| [ Team LiB ] |
|
4.4 When Reference Counting Goes BadReference-counting as a way to manage memory has been around for a long time. The downside of reference counting is that it breaks when the data structure is not a directed graph, in which some parts of the structure point back in to other parts in a looping way. For example, suppose each of two data structures contains a reference to the other (see Figure 4-1): my @data1 = qw(one won); my @data2 = qw(two too to); push @data2, \@data1; push @data1, \@data2; Figure 4-1. When the references in a data structure form a loop, Perl's reference-counting system may not be able to recognize and recycle the no-longer-needed memory space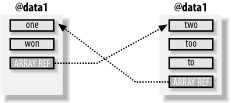 At this point, there are two names for the data in @data1: @data1 itself and @{$data2[3]}, and two names for the data in @data2: @data2 itself and @{$data1[2]}. You've created a loop. In fact, you can access won with an infinite number of names, such as $data1[2][3][2][3][2][3][1]. What happens when these two array names go out of scope? Well, the reference count for the two arrays goes down from two to one. But not zero! And because it's not zero, Perl thinks there might still be a way to get to the data, even though there isn't! Thus, you've created a memory leak. Ugh. (A memory leak in a program causes the program to consume more and more memory over time.) At this point, you're right to think that example is contrived. Of course you would never make a looped data structure in a real program! Actually, programmers often make these loops as part of doubly-linked lists, linked rings, or a number of other data structures. The key is that Perl programmers rarely do so because the most important reasons to use those data structures don't apply in Perl. If you've used other languages, you may have noticed programming tasks that are comparatively easy in Perl. For example, it's easy to sort a list of items or to add or remove items, even in the middle of the list. Those tasks are difficult in some other languages, and using a looped data structure is a common way to get around the language's limitations. Why mention it here? Well, even Perl programmers sometimes copy an algorithm from another programming language. There's nothing inherently wrong with doing this, although it would be better to decide why the original author used a "loopy" data structure and recode the algorithm to use Perl's strengths. Perhaps a hash should be used instead, or perhaps the data should go into an array that will be sorted later. A future version of Perl is likely to use garbage collection in addition to or instead of referencing counting. Until then, you must be careful to not create circular references, or if you do, break the circle before the variables go out of scope. For example, the following code doesn't leak: {
my @data1 = qw(one won);
my @data2 = qw(two too to);
push @data2, \@data1;
push @data1, \@data2;
... use @data1, @data2 ...
# at the end:
@data1 = ( );
@data2 = ( );
}
You have eliminated the reference to @data2 from within @data1, and vice versa. Now the data has only one reference each, which are returned to zero references at the end of the block. In fact, you can clear out either one and not the other, and it still works nicely. Chapter 10 shows how to create weak references, which can help with many of these problems. |
| [ Team LiB ] |
|