| [ Team LiB ] |
|
2.1 LDIFMost system administrators prefer to use plain-text files for server configuration information, as opposed to some binary store of bits. It is more comfortable to deal with data in vi, Emacs, or notepad than to dig though raw bits and bytes. Therefore, it seems fitting to begin an exploration of LDAP internals with a discussion of representing directory data in text form. The LDAP Interchange Format (LDIF), defined in RFC 2849, is a standard text file format for storing LDAP configuration information and directory contents. In its most basic form, an LDIF file is:
The first two characteristics provide exactly what is needed to describe the contents of an LDAP directory. We'll return to the third characteristic when we discuss modifying the information in the directory in Chapter 4. LDIF files are often used to import new data into your directory or make changes to existing data. The data in the LDIF file must obey the schema rules of your LDAP directory. You can think of the schema as a data definition for your directory. Every item that is added or changed in the directory is checked against the schema for correctness. A schema violation occurs if the data does not correspond to the existing rules. Figure 2-1 shows a simple directory information tree. Each entry in the directory is represented by an entry in the LDIF file. Let's begin with the topmost entry in the tree labeled with the distinguished name (DN) dc=plainjoe,dc=org: # LDIF listing for the entry dn: dc=plainjoe,dc=org dn: dc=plainjoe,dc=org objectClass: domain dc: plainjoe Figure 2-1. An LDAP directory tree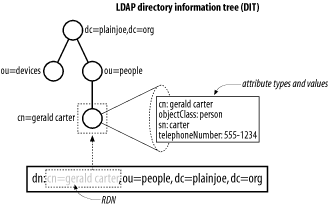 We can make a few observations about LDIF syntax on the basis of this short listing:
2.1.1 Distinguished Names and Relative Distinguished NamesIt is important to realize that the full DN of an entry does not actually need to be stored as an attribute within that entry, even though this seems to be implied by the previous LDIF extract; it can be generated on the fly as needed. This is analogous to how a filesystem is organized. A file or directory does not store the absolute path to itself from the root of the filesystem. Think how hard it would be to move files if this were true. If the DN is like the absolute path between the root of a filesystem and a file, a relative distinguished name (RDN) is like a filename. We've already seen that a DN is formed by stringing together the RDNs of every entity from the element in question to the root of the directory tree. In this sense, an RDN works similarly to a filename. However, unlike a filename, an RDN can be made up of multiple attributes. This is similar to a compound index in a relational database system in which two or more fields are used in combination to generate a unique index key. While a multivalued RDN is not shown in our example, it is not hard to imagine. Suppose that there are two employees named Jane Smith in your company: one in the Sales Department and one in the Engineering Department. Now suppose the entries for these employees have a common parent. Neither the common name (cn) nor the organizational unit (ou) attribute is unique in its own right. However, both can be used in combination to generate a unique RDN. This would look like: # Example of two entries with a multivalued RDN
dn: cn=Jane Smith+ou=Sales,dc=plainjoe,dc=org
cn: Jane Smith
ou: Sales
<...remainder of entry deleted...>
dn: cn=Jane Smith+ou=Engineering,dc=plainjoe,dc=org
cn: Jane Smith
ou: Engineering
<...remainder of entry deleted...>
For both of these entries, the first component of the DN is an RDN composed of two values: cn=Jane Smith+ou=Sales and cn=Jane Smith+ou=Engineering. In the multivalued RDN, the plus character (+) separates the two attribute values used to form the RDN. What if one of the attributes used in the RDN contained the + character? To prevent the + character from being interpreted as a special character, we need to escape it using a backslash (\). The other special characters that require a backslash-escape if used within an attribute value are:
Although multivalued RDNs have their place, using them excessively can become confusing, and can often be avoided by a better namespace design. In the previous example, it is obvious that the multivalued RDN could be avoided by creating different organizationalUnits (ou) in the directory for both Sales and Engineering, as illustrated in Figure 2-2. Using this strategy, the DN for the first entry would be cn=Jane Smith,ou=Sales,dc=plainjoe,dc=org. This design does not entirely eliminate the need for multivalued RDNs; we could still have two people named Jane Smith in the Engineering organization. But that will occur much less frequently than having two Jane Smiths in the company. Look for ways to organize namespaces to avoid multivalued RDNs as much as is possible and logical. Figure 2-2. A namespace that represents Jane Smith with a unique, multivalued RDN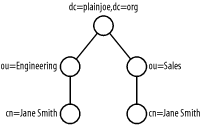 One final note about DNs. RFC 2253 defines a method of unambiguously representing a DN using a UTF-8 string representation. This normalization process boils down to:
Therefore, the normalized version of: cn=gerald carter + ou=sales, dc=plainjoe ,dc=org would be: cn=gerald carter+ou=sales,dc=plainjoe,dc=org Without getting ahead of ourselves, I should mention that the string representation of a distinguished name is normally case-preserving, and the logic used to determine if two DNs are equal is usually a case-insensitive match. Therefore: cn=Gerald Carter,ou=People,dc=plainjoe,dc=org would be equivalent to: cn=gerald carter,ou=people,dc=plainjoe,dc=org However, this case-preserving, case-insensitive behavior is based upon the syntax and matching rules (see Section 2.2 later in this chapter) of the attribute type used in each relative component of the complete DN. So while DNs are often case-insensitive, do not assume that they will always be so. Subsequent examples use the normalized versions of all DNs to prevent confusion, although I may tend to be lax on capitalization. 2.1.2 Back to Our Regularly Scheduled Program . . .Going back to Figure 2-1, your next question is probably, "Where did the extra lines in the LDIF listing come from?" After all, the top entry in Figure 2-1 is simply dc=plainjoe,dc=org. But the LDIF lines corresponding to this entry also contain an objectClass: line and a dc: line. These extra lines provide additional information stored inside each entry. The next few sections answer the following questions:
|
| [ Team LiB ] |
|