| [ Team LiB ] |
|
6.2 Web Services FrameworkWeb services combine the best of both distributed componentization and the World Wide Web, extending distributed computing to broader ranges of client applications. The best thing is that this is done by seamlessly marrying and enhancing existing technologies. 6.2.1 Web Services ArchitectureWeb services are distributed software components accessible through standard web protocols. The first part of the definition is similar to that for COM/DCOM components. However, it is the second part that distinguishes web services from the crowd. Web services enable software to interoperate with a much broader range of clients. While COM-aware clients can understand only COM components, web services can be consumed by any application that understands how to parse an XML-formatted stream transmitted through HTTP channels. XML is the key technology used in web services and is used in the following areas of the Microsoft .NET web services framework:
Figure 6-1 depicts the architecture of web applications using Windows DNA, while Figure 6-2 shows .NET-enabled web applications architecture. As you can see, communication between components of a web application does not have to be within an intranet. Furthermore, intercomponent communication can also use HTTP/XML. Figure 6-1. Windows Distributed interNet Architecture (DNA)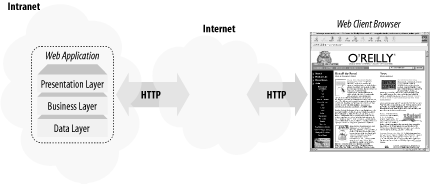 Figure 6-2. .NET-enabled web application framework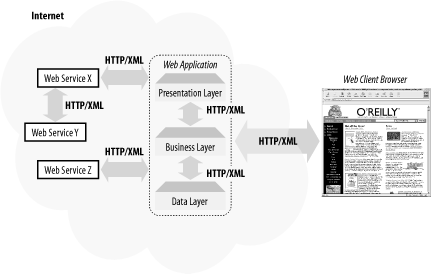 6.2.2 Web Services Wire FormatsYou may have heard the phrase "DCOM is COM over the wire." Web services are similar to DCOM except that the wire is no longer a proprietary communication protocol. With web services, the wire formats rely on more open Internet protocols such as HTTP or SMTP. A web service is more or less a stateless component running on the web server, exposed to the world through standard Internet protocols. Microsoft .NET web services currently supports three protocols: HTTP GET, HTTP POST, and SOAP over HTTP (Simple Object Access Protocol), explained in the next sections. Because these protocols are standard protocols for the Web, it is very easy for the client applications to use the services provided by the server. 6.2.2.1 HTTP GET and HTTP POSTAs their names imply, both HTTP GET and HTTP POST use HTTP as their underlying protocol. The GET and POST methods of the HTTP protocol have been widely used in ASP (Active Server Pages), CGI, and other server-side architectures for many years now. Both of these methods encode request parameters as name/value pairs in the HTTP request. The GET method creates a query string and appends it to the script's URL on the server that handles the request. For the POST method, the name/value pairs are passed in the body of the HTTP request message. 6.2.2.2 SOAPSimilar to HTTP GET and HTTP POST, SOAP serves as a mechanism for passing messages between the clients and servers. In this context, the clients are web services consumers, and the servers are the web services. The clients simply send an XML-formatted request message to the server to get the service over an HTTP channel. The server responds by sending back yet another XML-formatted message. The SOAP specification describes the format of these XML requests and responses. It is simple, yet it is extensible, because it is based on XML. SOAP is different than HTTP GET and HTTP POST because it uses XML to format its payload. The messages being sent back and forth have a better structure and can convey more complex information compared to simple name/value pairs in HTTP GET/POST protocols. Another difference is that SOAP can be used on top of other transport protocols, such as SMTP in addition to HTTP.[1]
6.2.3 Web Services Description (WSDL)For web service clients to understand how to interact with a web service, there must be a description of the method calls, or the interface that the web service supports. This web service description document is found in an XML schema called Web Services Description Language (WSDL). Remember that type libraries and IDL scripts are used to describe a COM component. Both IDL and WSDL files describe an interface's method calls and the list of in and out parameters for the particular call. The only major difference between the two description languages is that all descriptions in the WSDL file are done in XML. In theory, any WSDL-capable SOAP client can use the WSDL file to get a description of your web service. It can then use the information contained in that file to understand the interface and invoke your web service's methods. 6.2.3.1 WSDL structureThe root of any web service description file is the <definitions> element. Within this element, the following elements provide both the abstract and concrete description of the service:
The following shows a typical WSDL file structure: <definitions name="" targetNamespace="" xmlns: . . . >
<types> . . . </types>
<message name=""> . . . </message>
. . .
<portType name="">
<operation name="">
<input message="" />
<output message="" />
</operation>
. . .
</portType>
. . .
<binding name="">
<protocol:binding . . . >
<operation name="">
<protocol:operation . . . >
<input> . . . </input>
<output> . . . </output>
</operation>
. . .
</binding>
. . .
<service name="">
<port name="" binding="">
<protocol:address location="" />
</port>
. . .
</service>
</definitions>
The <types> element contains physical type descriptions defined in XML Schema (XSD). These types are being referred to from the <message> elements. For each of the web methods in the web service, there are two messages defined for a particular port: input and output. This means if a web service supports all three protocols: SOAP, HTTP GET, and HTTP POST, there will be six <message> elements defined, one pair for each port. The naming convention used by the Microsoft .NET autogenerated WSDL is: MethodName + Protocol + {In, Out}
For example, a web method called GetBooks( ) has the following messages: <message name="GetBooksSoapIn"> . . . </message> <message name="GetBooksSoapOut"> . . . </message> <message name="GetBooksHttpGetIn"> . . . </message> <message name="GetBooksHttpGetOut"> . . . </message> <message name="GetBooksHttpPostIn"> . . . </message> <message name="GetBooksHttpPostOut"> . . . </message> For each protocol that the web service supports, there is one <portType> element defined. Within each <portType> element, all operations are specified as <operation> elements. The naming convention for the port type is: WebServiceName + Protocol To continue our example, here are the port types associated with the web service that we build later in this chapter, PubsWS: <portType name="PubsWSSoap">
<operation name="GetBooks">
<input message="GetBooksSoapIn" />
<output message="GetBooksSoapOut" />
</operation>
</portType>
<portType name="PubsWSHttpGet">
<operation name="GetBooks">
<input message="GetBooksHttpGetIn" />
<output message="GetBooksHttpGetOut" />
</operation>
</portType>
<portType name="PubsWSHttpPost">
<operation name="GetBooks">
<input message="GetBooksHttpPostIn" />
<output message="GetBooksHttpPostOut" />
</operation>
</portType>
We have removed namespaces from the example to make it easier to read. While the port types are abstract operations for each port, the bindings provide concrete information on what protocol is being used, how the data is being transported, and where the service is located. Again, there is a <binding> element for each protocol supported by the web service: <binding name="PubsWSSoap" type="s0:PubsWSSoap">
<soap:binding transport="http://schemas.xmlsoap.org/soap/http"
style="document" />
<operation name="GetBooks">
<soap:operation soapAction="http://tempuri.org/GetBooks"
style="document" />
<input>
<soap:body use="literal" />
</input>
<output>
<soap:body use="literal" />
</output>
</operation>
</binding>
<binding name="PubsWSHttpGet" type="s0:PubsWSHttpGet">
<http:binding verb="GET" />
<operation name="GetBooks">
<http:operation location="/GetBooks" />
<input>
<http:urlEncoded />
</input>
<output>
<mime:mimeXml part="Body" />
</output>
</operation>
</binding>
<binding name="PubsWSHttpPost" type="s0:PubsWSHttpPost">
<http:binding verb="POST" />
<operation name="GetBooks">
<http:operation location="/GetBooks" />
<input>
<mime:content type="application/x-www-form-urlencoded" />
</input>
<output>
<mime:mimeXml part="Body" />
</output>
</operation>
</binding>
For SOAP protocol, the binding is <soap:binding>, and the transport is SOAP messages on top of HTTP protocol. The <soap:operation> element defines the HTTP header soapAction, which points to the web method. Both input and output of the SOAP call are SOAP messages. For the HTTP GET and HTTP POST protocols, the binding is <http:binding> with the verb being GET and POST, respectively. Because the GET and POST verbs are part of the HTTP protocol, there is no need for the extended HTTP header (like soapAction for SOAP protocol). The only thing we need is the URL that points to the web method; in this case, the <soap:operation> element contains the attribute location, which is set to /GetBooks. The only real difference between the HTTP GET and POST protocols is the way the parameters are passed to the web server. HTTP GET sends the parameters in the query string, while HTTP POST sends the parameters in the form data. This difference is reflected in the <input> elements of the operation GetBooks for the two HTTP protocols. For the HTTP GET protocol, the input is specified as <http:urlEncoded />, whereas for the HTTP POST protocol, the input is <mime:content type="application/x-www-form-urlencoded" />. Looking back at the template of the WSDL document, we see that the only thing left to discuss is the <service> element, which defines the ports supported by this web service. For each of the supported protocol, there is one <port> element: <service name="PubsWS">
<port name="PubsWSSoap" binding=s0:PubsWSSoap">
<soap:address
location="http:// . . . /PubsWs.asmx" />
</port>
<port name="PubsWSHttpGet" binding="s0:PubsWSHttpGet">
<http:address
location="http:// . . . /PubsWs.asmx" />
</port>
<port name="PubsWSHttpPost" binding="s0:PubsWSHttpPost">
<http:address
location="http:// . . . /PubsWs.asmx" />
</port>
</service>
Even though the three different ports look similar, their binding attributes associate the address of the service with a binding element defined earlier. Web service clients now have enough information on where to access the service, through which port to access the web service method, and how the communication messages are defined. Although it is possible to read the WSDL and manually construct the HTTP[2] conversation with the server to get to a particular web service, there are tools that autogenerate client-side proxy source code to do the same thing. We show such a tool in "web services Consumers" later in this chapter.
6.2.4 Web Services DiscoveryEven though advertising of a web service is important, it is optional. Web services can be private as well as public. Depending on the business model, some business-to-business (B2B) services would not normally be advertised publicly. Instead, the web service owners would provide specific instructions on accessing and using their service only to the business partner. To advertise web services publicly, authors post discovery files on the Internet. Potential web services clients can browse to these files for information about how to use the web servicesthe WSDL. Think of it as the yellow pages for the web service. All it does is point you to where the actual web services reside and to the description of those web services. The process of looking up a service and checking out the service description is called web service discovery. Currently in .NET, there are two ways of advertising the service: static and dynamic. In both of these, XML conveys the locations of web services. 6.2.4.1 Static discoveryStatic discovery is easier to understand because it is explicit in nature. If you want to advertise your web service, you must explicitly create the .disco discovery file and point it to the WSDL.[3]
All .disco files contain a root element discovery, as shown in the following code sample. Note that discovery is in the namespace http://schemas.xmlsoap.org/disco/, which is referred to as disco in this sample. <?xml version="1.0" ?> <disco:discovery xmlns:disco="http://schemas.xmlsoap.org/disco/"> </disco:discovery> Inside the discovery element, there can be one or more of contractRef or discoveryRef elements. Both of these elements are described in the namespace http://schemas.xmlsoap.org/disco/scl/. The contractRef tag is used to reference an actual web service URL that would return the WSDL or the description of the actual web service contract. The discoveryRef tag, on the other hand, references another discovery document. This XML document contains a link to one web service and a link to another discovery document: <?xml version="1.0" ?>
<disco:discovery
xmlns:disco="http://schemas.xmlsoap.org/disco/"
xmlns:scl="http://schemas.xmlsoap.org/disco/scl/">
<scl:contractRef ref="http://yourWebServer/yourWebService.asmx?WSDL"/>
<scl:discoveryRef ref="http://yourBrotherSite/hisWebServiceDirectory.disco"/>
</disco:discovery>
This sample disco file specifies two different namespaces: disco, which is a nickname for the namespace http://schemas.xmlsoap.org/disco/; and scl, short for http://schemas.xmlsoap.org/disco/scl/. The contractRef element specifies the URL where yourWebService WSDL can be obtained. Right below that is the discoveryRef element, which links to the discovery file on yourBrotherSite web site. This linkage allows for structuring networks of related discovery documents. 6.2.4.2 Dynamic discoveryAs opposed to explicitly specifying the URL for all web services your site supports, you can enable dynamic discovery, which enables all web services underneath a specific URL on your web site to be listed automatically. For your web site, you might want to group related web services under many different directories and then provide a single dynamic discovery file in each of the directories. The root tag of the dynamic discovery file is dynamicDiscovery instead of discovery: <?xml version="1.0" encoding="utf-8"?> <dynamicDiscovery xmlns="urn://schemas-dynamic:disco.2000-03-17" /> You can optionally specify exclude paths so that the dynamic mechanism does not have to look for web services in all subdirectories underneath the location of the dynamic discovery file. Exclude paths are in the following form: <exclude path="pathname" /> If you run IIS as your web server, you'd probably have something like the following for a dynamic discovery file:[4]
<?xml version="1.0" encoding="utf-8"?>
<dynamicDiscovery xmlns="urn://schemas-dynamic:disco.2000-03-17">
<exclude path="_vti_cnf" />
<exclude path="_vti_pvt" />
<exclude path="_vti_log" />
<exclude path="_vti_script" />
<exclude path="_vti_txt" />
<exclude path="Web References" />
</dynamicDiscovery>
6.2.4.3 Discovery setting in practiceA combination of dynamic and static discovery makes a very flexible configuration. For example, you can provide static discovery documents at each of the directories that contain web services. At the root of the web server, provide a dynamic discovery document with links to all static discovery documents in all subdirectories. To exclude web services from public viewing, provide the exclude argument to XML nodes to exclude their directories from the dynamic discovery document. 6.2.4.4 UDDIUniversal Description, Discovery, and Integration (UDDI) Business Registry is like a yellow pages of web services. It allows businesses to publish their services and locate web services published by partner organizations so that they can conduct transactions quickly, easily, and dynamically with their trading partner. Through UDDI APIs, businesses can find services over the web that match their criteria (e.g., cheapest fare), that offer the service they request (e.g., delivery on Sunday), and so on. Currently backed by software giants such as Microsoft, IBM, and Ariba, UDDI is important to web services because it enables access to businesses from a single place.[5]
6.2.5 The System.Web.Services NamespaceNow that we have run through the basic framework of Microsoft .NET web services, let us take a look inside what the .NET SDK provides us in the System.Web.Services namespace. There are only a handful of classes in the System.Web.Services namespace and the most important ones for general use are:
The two essential classes for creating web services are the WebService base class and WebMethodAttribute. We make use of these classes in the next section, where we implement a web service provider and several web service consumers. WebService is the base class from which all web services inherit. It provides properties inherent to legacy ASP programming such as Application, Server, Session, and a new property, Context, which now includes Request and Response. The WebMethodAttribute class allows you to apply attributes to each public method of your web service. Using this class, you can assign specific values to the following attributes: description, session state enabling flag, message name, transaction mode, and caching. See the following section for an example of attribute setting in C# and VB. The WebServiceAttribute class is used to provide more attributes about the web service itself. You can display a description of the web service, as well as the namespace to which this web service belongs. |
| [ Team LiB ] |
|