
try {
PreparedStatement stmt;
conn = dataSource.getConnection( );
conn.setAutoCommit(false);
stmt = conn.prepareStatement("UPDATE Account SET balance = ? " +
"WHERE id = ?");
stmt.setFloat(1, balance-amt);
stmt.setInt(2, id);
stmt.executeUpdate( );
stmt.setFloat(1, targ.balance + amt);
stmt.setInt(2, targ.id);
stmt.executeUpdate( );
balance -= amt;
targ.balance += amt;
conn.commit( );
}
catch( SQLException e ) {
try { conn.rollback( ); }
catch( SQLException e ) { }
}
finally {
if( conn != null ) {
try { conn.close( ); }
catch( SQLException e ) { }
}
}
}
3.3.2 Optimistic ConcurrencyIn the days of client/server programming, applications often started a transaction by reading data from a database and ended the transaction by modifying that data. In other words, you locked the data you read so that someone else didn't overwrite any changes you made. For example, if you and I read a customer record from the database with my goal to change the phone number and your goal to change the last name, one of us runs the risk of overwriting the other's changes if neither of us has a read lock. If I saved my changes first, your client application will likely overwrite my phone number change with the old phone number since applications tend to send all fields with their updates. Figure 3-3 illustrates what can go wrong in this example. Figure 3-3. Updates overwriting each other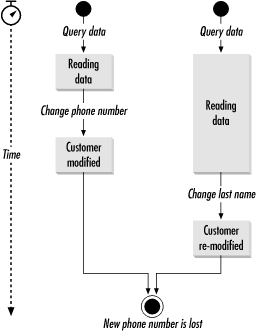 I can prevent you from overwriting my changes by starting a transaction when I read the data. That way you cannot even read the customer record until my change is saved. This technique is called pessimistic concurrency, and it is a terrible bottleneck. If I manage to walk away from my desk while entering the phone number, your client will be waiting a long time to read that data. In web-based applications, this kind of pessimistic concurrency is completely untenable. You can make pessimistic concurrency a little more acceptable by performing a SELECT FOR UPDATE just prior to actually sending changes to the database using the values returned from the first query. If the rows no longer match the original select, then you will receive no rows and lock no resources in the database. Though this form of pessimistic concurrency locks resources for a much shorter time than the original, it is still a relatively long-lived transaction. It also requires placing columns that are probably not indexed in a SELECT statement. The following example illustrates this flow: SELECT firstName, lastName, phone, birthDay FROM Customer WHERE id = ?; // on the client, make changes here // this could take a long, long time // minutes, even tens of minutes SELECT firstName, lastName, phone, birthDay FROM Customer WHERE id = ? AND firstName = ? AND lastName = ? AND phone = ? AND birthDay = ? FOR UPDATE UPDATE Customer SET firstName = ?, lastName = ?, phone = ?, birthDay = ? WHERE id = ? The alternative is optimistic concurrency. Where pessimistic concurrency pessimistically assumes that some other transaction will attempt to make changes to your data behind your back, optimistic concurrency happily hopes that such a situation will not occur. As a backup, it uses values from the original row in the WHERE clause: SELECT firstName, lastName, phone, birthDay FROM Customer WHERE id = ? // again, make changes here... this could take a long time UPDATE Customer SET firstName = ?, lastName = ?, phone = ?, birthDay = ? WHERE id = ? AND firstName = ? AND lastName = ? AND phone = ? AND birthDay = ? Under optimistic concurrency, you acquire a lock only when you are actually performing your changes. You still avoid overwriting the changes of another because you match your update against the values you read. If someone else changes the lastName field, then your WHERE clause will not match and the update will fail. Unfortunately, you are still very likely matching against unindexed columns. The approach I use in nearly every database application I write is to create a special column or two to store a value unique to each update. For example, you could use the natural primary key of the table along with a last update timestamp. Each time you modify the database, you modify the last update timestamp and use the old one in your WHERE clause: Connection conn = null;
try {
PreparedStatement stmt;
long ts;
conn = ds.getConnection( );
stmt = conn.prepareStatement("UPDATE Customer " +
"SET firstName = ?, lastName = ?, phone = ?, " +
"birthDay = ?, lastUpdateTS = ? " +
"WHERE id = ? AND lastUpdateTS = ?");
stmt.setString(1, firstName);
stmt.setString(2, lastName);
stmt.setString(3, phone);
stmt.setDate(4, birthDate);
stmt.setLong(5, ts = System.currentTimeMillis( ));
stmt.setInt(6, id);
stmt.setLong(7, lastUpdateTS);
stmt.executeUpdate( );
lastUpdateTS = ts;
}
catch( SQLException e ) {
e.printStackTrace( );
}
finally {
if( conn != null ) {
try { conn.close( ); }
catch( SQLException e ) { }
}
}
Figure 3-4 contrasts how optimistic concurrency prevents this mishap, in contrast to Figure 3-3. Figure 3-4. Optimistic concurrency prevents dirty writes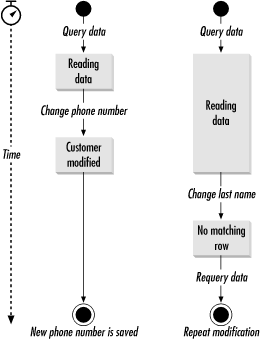 This approach has the advantage of preserving database integrity just like pessimistic concurrency while at the same time minimizing the lifetime of the transaction and guaranteeing that only indexed values are in the WHERE clause. The only true downside is that you are also updating an indexed column, and updates to indexes have their own performance impact.
3.3.3 Batch TransactionsWe have been dealing with transactions in an interactive contextwhere a user is initiating the transaction through some action in a user interface. Complex business systems have not only interactive transactions, but also batch transactions. Batch transactions are sets of transactions that occur on the server independent of user interaction. For example, the monthly process that calculates interest for a savings account is a batch transaction. Until JDBC 2.0, Java was a miserable language for the execution of major batch transactions. Sometimes, people would have processes that needed to execute nightly but took two days to run. The overhead, of course, was partly due to the interpreted nature of Java and the lack of HotSpot VMs (virtual machines) at that time. It was also due to the fact that batch JDBC programming required a lot of back-and-forth between the batch application and the database as well as unnecessary string processing. JDBC 2.0 introduced a batch processing mechanism that addressed the non-VM issues (HotSpot addressed the VM issues). Specifically, JDBC enables you to store multiple statements on the client to be sent over to the database as a groupas a batch. When running that monthly interest process, you previously could send the update for each account to the database only one at a time. Now you can choose to send the updates for all accounts at once, or you can group a bunch of the updates together and send them in waves. As a general rule, the more updates you hold on the client, the faster the batch processing occurs. However, you are limited in the number you can hold by several factors:
The trick is to batch up a reasonable number of updates together. Unfortunately, a reasonable number depends on the amount of RAM available to the application, the size of your database transaction log, the amount of RAM on the database server, and the complexity of any recovery processing. In some situations, it makes sense to batch up 10 updates, while in others 100 or more makes sense. The following code illustrates batching together 10 statements at a time for updating account balances: PreparedStatement stmt;
conn.setAutoCommit(false);
stmt = conn.prepareStatemment("UPDATE account " +
"SET balance = ? " +
"WHERE id = ?");
for(int i=0; i<accts.length; i++) {
int[ ] rows;
while( (i%10 != 9) && (i<accts.length) ) {
accts[i].calculateIntterest( );
stmt.setDouble(1, accts[i].getBalance( ));
stmt.setInt(2, accts[i].getId( ));
stmt.addBatch( );
i++;
}
rows = stmt.executeBatch( );
}
For a more complete discussion of the way JDBC manages batch processing, see the tutorial in Chapter 11. 3.3.4 SavepointsWhile JDBC 2.0 added batch processing to the transaction arsenal of the JDBC programmer, JDBC 3.0 added something called savepoints. Without the benefit of savepoints, JDBC allows for only two possible consistent states in a transaction: the beginning state and the end state. Some transactions, however, may have more than two possible consistent database states. For example, you may have a transaction in which an error condition during processing is itself meaningful to the transaction and thus should cause an alternate flow with an alternate consistent end state.
I honestly have never encountered a situation in business programming in which I felt I needed savepoints. One possible example, however, would be a flexible tool for managing the addition of new users to a web site. On your web site, you probably want to empower users to identify themselves by unique names but you want them to be able to change those names. Because they can change, they make poor candidates for a primary key. Instead, you automatically generate an otherwise meaningless primary key and let them pick meaningful names that are used as a unique index. Of course, it is possible that whatever name a user chooses is already in use. To make the process as simple for the user as possible, you would have the following events in your transaction:
In this example, you could set a savepoint after step 2 and roll back the transaction to that point in the event the chosen username is a duplicate. Using a savepoint, you can guarantee that the user will appear in the new user log under the proper username. Of course, you can avoid the need for savepoints by restructuring this contrived transaction. Nevertheless, it does illustrate the conditional processing inherent in savepoint transactions. The following code shows how it works in practice: Connection conn = null;
try {
// the sequencer generates unique user ID's for us
Sequencer seq = Sequencer.getInstance("userID");
PreparedStatement stmt;
Savepoint sp;
long id;
conn = ds.getConnection( );
conn.setAutoCommit(false);
id = seq.next(conn);
stmt = conn.prepareStatement("INSERT INTO Contact ( userID, email ) " +
"VALUES ( ? , ? )");
stmt.setLong(1, id);
stmt.setString(2, email);
stmt.executeUpdate( );
sp = conn.setSavepoint("contact");
stmt = conn.prepareStatement("INSERT INTO NewUser ( userName, when ) " +
"VALUES ( ?, ? )");
stmt.setString(1, userName);
stmt.setLong(2, System.currentTimeMillis( ));
stmt.executeUpdate( );
stmt = conn.prepareStatement("INSERT INTO Profile ( userID, userName, pass ) "+
"VALUES ( ?, ?, ? )");
stmt.setLong(1, id);
stmt.setString(2, userName);
stmt.setString(3, password);
try {
stmt.executeUpdate( );
}
catch( SQLException e ) {
conn.rollback(sp);
userName = "" + userID;
stmt = conn.prepareStatement("INSERT INTO NewUser ( userName, when ) " +
"VALUES ( ?, ? )");
stmt.setString(1, userName);
stmt.setLong(2, System.currentTimeMillis( ));
stmt.executeUpdate( );
stmt = conn.prepareStatement("INSERT INTO Profile ( userID, userName, " +
"pass ) VALUES ( ?, ?, ? )");
stmt.setLong(1, id);
stmt.setString(2, userName);
stmt.setString(3, password);
stmt.executeUpdate( );
}
}
catch( SQLException e ) {
try { conn.rollback( ); }
catch( SQLException e ) { }
}
finally {
if( conn != null ) {
try { conn.close( ); }
catch( SQLException e ) { }
}
}
|
| [ Team LiB ] |
|
