| [ Team LiB ] |
|
2.2 XmlReaderXmlReader is an abstract base class that provides an event-based, read-only, forward-only XML pull parser (I'll discuss each of these terms shortly). XmlReader has three concrete subclasses, XmlTextReader, XmlValidatingReader, and XmlNodeReader, which enable you to read XML from a file, a Stream, or an XmlNode. You can also extend XmlReader to read other, non-XML data formats, and deal with them as if they were XML (you'll learn how to do this in Chapter 4). The base XmlReader provides only the most essential functionality for reading XML documents. It does not, for example, validate XML (that's what XmlValidatingReader does) or expand XML entities into their respective character data (though XmlTextReader does). This does not mean that XML read from a text file cannot be validated at all; you can validate XML from any source by using the XmlValidatingReader constructor that takes an XmlReader object as a parameter, as I'll demonstrate. Here are those four terms I used to describe XmlReader again, with a little explanation.
2.2.1 Pull Parser Versus Push ParserIn many ways, XmlReader is analogous to the Simple API for XML (SAX). They both work by reporting events to the client. There is one major difference between XmlReader and a SAX parser, however. While SAX implements a push parser model, XmlReader is a pull parser.
In a push parser, events are pushed to you. Typically, a push parser requires you to register a callback method to handle each event. As the parser reads data, the callback method is dispatched as each appropriate event occurs. Control remains with the parser until the end of the document is reached. Since you don't have control of the parser, you have to maintain knowledge of the parser's state so your callback knows the context from which it has been called. For example, in order to decide on a particular action, you may need to know how deep you are in an XML tree, or be able to locate the parent of the current element. Figure 2-1 shows the flow of events in a push parser model application. Figure 2-1. Push parser model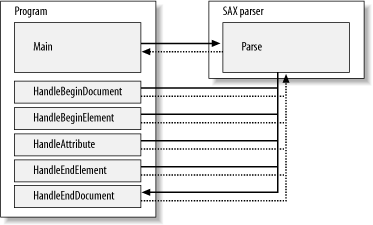 In a pull parser, your code explicitly pulls events from the parser. Running in an event loop, your code requests the next event from the parser. Because you control the parser, you can write a program with well-defined methods for handling specific events, and even completely skip over events you are not interested in. Figure 2-2 shows the flow of events in a pull parser model application. Figure 2-2. Pull parser model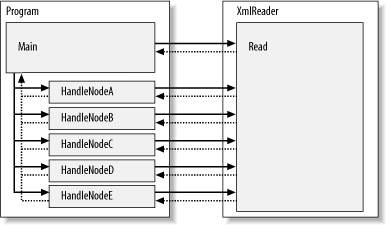 A pull parser also enables you to write your client code as a recursive descent parser. This is a top-down approach in which the parser (XmlReader, in this case) is called by one or more methods, depending on the context. The recursive descent model is also known as mutual recursion. A neat feature of recursive descent parsers is that the structure of the parser code usually mirrors that of the data stream being parsed. As you'll see later in this chapter, the structure of a program using XmlReader can be very similar to the structure of the XML document it reads. 2.2.2 When to Use XmlReaderSince XmlReader is a read-only XML parser, you should use it when you need to read an XML file or stream and convert it into a data structure in memory, or when you need to output it into another file or stream. Because it is a forward-only XML parser, XmlReader may be used only to read data from beginning to end. These qualities combine to make XmlReader very efficient in its use of memory; only the minimum amount of data required is held in memory at any given time. Although you can use XmlReader to read XML to be consumed by one of .NET's implementations of DOM, XML Schema, or XSLT (each of which is discussed in later chapters), it's usually not necessary, as each of these types provides its own mechanism for reading XMLusually using XmlReader internally themselves! On the other hand, XmlReader can be a useful building block in an application that needs to manipulate XML data in ways not supported directly by a .NET type. For example, to create a SAX implementation for .NET, you could use XmlReader to read the XML input stream, just as other .NET XML types, such as XmlDocument, do. You can also extend XmlReader to provide a read-only XML-style interface to data that is not formatted as XML; indeed, I'll show you how to do just that in Chapter 4. The beauty of using XmlReader for non-XML data is that once you've written the code to respond to XmlReader events, handling a different format is a simple matter of dropping in a specialized, format-specific XmlReader without having to rewrite your higher-level code. This technique also allows you to use a DTD or XML Schema to validate non-XML data, using the XmlValidatingReader. 2.2.3 Using the XmlReaderThe .NET Framework provides three implementations of XmlReader: XmlTextReader, XmlValidatingReader, and XmlNodeReader. In this section, I'll present each class one at a time and show you how to use them. 2.2.3.1 XmlTextReaderXmlTextReader is the most immediately useful specialization of XmlReader. XmlTextReader is used to read XML from a Stream, URL, string, or TextReader. You can use it to read XML from a text file on disk, from a web site, or from a string in memory that has been built or loaded elsewhere in your program. XmlTextReader does not validate the XML it reads; however, it does expand the general entities <, >, and & into their text representations (<, >, and &, respectively), and it does check the XML for well-formedness. In addition to these general capabilities, XmlTextReader can resolve system- and user-defined entities, and can be optimized somewhat by providing it with an XmlNameTable. Although XmlNameTable is an abstract class, you can instantiate a new NameTable, or access an XmlReader's XmlNameTable through its NameTable property.
Like many businesses, Angus Hardwarethe hardware store I introduced in the prefaceissues and processes purchase orders (POs) to help manage its finances and inventory. Being technically savvy, the company IT crew has created an XML format for Angus Hardware POs. Example 2-1 lists the XML for po1456.xml, a typical purchase order. I'll use this document in the rest of the examples in this chapter, and some of the later examples in the book. Example 2-1. A purchase order in XML format<?xml version="1.0"?>
<po id="PO1456">
<date year="2002" month="6" day="14" />
<address type="shipping">
<name>Frits Mendels</name>
<street>152 Cherry St</street>
<city>San Francisco</city>
<state>CA</state>
<zip>94045</zip>
</address>
<address type="billing">
<name>Frits Mendels</name>
<street>PO Box 6789</street>
<city>San Francisco</city>
<state>CA</state>
<zip>94123-6798</zip>
</address>
<items>
<item quantity="1"
productCode="R-273"
description="14.4 Volt Cordless Drill"
unitCost="189.95" />
<item quantity="1"
productCode="1632S"
description="12 Piece Drill Bit Set"
unitCost="14.95" />
</items>
</po>
Angus Hardware's fulfillment department, the group responsible for pulling products off of shelves in the warehouse, has not yet upgraded, unfortunately, to the latest laser printers and hand-held bar-code scanners. The warehouse workers prefer to receive their pick lists as plain text on paper. Since the order entry department produces its POs in XML, the IT guys propose to transform their existing POs into the pick list format preferred by the order pickers. Here's the pick list that the fulfillment department prefers: Angus Hardware PickList
=======================
PO Number: PO1456
Date: Friday, June 14, 2002
Shipping Address:
Frits Mendels
152 Cherry St
San Francisco, CA 94045
Quantity Product Code Description
======== ============ ===========
1 R-273 14.4 Volt Cordless Drill
1 1632S 12 Piece Drill Bit Set
You'll note that while the pick list layout is fairly simple, it does require some formatting; Quantity and Product Code numbers need to be right-aligned, for example. This is a good job for an XmlReader, because you really don't need to manipulate the XML, but just read it in and transform it into the desired text layout. (You could do this with an XSLT transform, but that solution comes later in Chapter 7!) Example 2-2 shows the Main( ) method of a program that reads the XML purchase order listed in Example 2-1 and transforms it into a pick list. Example 2-2. A program to transform an XML purchase order into a printed pick listusing System;
using System.IO;
using System.Xml;
public class PoToPickList {
public static void Main(string[ ] args) {
string url = args[0];
XmlReader reader = new XmlTextReader(url);
StringBuilder pickList = new StringBuilder( );
pickList.Append("Angus Hardware PickList").Append(Environment.NewLine);
pickList.Append("=======================").Append(Environment.NewLine).Append
(Environment.NewLine);
while (reader.Read( )) {
if (reader.NodeType == XmlNodeType.Element) {
switch (reader.LocalName) {
case "po":
pickList.Append(POElementToString(reader));
break;
case "date":
pickList.Append(DateElementToString(reader));
break;
case "address":
reader.MoveToAttribute("type");
if (reader.Value == "shipping") {
pickList.Append(AddressElementToString(reader));
} else {
reader.Skip( );
}
break;
case "items":
pickList.Append(ItemsElementToString(reader));
break;
}
}
}
Console.WriteLine(pickList);
}
}
Let's look at the Main( ) method in Example 2-2 in small chunks, and then we'll dive into the rest of the program. XmlReader reader = new XmlTextReader(url); This line instantiates a new XmlTextReader object, passing in a URL, and assigns the object reference to an XmlReader variable. If the URL uses the http or https scheme, the XmlTextReader will take care of creating a network connection to the web site. If the URL uses the file scheme, or has no scheme at all, the XmlTextReader will read the file from disk. Because the XmlTextReader uses the System.IO classes we discussed earlier, it does not currently recognize any other URL schemes, such as ftp or gopher: StringBuilder pickList = new StringBuilder( );
pickList.Append("Angus Hardware PickList").Append(Environment.NewLine);
pickList.Append("=======================").Append(Environment.NewLine) .Append
(Environment.NewLine);
These lines instantiate a StringBuilder object that will be used to build a string containing the text representation of the pick list. We initialize the StringBuilder with a simple page header.
while (reader.Read( )) {
if (reader.NodeType == XmlNodeType.Element) {
This event loop is the heart of the code. Each time Read( )is called, the XML parser moves to the next node in the XML file. Read( ) returns true if the read was successful, and false if it was notsuch as at the end of the file. The expression within the if statement ensures that you don't try to evaluate an EndElement node as if it were an Element node; that would result in two calls to each method, one as the parser reads an Element and one as it reads an EndElement. XmlReader.NodeType returns an XmlNodeType. Now that you have read a node, you need to determine its name: switch (reader.LocalName) {
The LocalName property contains the name of the current node with its namespace prefix removed. A Name property that contains the name as well as its namespace prefix, if it has one, is also available. The namespace prefix itself can be retrieved with the XmlReader type's Prefix property: case "po":
pickList.Append(POElementToString(reader));
break;
case "date":
pickList.Append(DateElementToString(reader));
break;
case "address":
reader.MoveToAttribute("type");
if (reader.Value == "shipping") {
pickList.Append(AddressElementToString(reader));
} else {
reader.Skip( );
}
break;
case "items":
pickList.Append(ItemsElementToString(reader));
break;
For each element name, the program calls a specific method to parse its subnodes; this demonstrates the concept of recursive descent parsing, which I discussed earlier. One element of the XML tree, address, is of particular interest. The fulfillment department doesn't care who's paying for the order, only to whom the order is to be shipped. Since the Angus Hardware order pickers are only interested in shipping addresses, the program checks the value of the type attribute before calling AddressElementToString( ). If the address is not a shipping address, the program calls Skip( ) to move the parser to the next sibling of the current node. To read in the po element, the program calls the POElementToString( ) method. Here's the definition of that method: private static string POElementToString(XmlReader reader) {
string id = reader.GetAttribute("id");
StringBuilder poBlock = new StringBuilder( );
poBlock.Append("PO Number: ").Append(id).Append(Environment.NewLine).Append
(Environment.NewLine);
return poBlock.ToString( );
}
The first thing this method does is to get the id attribute. The GetAttribute( ) method returns an attribute from the current node, if the current node is an element; otherwise, it returns string.Empty. It does not move the current position of the parser to the next node. After it gets the id, POElementToString( ) can then return a properly formatted line for the pick list. Next, the code looks for any date elements and calls DateElementToString( ): private static string DateElementToString(XmlReader reader) {
int year = Int32.Parse(reader.GetAttribute("year"));
int month = Int32.Parse (reader.GetAttribute("month"));
int day = Int32.Parse (reader.GetAttribute("day"));
DateTime date = new DateTime(year,month,day);
StringBuilder dateBlock = new StringBuilder( );
dateBlock.Append("Date: ").Append(date.ToString("D")).Append(Environment.NewLine) .Append
(Environment.NewLine);
return dateBlock.ToString( );
}
This method uses Int32.Parse( ) to convert strings as read from the date element's attributes into int variables suitable for passing to the DateTime constructor. Next, you can format the date as required. Finally, the method returns the properly formatted date line for the pick list: private static string AddressElementToString(XmlReader reader) {
StringBuilder addressBlock = new StringBuilder( );
addressBlock.Append("Shipping Address:\n");
while (reader.Read( ) && (reader.NodeType == XmlNodeType.Element || reader.NodeType == XmlNodeType.Whitespace)) {
switch (reader.LocalName) {
case "name":
case "company":
case "street":
case "zip":
addressBlock.Append(reader.ReadString( ));
addressBlock.Append(Environment.NewLine);
break;
case "city":
addressBlock.Append(reader.ReadString( ));
addressBlock.Append(", ");
break;
case "state":
addressBlock.Append(reader.ReadString( ));
addressBlock.Append(" ");
break;
}
}
addressBlock.Append("\n");
return addressBlock.ToString( );
}
Much like the Main( ) method of the program, AddressElementToString( ) reads from the XML file using a while loop. However, because you know the method starts at the address element, the only nodes it needs to traverse are the subnodes of address. In the cases of name, company, street, and zip, AddressElementToString( ) reads the content of each element and appends a newline character. The program must deal with the city and state elements slightly differently, however. Ordinarily, a city is followed by a comma, a state name, a space, and a zip code. Then, the program returns the properly formatted address line. Now we come to the most complex method, ItemsElementToString( ). Its complexity lies not in its reading of the XML, but in its formatting of the output: private static string ItemsElementToString(XmlReader reader) {
StringBuilder itemsBlock = new StringBuilder( );
itemsBlock.Append("Quantity Product Code Description\n");
itemsBlock.Append("======== ============ ===========\n");
while (reader.Read( ) && (reader.NodeType == XmlNodeType.Element || reader.NodeType == XmlNodeType.Whitespace)) {
switch (reader.LocalName) {
case "item":
intquantity = Int32.Parse(
reader.GetAttribute("quantity"));
stringproductcode = reader.GetAttribute("productCode");
stringdescription = reader.GetAttribute("description");
itemsBlock.AppendFormat(" {0,6} {1,11} {2}",
quantity,productCode,description).Append(Environment.NewLine);
break;
}
}
return itemsBlock.ToString( );
}
The ItemsElementToString( ) method makes use of the AppendFormat( ) method of the StringBuilder object. This is not the proper place for a full discussion of .NET's string-formatting capabilities, but suffice it to say that each parameter in the format string is replaced with the corresponding element of the parameter array, and padded to the specified number of digits. For additional information on formatting strings in C#, see Appendix B of C# In A Nutshell, by Peter Drayton, Ben Albahari, and Ted Neward (O'Reilly). This program makes some assumptions about the incoming XML. For example, it assumes that in order for the output to be produced correctly, the elements must appear in a very specific order. It also assumes that certain elements will always occur, and that others are optional. The XmlTextReader cannot always handle exceptions to these assumptions, but the XmlValidatingReader can. To ensure that an unusable pick list is not produced, you should always validate the XML before doing any processing. 2.2.3.2 XmlValidatingReaderXmlValidatingReader is a specialized implementation of XmlReader that performs validation on XML as it reads the incoming stream. The validation may be done by explicitly providing a Document Type Declaration (DTD), an XML Schema, or an XML-Data Reduced (XDR) Schemaor the type of validation may be automatically determined from the document itself. XmlValidatingReader may read data from a Stream, a string, or another XmlReader. This allows you, for example, to validate XML from XmlNode using XmlTextReader, which does not perform validation itself. Validation errors are raised either through an event handler, if one is registered, or by throwing an exception. The following examples will show you how to validate the Angus Hardware purchase order using a DTD. Validating XML with an XML Schema instead of a DTD will give you even more control over the data format, but I'll talk about that topic in Chapter 8. Example 2-3 shows the DTD for the sample purchase order. Example 2-3. The DTD for Angus Hardware purchase orders<?xml version="1.0" encoding="UTF-8"?>
<!ELEMENT po (date,address+,items)>
<!ATTLIST po id ID #REQUIRED>
<!ELEMENT date EMPTY>
<!ATTLIST date year CDATA #REQUIRED
month (1|2|3|4|5|6|7|8|9|10|11|12) #REQUIRED
day (1|2|3|4|5|6|7|8|9|10|11|
12|13|14|15|16|17|18|19|
20|21|22|23|24|25|26|27|
28|29|30|31) #REQUIRED>
<!ELEMENT address (name,company?,street+,city,state,zip)>
<!ATTLIST address type (billing|shipping) #REQUIRED>
<!ELEMENT name (#PCDATA)>
<!ELEMENT company (#PCDATA)>
<!ELEMENT street (#PCDATA)>
<!ELEMENT city (#PCDATA)>
<!ELEMENT state (#PCDATA)>
<!ELEMENT zip (#PCDATA)>
<!ELEMENT items (item)+>
<!ELEMENT item EMPTY>
<!ATTLIST item quantity CDATA #REQUIRED
productCode CDATA #REQUIRED
description CDATA #REQUIRED
unitCost CDATA #REQUIRED>
To validate the XML with this DTD, you must make one small change to the XML document, and one to the code that reads it. To the XML you must add the following document type declaration after the XML declaration (<?xml version="1.0"?>) so that the validator knows what DTD to validate against. <!DOCTYPE po SYSTEM "po.dtd">
In the code that processes the XML, you must also create a new XmlValidatingReader to wrap the original XmlTextReader: XmlReader textReader = new XmlTextReader(url); XmlValidatingReader reader = new XmlValidatingReader(textReader); By default, XmlValidatingReader automatically detects the document's validation type, although you can also set the validation type manually using XmlValidatingReader's ValidationType property: reader.ValidationType = ValidationType.DTD; Unfortunately, if you take this approach, you'll find that errors are not handled gracefully. For example, if you add an address of type="mailing" to the XML document and attempt to validate it, the following exception is thrown: Unhandled Exception: System.Xml.Schema.XmlSchemaException: The 'type' attribute has an invalid value according to its data type. An error occurred at file:///C:/Chapter 2/po1456.xml(16, 12). at System.Xml.XmlValidatingReader.InternalValidationCallback(Object sender, ValidationEventArgs e) at System.Xml.Schema.Validator.SendValidationEvent(XmlSchemaException e, XmlSeverityType severity) at System.Xml.Schema.Validator.ProcessElement( ) at System.Xml.Schema.Validator.Validate( ) at System.Xml.Schema.Validator.Validate(ValidationType valType) at System.Xml.XmlValidatingReader.ReadWithCollectTextToken( ) at System.Xml.XmlValidatingReader.Read( ) at PoToPickListValidated.Main(String[ ] args) Obviously, you'd like to handle exceptions more cleanly than this. You have two options: you can wrap the entire parse tree in a try...catch block, or you can set the XmlValidatingReader object's ValidationEventHandler delegate. Since I assume that you already know how to write a try...catch block, let's explore a solution that uses a ValidationEventHandler. ValidationEventHandler is a type found in the System.Xml.Schema namespace, so you'll need to first add this line to the top of your code: using System.Xml.Schema; Next, add the following line after you instantiate the XmlValidatingReader and set the ValidationType to ValidationType.DTD: reader.ValidationEventHandler += new ValidationEventHandler(HandleValidationError); This step registers the callback for validation errors. Now, you're ready to actually create a ValidationEventHandler. The signature of the delegate as defined by the .NET Framework is: public delegate void ValidationEventHandler( object sender, ValidationEventArgs e ); Your validation event handler must match that signature. For now, you can just write the error message to the console: private static void HandleValidationError(
object sender, ValidationEventArgs e) {
Console.WriteLine(e.Message);
}
Now, if you run the purchase order conversion program using the invalid XML file I talked about earlier, the following slightly more informative message will print to the console: 'mailing' is not in the enumeration list. An error occurred at file:///C:/Chapter 2/po1456.xml(16, 12).
I'm sure you can think of useful ways to use a validation event. Some examples of useful output that I've thought of include:
The entire revised program is shown in Example 2-4. Example 2-4. Complete program for converting an Angus Hardware XML purchase order to a pick listusing System;
using System.IO;
using System.Text;
using System.Xml;
using System.Xml.Schema;
public class PoToPickListValidated {
public static void Main(string[ ] args) {
string url = args[0];
XmlReader textReader = new XmlTextReader(url);
XmlValidatingReader reader = new XmlValidatingReader(textReader);
reader.ValidationType = ValidationType.DTD;
reader.ValidationEventHandler += new ValidationEventHandler(HandleValidationError);
StringBuilder pickList = new StringBuilder( );
pickList.Append("Angus Hardware PickList\n");
pickList.Append("=======================\n\n");
while (reader.Read( )) {
if (reader.NodeType == XmlNodeType.Element) {
switch (reader.LocalName) {
case "po":
pickList.Append(POElementToString(reader));
break;
case "date":
pickList.Append(DateElementToString(reader));
break;
case "address":
reader.MoveToAttribute("type");
if (reader.Value == "shipping") {
pickList.Append(AddressElementToString(reader));
} else {
reader.Skip( );
}
break;
case "items":
pickList.Append(ItemsElementToString(reader));
break;
}
}
}
Console.WriteLine(pickList);
}
private static string POElementToString(XmlReader reader) {
string id = reader.GetAttribute("id");
StringBuilder poBlock = new StringBuilder( );
poBlock.Append("PO Number: ").Append(id).Append("\n\n");
return poBlock.ToString( );
}
private static string DateElementToString(XmlReader reader) {
int year = XmlConvert.ToInt32(reader.GetAttribute("year"));
int month = XmlConvert.ToInt32(reader.GetAttribute("month"));
int day = XmlConvert.ToInt32(reader.GetAttribute("day"));
DateTime date = new DateTime(year,month,day);
StringBuilder dateBlock = new StringBuilder( );
dateBlock.Append("Date: ").Append(date.ToString("D")).Append("\n\n");
return dateBlock.ToString( );
}
private static string AddressElementToString(XmlReader reader) {
StringBuilder addressBlock = new StringBuilder( );
addressBlock.Append("Shipping Address:\n");
while (reader.Read( ) && (reader.NodeType == XmlNodeType.Element ||
reader.NodeType == XmlNodeType.Whitespace)) {
switch (reader.LocalName) {
case "name":
case "company":
case "street":
case "zip":
addressBlock.Append(reader.ReadString( ));
addressBlock.Append("\n");
break;
case "city":
addressBlock.Append(reader.ReadString( ));
addressBlock.Append(", ");
break;
case "state":
addressBlock.Append(reader.ReadString( ));
addressBlock.Append(" ");
break;
}
}
addressBlock.Append("\n");
return addressBlock.ToString( );
}
private static string ItemsElementToString(XmlReader reader) {
StringBuilder itemsBlock = new StringBuilder( );
itemsBlock.Append("Quantity Product Code Description\n");
itemsBlock.Append("======== ============ ===========\n");
while (reader.Read( ) && (reader.NodeType == XmlNodeType.Element ||
reader.NodeType == XmlNodeType.Whitespace)) {
switch (reader.LocalName) {
case "item":
object [ ] parms = new object [3];
parms [0] = XmlConvert.ToInt32(reader.GetAttribute("quantity"));
parms [1] = reader.GetAttribute("productCode");
parms [2] = reader.GetAttribute("description");
itemsBlock.AppendFormat(" {0,6} {1,11} {2}\n",parms);
break;
}
}
return itemsBlock.ToString( );
}
private static void HandleValidationError(object sender,ValidationEventArgs e) {
Console.WriteLine(e.Message);
}
}
2.2.3.3 XmlNodeReaderThe XmlNodeReader type is used to read an existing XmlNode from memory. For example, suppose you have an entire XML document in memory, in an XmlDocument, and you wish to deal with one of its nodes in a specialized manner. The XmlNodeReader constructor can take an XmlNode object as its argument from anywhere in an XML document or document fragment, and perform its operations relative to that node. For example, you might wish to construct an Angus Hardware XML purchase order in memory rather than reading it from disk. One reason you might choose to construct a PO in memory is if order entry is being done by an outside party in a non-XML format, and some other section of your program is taking care of converting the data into XML. The actual construction of an XmlDocument is covered in Chapter 5, but for now let's assume that you've been given a complete XmlDocument that constitutes a valid PO. To print the pick list, you need only make one small change to Example 2-4: replace the XmlTextReader constructor with XmlNodeReader, passing in an XmlNode as its argument. XmlReader reader = new XmlNodeReader(node); The rest of the program continues as before, validating the XmlNode passed in and printing the pick list to the console. The only difference is in the type of inputs the program takesin this case, the input comes directly from the XmlNode. To recap the different XmlReader subclasses: XmlTextReader is used to read an XML document from some sort of file, whether it's on a local disk or on a web server; XmlNodeReader is used to read an XML fragment from an XmlDocument that's already been loaded some other way; XmlValidatingReader is used to validate an XML document that's being read using an XmlTextReader. The subclasses of XmlReader are mostly interchangeable, with a few exceptions discussed later. |
| [ Team LiB ] |
|
