| [ Team LiB ] |
|
6.2 BMP PatternsThe fundamental philosophy behind bean-managed persistence is that the EJB container manages the components and the transactions while you manage their persistence. The container tells you when interactions with the data store need to take place, and you make those interactions happen. The persistence patterns I described in Chapter 4 are therefore critical to bean-managed persistence. Figure 6-3 places the library business objects from Figure 6-2 into a real world BMP system. Figure 6-3. EJBs in the real world using BMP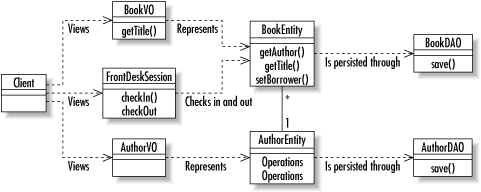 To support three basic concepts, I have added a host of new classes. Some of themsuch as the data access objectsprovide direct support for bean-managed persistence. Otherslike the value objectsare useful to real world EJB applications no matter what persistence model you follow. As you can see from Figure 6-3, programming in an EJB context brings with it a lot of overhead. That overhead is necessary to support large-scale enterprise applications that require clustering, high-availability, and robust transaction management. If you have a fairly simple application, the use of EJBs will make that application unnecessarily complex.
Looking back at Chapter 4, our application model included view logic, controller logic, business logic, data access logic, and data storage logic. As this book is about database programming, we assume the data storage logic is handled by a relational database. EJB does not address the view or controller logic. It is primarily concerned with the business logic. If you are using CMP, it cares about the data access logic. Under BMP, however, you provide the data access logic. In Figure 6-3, the data access objectsBookDAO and AuthorDAOmanage the data access logic. The value objects in Figure 6-3 are not directly related to persistence. They are instead tools to help model entity beans and minimize the overhead that comes with entity beans. Because they do minimize database access, however, they are critical to the proper operation of a persistent EJB system. 6.2.1 Data Access ObjectsI introduced the general concept of data access objects in Chapter 4. In the case of BMP, a data access object is a delegate for an EJB to handle its persistence operations. We can see how this works in practice by combining code from Chapter 4 and Chapter 5. The persistence code under the CMP model for an AuthorBean looked like this: public Long ejbCreate(Long bid, Long aid, String ttl) {
bookID = bid;
authorID = aid;
title= ttl;
return null;
}
public void ejbLoad( ) {
}
public void ejbPassivate( ) {
}
public void ejbPostCreate(Long bid, Long aid, String ttl) {
}
public void ejbRemove( ) {
}
public void ejbStore( ) {
}
The only thing remotely interesting was ejbCreate( ), which assigned initial values to a new bean. We could, of course, add the logic to create the book in the database inside the ejbCreate( ) method: static private final String CREATE =
"INSERT INTO Book ( bookID, authorID, title ) " +
"VALUES ( ?, ?, ? )";
public Long ejbCreate(Long bid, Long aid, String ttl)
throws CreateException {
PreparedStatement stmt = null;
Connection conn = null;
bookID = bid;
authorID = aid;
title = ttl;
try {
Context ctx = new InitialContext( );
DataSource ds = (DataSource)ctx.lookup("jdbc/ora");
conn = ds.getConnection( );
stmt = conn.prepareStatement(CREATE);
stmt.setLong(1, bookID.longValue( ));
stmt.setLong(2, authorID.longValue( ));
stmt.setString(3, title);
if( stmt.executeUpdate( ) != 1 ) {
throw new CreateException("Failed to add book: " + bookID);
}
return bookID;
}
catch( NamingException e ) {
throw new EJBException(e);
}
catch( SQLException e ) {
throw new EJBException(e);
}
finally {
if( stmt != null ) {
try { stmt.close( ); }
catch( SQLException e ) { }
}
if( conn != null ) {
try { conn.close( ); }
catch( SQLException e ) { }
}
}
}
Though this example code works and is the way most books should teach you BMP, it is not how you want to build your beans in real world applications. In order to better divide the work of persistence, it helps to pull the database code out of our entity bean and place it into a data access object. With a data access object in place, the ejbCreate( ) method evolves into something much simpler: static public final String AUTHOR_ID = "authorID";
static public final String BOOK_ID = "bookID";
static public final String TITLE = "title";
public Long ejbCreate(Long bid, Long aid, String ttl)
throws CreateException {
HashMap memento = new HashMap( );
memento.put(BOOK_ID, bookID = bid);
memento.put(AUTHOR_ID, authorID = aid);
memento.put(TITLE, title = ttl);
CommentDAO.create(memento);
return bookID;
}
Each bean-managed EJB has at least four persistence operations. The code for each persistence operation is fairly involved and has little or nothing to do with the business logic that the bean represents. By moving persistence logic into a data access object, we have simplified the bean using a logical division of labor. Maintenance of persistence logic can now occur without requiring changes to the bean, and changes to business logic can now occur without requiring changes to the persistence handlers. If you are wondering what the data access object code looks like for the bean, you are about to get another bonus of following this model: it looks exactly like the data access object from Chapter 4. In other words, using data access objects not only makes the maintenance of your application simpler, it makes it possible to port an application between vastly different component models. Both the data access object and the memento from Chapter 4 combined to give the persistence logic total independence from the business logicand vice versa. Thus, we are not only able to take our persistence logic from the homegrown component model of Chapter 4, we could also take our entity bean from this chapter and write a data access object to store the bean to an object database or a filesystem. 6.2.2 Value ObjectsAs we have already encountered, the distributed paradigm under which entity beans operate represent operational challenges for an EJB system. One of the tools for mitigating this problem is the value objectan object that encapsulates the state of an entity bean for a remote client. Chapter 4 did not work under a distributed programming model. As a result, its components did not face the issues I have presented for entity beans. The component itself was, in a matter of speaking, its own value object. Unfortunately, value objects violate the sensibility of object purists. This clash between object-oriented elegance and real world performance demands has resulted in a variety of approaches to building value objects. Which approach you prefer depends largely on where you sit on the object purity/convenience continuum.
6.2.2.1 Simple value objectsSimple value objects sit strongly on the convenience side of the equation. You've seen the simplest form of a value object in the HashMap memento. Depending on the operation in question, your entity bean can shove the minimum amount of information necessary to support that operation into a HashMap and give it out to clients. One network call provides the client with everything it needs to know about an entity. On the other hand, this approach throws most of the benefits of object-orientation out the window. You get absolutely no type safety and you risk chaos with calculated fields. 6.2.2.2 Complex value objectsComplex value objects basically attempt to be serializable mirrors of their entity bean counterparts. They have all of the methods and some of the business logic supported by the entity bean. As a result, type safety and encapsulation of logic are guaranteed. Unfortunately, complex value objects are difficult to maintain. Any logic around getting and setting values must be maintained in two placesthe entity bean and its value objectand you add yet another class to code for every single business concept you have in your domain model. 6.2.2.3 Other alternativesMany alternatives to these two extremes exist. Examples include:
6.2.3 Sessions as TransactionsValue objects are just one part of insulating entity beans.[1] Another approach is the use of sessions as the gateways into all server-side operations. In essence, any transactionread or writeshould go through a session bean. The session bean thus becomes a transactional business object.
When you think of transactions, you probably conjure up examples of transactions in which you are changing the state of the data store. Some of the most problematic transactions from a pure EJB perspective, however, are read transactions like searches and lookups. 6.2.3.1 SearchesIf you remember the way searching occurs in EJB 1.x, you have to write finder methods for each kind of search you want to support. The finder methods then return collections of matching primary keys. When you want the data for those matching keys, the container will load each of the entities from which you request data. Searching under EJB 1.x is thus problematic for a variety of reasons:
By placing searching logic into a session bean and combining this approach with the use of value objects, you can mitigate most problems. To find all books by Stephen King, we could create a session bean called BookSearch with a method that looks like this: static private final String FIND =
"SELECT title FROM Book WHERE authorID = ?";
public Collection getTitles(Long aid) throws FinderException {
PreparedStatement stmt = null;
Connection conn = null;
ResultSet rs = null;
try {
Context ctx = new InitialContext( );
DataSource ds = (DataSource)ctx.lookup("jdbc/ora");
ArrayList results = new ArrayList( );
conn = ds.getConnection( );
stmt = conn.prepareStatement(FIND);
stmt.setLong(1, aid.longValue( ));
rs = stmt.executeQuery( );
while( rs.next( ) ) {
results.add(rs.getString(1));
}
return results;
}
catch( NamingException e ) {
throw new EJBException(e);
}
catch( SQLException e ) {
throw new EJBException(e);
}
finally {
if( rs != null ) {
try { rs.close( ); }
catch( SQLException e ) { }
}
if( stmt != null ) {
try { stmt.close( ); }
catch( SQLException e ) { }
}
if( conn != null ) {
try { conn.close( ); }
catch( SQLException e ) { }
}
}
}
You still have to write many finder methods to support a variety of needs. Nevertheless, you get the entire overhead associated with entity beans out of the way. A more common approach than simply providing a title would be to provide the minimal information necessary for the client to support a list view plus a primary key. The client can then reference a specific bean by primary key if it wishes to drill down further or execute a write transaction. 6.2.3.2 UpdatesSessions are critical for updates as well as reads. In the context of an update, they help glue together all of the individual entities that are involved in a given transaction. Figure 6-4 shows how a session can be used to "glue together" two bank accounts into a transfer transaction. Figure 6-4. Hiding the details of a transfer behind a session bean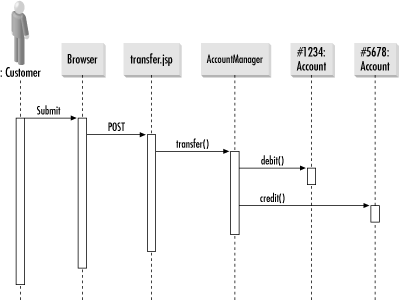 In this example, the client calls a single method, transfer( ) in the AccountManager session bean. That session bean, in turn, modifies the account balances for each account. The entire transaction succeeds or fails together. It is important to note here that, although you are managing the persistence, you are not managing the transactions. While it is possible to manually handle transactions using bean-managed transactions, bean-managed transactions and bean-managed persistence are two distinct concepts. In general, you never want to use bean-managed transactions.
|
| [ Team LiB ] |
|
