| [ Team LiB ] |
|
5.2 The .NET DOM Implementation.NET implements only Levels 1 and 2 of the Core module of DOM. As such, the core DOM functionality is provided: standard node types and the object tree view of a document. .NET also provides some features specified in other modules that are not yet part of an official DOM level (such as loading and saving of a document, and document traversal via XPath). If these modules become official W3C Recommendations, it is expected that future .NET implementations will support them. Example 5-1 lists a program you can run to demonstrate which features the .NET Framework's DOM implementation supports. Example 5-1. A program to report DOM module supportusing System;
using System.Xml;
class DomFeatureChecker {
private static readonly string [ ] versions = new string [ ] {
"1.0", "2.0" };
private static readonly string [ ] features = new string [ ] {
"Core", "XML", "HTML", "Views", "Stylesheets", "CSS",
"CSS2", "Events", "UIEvents", "MouseEvents", "MutationEvents",
"HTMLEvents", "Range", "Traversal" };
public static void Main(string[ ] args) {
XmlImplementation impl = new XmlImplementation( );
foreach (string version in versions) {
foreach (string feature in features) {
Console.WriteLine("{0} {1}={2}", feature, version,
impl.HasFeature(feature, null));
}
}
}
}
The HasFeature( ) method of the XmlImplementation class returns true if the given feature is implemented. If you run this program with the .NET Framework version 1.0 or 1.1, you'll see the following output: Core 1.0=False XML 1.0=True HTML 1.0=False Views 1.0=False Stylesheets 1.0=False CSS 1.0=False CSS2 1.0=False Events 1.0=False UIEvents 1.0=False MouseEvents 1.0=False MutationEvents 1.0=False HTMLEvents 1.0=False Range 1.0=False Traversal 1.0=False Core 2.0=False XML 2.0=True HTML 2.0=False Views 2.0=False Stylesheets 2.0=False CSS 2.0=False CSS2 2.0=False Events 2.0=False UIEvents 2.0=False MouseEvents 2.0=False MutationEvents 2.0=False HTMLEvents 2.0=False Range 2.0=False Traversal 2.0=False Although a particular DOM module may not be supported by the .NET Framework, that should not indicate that the functionality provided by that module is not available. All it actually means is that the standard way of providing the functionality is not implemented. In fact, in many cases, the standard is not defined yet, so it's not possible for any DOM implementation to support all of the modules! The best place to start exploring the .NET DOM implementation is with the XmlImplementation type. 5.2.1 The XmlImplementationXmlImplementation implements the DOMImplementation interface specification. The DOMImplementation is used as a place to keep certain methods that have no other logical home. Because the DOM is specified using IDL, there is no way to specify a constructor. Instead, you are expected to create a new DOM Document by calling DOMImplementation.createDocument( ). In .NET, you can do this by either calling XmlImplementation.CreateDocument( ) or by using the XmlDocument constructor.
DOMImplementation also requires a createDocumentType( ) method, which returns a DocumentType node. The DocumentType represents the contents of a DTD. .NET adds the method CreateDocumentType( ) to the XmlDocument class instead. Finally, DOMImplementation requires the hasFeature( ) method. This method, which I used in Example 5-1, can be used to determine what features of the DOM are available for use in a given implementation. 5.2.2 The XmlNode Type HierarchyBecause the .NET Framework provides a complete Level 2 Core implementation, the standard node inheritance tree is available. As you'll recall from Chapter 1, each node in an XML document is represented by an appropriately named class, starting with the abstract base class, XmlNode. Look at Figure 5-2 and compare the XmlNode inheritance hierarchy to the DOM Node inheritance hierarchy in Figure 5-1. You should see that every DOM type maps to exactly one .NET XmlNode subclass, although some XmlNode subclasses do not have an equivalent DOM type. Figure 5-2. XmlNode inheritance hierarchy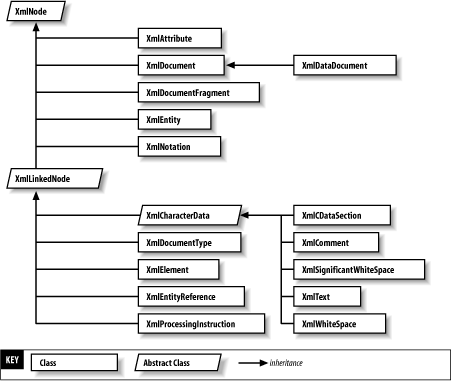 You can also see in Figure 5-2 that the .NET Framework inserts some additional levels of inheritance in the DOM hierarchy. These additional types provide a place for groupings of common functionality (XmlLinkedNode) as well as adding some functionality that is not required by the DOM specification (XmlWhitespace, XmlSignificantWhitespace). The .NET DOM implementation provides intuitive names, similar enough to the relevant DOM interface to understand without further comment. In most cases, there is a one-to-one relationship between a DOM interface and the .NET implementation; however, Table 5-1 lists the exceptions to that rule.
Another general exception is that when the DOM interface has a method named xxxNS( ), the corresponding .NET Xxx( ) method is simply overloaded to include the namespace URI parameter. The DOM interfaces are specified this way because IDL does not support overloaded methods. 5.2.3 Creating an XmlDocumentAlthough XmlNode sits at the top of the inheritance tree, XmlDocument is the top-level node in an actual document object tree. The XmlDocument has child nodes, which are accessible through the XmlNode type's various properties and methods. One of these child nodes, accessible through the DocumentElement property, is an ordinary XmlElement representing the root element of the tree. There may also be a document type node (such as <!DOCTYPE inventory SYSTEM "inventory.dtd">), represented by an XmlDocumentType, accessible through the DocumentType property. Finally, some XML documents will have an XML declaration (such as <?xml version="1.0" encoding="utf-8" standalone="no">), represented by an XmlDeclaration, and accessible only as an ordinary child node of the XmlDocument. Figure 5-3 represents a typical XML document tree structure in memory. Figure 5-3. Document tree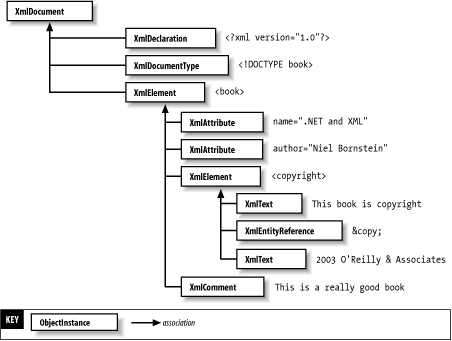 You can create an XmlDocument in memory either by calling its constructor or by calling XmlImplementation.CreateDocument( ). Both of these methods are overloaded to take an XmlNameTable, and the XmlDocument constructor is also overloaded to take an XmlImplementation.
Creating a new XmlDocument gives you an empty document. XmlDocument document = new XmlDocument( );
Now that you have a document, you're free to start adding nodes to it. As specified by the DOM, in addition to serving as a representation of the XML document, XmlDocument also acts as a factory for the creation of new nodes. The first thing you might want to do is to create the XML declaration. XmlDocument has a CreateXmlDeclaration( ) method that does just that. This method takes version, encoding, and standalone parameters. There are some constraints on the values of these parameters: the encoding parameter must be null or the name of an encoding supported by the System.Text.Encoding class; the standalone parameter must be null, "yes", or "no"; and, as of this writing, the version parameter must be "1.0". CreateXmlDeclaration( ) creates the XmlDeclaration node, but does not insert it into the tree; you must use AppendChild( ) or a similar method to actually add the node to the document: XmlDeclaration declaration = document.CreateXmlDeclaration("1.0",Encoding.UTF8.HeaderName,
null);
document.AppendChild(declaration);
Next, you might wish to specify the document type. Example 5-2 shows a DTD named inventory.dtd. Example 5-2. A DTD for warehouse inventory listings<?xml version="1.0" encoding="UTF-8"?>
<!ELEMENT inventory (date,items)>
<!ELEMENT date EMPTY>
<!ATTLIST date year CDATA #REQUIRED
month (1|2|3|4|5|6|7|8|9|10|11|12) #REQUIRED
day (1|2|3|4|5|6|7|8|9|10|11|
12|13|14|15|16|17|18|19|
20|21|22|23|24|25|26|27|
28|29|30|31) #REQUIRED>
<!ELEMENT items (item)+>
<!ELEMENT item EMPTY>
<!ATTLIST item quantity CDATA #REQUIRED
productCode CDATA #REQUIRED
description CDATA #REQUIRED
unitCost CDATA #REQUIRED>
XmlDocument has a CreateDocumentType( ) method that, predictably, creates an XML document type. This method takes a name, a system ID, a public ID, and an internal subset as parameters, the last three of which can be null. Again, you must use AppendChild( ) to add the XmlDocumentType node to the tree: XmlDocumentType docType = document.CreateDocumentType("inventory",
null,"inventory.dtd",null);
document.AppendChild(docType);
Next, you should create the document element. CreateElement( ) creates a new XmlElement but, again, does not insert it into the XML tree: XmlElement documentElement = document.CreateElement("inventory");
document.AppendChild(documentElement);
If you inspect the XmlDocument instance's DocumentElement property, you'll see that the new XmlElement has automatically become the document element because it is the first XmlElement added to the tree: XmlElement element = document.DocumentElement;
Console.WriteLine("DocumentElement is " + element.Name);
Next, continue building your XmlDocument, one element at a time. The next required element is the date: XmlElement dateElement = document.CreateElement("date");
dateElement.SetAttribute("year","2002");
dateElement.SetAttribute("month","6");
dateElement.SetAttribute("day","22");
document.DocumentElement.AppendChild(dateElement);
You'll notice that, in this case, you call AppendChild( ) on the document's DocumentElement, rather than the document itself. Besides being the right way to build a valid document for this DTD, this is necessary because a document is only allowed to have one child element. Attempting to append another child element directly to the document would cause the following exception to be thrown: System.InvalidOperationException: This document already has a DocumentElement node. Continuing, create the items and several item elements: // create the items element
XmlElement itemsElement = document.CreateElement("items");
document.DocumentElement.AppendChild(itemsElement);
// create some item elements
XmlElement itemElement = document.CreateElement("item");
itemElement.SetAttribute("quantity","15");
itemElement.SetAttribute("productCode","R-273");
itemElement.SetAttribute("description","14.4 Volt Cordless Drill");
itemsElement.AppendChild(itemElement);
itemElement = document.CreateElement("item");
itemElement.SetAttribute("quantity","23");
itemElement.SetAttribute("productCode","1632S");
itemElement.SetAttribute("description","12 Piece Drill Bit Set");
itemsElement.AppendChild(itemElement);
By now, you should see that you've built the following XML document: <?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE inventory SYSTEM "inventory.dtd">
<inventory>
<date year="2002" month="6" day="22" />
<items>
<item quantity="1" productCode="R-273" description="14.4 Volt Cordless Drill" />
<item quantity="1" productCode="1632S" description="12 Piece Drill Bit Set" />
</items>
</inventory>
That looks fairly good, but is it valid? You can check with the XmlValidatingReader from Chapter 2. Remember that one of the XmlValidatingReader type's constructors takes a Stream. You can write the XmlDocument to a MemoryStream, flush the Stream to ensure that all the data has been written, set the Stream instance's pointer back to the beginning, and then pass it to the XmlValidatingReader. You can either let the XmlSchemaException be thrown and handle it in a try...catch, or register a ValidationEventHandler as I did in Chapter 2. In this case I'll just let the default InternalValidationCallback do the work: Stream stream = new MemoryStream( );
XmlTextWriter textWriter = new XmlTextWriter(new StreamWriter(stream));
document.WriteTo(textWriter);
textWriter.Flush( );
stream.Seek(0,SeekOrigin.Begin);
XmlReader textReader = new XmlTextReader(stream);
XmlReader reader = new XmlValidatingReader(textReader);
try {
while (reader.Read( )) {
// Validation only happens when you call Read( )
}
} catch (XmlSchemaException e) {
Console.WriteLine(e);
} finally {
stream.Close( );
}
Now you can run the program and the XmlValidatingReader will tell you if you've forgotten anything: System.Xml.Schema.XmlSchemaException: The required attribute 'unitCost' is missing. An error occurred at (1, 140). at System.Xml.XmlValidatingReader.InternalValidationCallback(Object sender, ValidationEventArgs e) at System.Xml.Schema.Validator.SendValidationEvent(XmlSchemaException e, XmlSeverityType severity) at System.Xml.Schema.Validator.BeginChildren( ) at System.Xml.Schema.Validator.ProcessElement( ) at System.Xml.Schema.Validator.Validate( ) at System.Xml.Schema.Validator.Validate(ValidationType valType) at System.Xml.XmlValidatingReader.ReadWithCollectTextToken( ) at System.Xml.XmlValidatingReader.Read( ) at CreateInventory.Main(String[ ] args) in C:\Chapter 5\CreateInventory.cs:line 85 This exception indicates that an attribute required by the DTD is missing. You can go back and add the missing unitCost attributes to their respective elements. Because the DOM allows non-sequential access to the XML tree, you can actually go back to nodes that you created early in the program and assign the cost to each item at the end. This might be necessary in real life if the data were coming from disparate sourcesmaybe the list of items comes from a database, while the cost comes from a flat file; you don't want to have to scan the entire file as each row is read from the database. Since you still have the items element in memory, you can simply iterate through its child nodes, looking up the productCode attribute, and adding the unitCost attribute with the appropriate value. If the code encounters an unknown productCode, it will throw an ApplicationException: XmlNodeList elements = itemsElement.ChildNodes;
foreach (XmlElement currentElement in elements) {
double cost = 0d;
string productCode = currentElement.GetAttribute("productCode");
switch (productCode) {
case "R-273":
cost = 189.95;
break;
case "1632S":
cost = 14.95;
break;
default:
throw new ApplicationException("Unknown productCode: "
+ productCode);
}
currentElement.SetAttribute("unitCost",cost.ToString( ));
}
There are other ways you could navigate through the items element's child nodes. For example, if there were other types of child nodes besides elements, or other elements besides item, you could replace the first line of code with the following: XmlNodeList elements = itemsElement.GetElementsByTagName("item");
Either way, you now have valid XML: <?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE inventory SYSTEM "inventory.dtd">
<inventory>
<date year="2002" month="6" day="22" />
<items>
<item quantity="15" productCode="R-273" description="14.4 Volt Cordless Drill" unitCost="189.95" />
<item quantity="23" productCode="1632S" description="12 Piece Drill Bit Set" unitCost="14.95" />
</items>
</inventory>
Finally, you should save the document to a file: document.Save("inventory.xml");
The XmlDocument.Save( ) method has several overloads. The one used here takes a filename, creates all necessary FileInfo and/or XmlWriter instances, and serializes the document to the file. Other overloads take a Stream, a TextWriter, or an XmlWriter, respectively, so you can save the document not only to a variety of destinations, but even to alternative XML syntaxes, using, for example, the XmlPyxWriter I showed you in Chapter 4. 5.2.4 Reading an XmlDocumentAn XmlDocument can easily be loaded from disk using the Load( ) method. It has overloads for a Stream, filename, TextReader, or XmlReader, and the LoadXml( ) method will load an XML string from memory. This provides great flexibility; you can load an XmlDocument from a file, a web site, standard input, a memory buffer, or any subclass of Stream or TextReader, as well as any subclass of XmlReader. For example, suppose the inventory file were stored on a web server, at http://www.angushardware.com/inventory.xml. The following code would let you read it: XmlDocument document = new XmlDocument( );
document.Load("http://www.angushardware.com/inventory.xml");
After reading the entire document into memory, you now have non-sequential access to the entire XML tree. For example, you could easily navigate down to the number of each item in stock using the XmlNode type's SelectNodes( ) method. SelectNodes( ) returns an XmlNodeList based on an XPath expression; in this case, you're selecting all nodes that match the expression //items/item, and writing them to the console: XmlDocument document = new XmlDocument( );
document.Load("http://www.angushardware.com/inventory.xml");
XmlNodeList items = document.SelectNodes("//items/item");
foreach (XmlElement item in items) {
Console.WriteLine("{0} units of product code {1} in stock",
item.GetAttribute("quantity"),
item.GetAttribute("productCode"));
}
Although you don't necessarily know in what order the items will appear in the inventory file, you might want to print out the inventory in some reasonable order, such as by product code. While an XML Schema can alert you if elements in an XML document are in the wrong order, it can't ensure that elements are ordered by an attribute value. To do this, you can create a private inner class called UnitInventory to hold a single product type's inventory information. This class will implement the IComparable interface to permit easy sorting, and you can override ToString( ) to use the same object to print the inventory: private class UnitInventory : IComparable {
private string productCode;
private int quantity;
private string description;
private double unitCost;
public UnitInventory(string productCode, string quantity,
string description, string unitCost) {
this.productCode = productCode;
this.quantity = Int32.Parse(quantity);
this.description = description;
this.unitCost = Double.Parse(unitCost);
}
public int CompareTo(object other) {
UnitInventory otherInventory = (UnitInventory)other;
return productCode.CompareTo(otherInventory.productCode);
}
public override string ToString( ) {
return quantity + " units of product code " +
productCode + ", '" + description +
"', in stock at $" + unitCost;
}
}
Now you can create an instance of UnitInventory for each row returned by SelectNodes( ), add each to an ArrayList and sort the list, and, finally, write each item to the console: XmlDocument document = new XmlDocument( );
document.Load("http://www.angushardware.com/inventory.xml");
XmlNodeList items = document.SelectNodes("//items/item");
ArrayList list = new ArrayList(items.Count);
foreach (XmlElement item in items) {
list.Add(new UnitInventory(item.GetAttribute("productCode"),
item.GetAttribute("quantity"),
item.GetAttribute("description"),
item.GetAttribute("unitCost")));
}
list.Sort( );
foreach (UnitInventory inventory in list) {
Console.WriteLine(inventory);
}
If you run the program, you'll see the list of inventory items sorted by the productCode attribute: 23 units of product code 1632S, '12 Piece Drill Bit Set', in stock at $14.95 15 units of product code R-273, '14.4 Volt Cordless Drill', in stock at $189.95 5.2.5 Changing an XmlDocumentIn the previous example, you didn't actually change the underlying document. In fact, there's nothing there that you couldn't have done with an XmlReader. Unlike an XmlReader, however, the DOM allows you to change an existing XML document. Suppose you decided to stop validating the inventory records. In order to make this change, you would need to remove the DOCTYPE node from all of the XML files. How would you go about doing this? The short answer is XmlNode.RemoveChild( ). This method removes the node passed in from the object tree. You can read in all the XML files in the current directory, and remove the XmlDocumentType node. Then you can serialize the file back out (with the extension .new so you don't overwrite the original) and check that the DOCTYPE node is gone: string currentDirectory = Environment.CurrentDirectory;
string [ ] files = Directory.GetFiles(currentDirectory, "*.xml");
foreach (string file in files) {
XmlDocument document = new XmlDocument( );
document.Load(file);
XmlDocumentType documentType = document.DocumentType;
document.RemoveChild(documentType);
document.Save(file + ".new");
}
This process can be repeated with any type of XmlNode. For example, you could remove the inventory element, leaving an empty document, except for the XML declaration. Or you could use RemoveAll( ) to remove everything in the document entirely, while leaving the empty file in place: document.Load(file); document.RemoveAll( );
A more common case, given our example, would be to change the quantity of a particular item in stock. If you look back at the purchase order DTD from Chapter 2, you can see that the item elements are identical. You could write a small program to read in the store inventory and a purchase order, and decrement the inventory by the number of items sold in the PO. Let's build the program, starting with a class called SellItems. To begin, because you're dealing with the same inventory file for all of the purchase orders, you can just store it as an instance variable: private XmlDocument inventory; In the Main( ) method, all you need do is instantiate a new SellItems object, passing the list of purchase order files that appeared on the command line: static void Main(string [ ] args) {
new SellItems(args);
}
The constructor creates the inventory XmlDocument and loads it from a file: private SellItems(string [ ] files) {
inventory = new XmlDocument( );
inventory.Load("inventory.xml");
Next, loop through the purchase order file names, calling SellItemsFromPoFile( ) for each one: foreach (string filename in files) {
SellItemsFromPoFile(filename);
}
Finally, save the inventory document with all changes: inventory.Save("inventory.xml");
}
The SellItemsFromPoFile( ) method will create and load an individual purchase order from the list. For efficiency, each purchase order XmlDocument shares the same XmlNameTable with the others, and with the inventory XmlDocument: private void SellItemsFromPoFile(string filename) {
XmlDocument po = new XmlDocument(inventory.NameTable);
po.Load(filename);
This XPath expression selects each item element from the purchase order: XmlNodeList elements = po.SelectNodes("//items/item");
This loop calls SellItemsFromElement( ) for each item element that the XPath expression returned: foreach (XmlElement element in elements) {
SellItemsFromElement(element);
}
}
Next is SellItemsFromElement( ) itself, the method that actually decrements the inventory. First, you get the product code and the quantity sold from the purchase order's item element: private void SellItemsFromElement(XmlElement poItem) {
string productCode = poItem.GetAttribute("productCode");
int quantitySold = Int32.Parse(
poItem.GetAttribute("quantity"));
Now, you search for the same product code in the inventory's item elements. Again, XPath is discussed in the next chapter; for now, don't worry too much about the XPath syntax: string xPathExpression =
"//items/item[@productCode='" + productCode + "']";
XmlElement inventoryItem =
(XmlElement)inventory.SelectSingleNode(xPathExpression);
Here you're getting the quantity attribute from the inventory document, subtracting from it the amount in the purchase order document, and setting the inventory document's quantity attribute to the new decremented amount: int quantity = Int32.Parse(inventoryItem.GetAttribute("quantity"));
quantity -= quantitySold;
inventoryItem.SetAttribute("quantity", quantity.ToString( ));
}
And that's it, a simple inventory maintenance program. Granted, it's not a good idea to keep your inventory in a flat XML file; but if you think of the various ways you can construct an XmlDocument, you could actually be reading XML from a relational database, or some sort of web service, or almost anything you can imagine. Example 5-3 shows the complete program. Example 5-3. A program to update inventoryusing System;
using System.Xml;
public class SellItems {
private XmlDocument inventory;
static void Main(string [ ] args) {
new SellItems(args);
}
private SellItems(string [ ] files) {
XmlDocument inventory = new XmlDocument( );
inventory.Load("inventory.xml");
foreach (string filename in files) {
SellItemsFromPoFile(filename);
}
inventory.Save("inventory.xml ");
}
private void SellItemsFromPoFile(string filename) {
XmlDocument po = new XmlDocument(inventory.NameTable);
po.Load(filename);
XmlNodeList elements = po.SelectNodes("//items/item");
foreach (XmlElement element in elements) {
SellItemsFromElement(element);
}
}
private void SellItemsFromElement(XmlElement poItem) {
string productCode = poItem.GetAttribute("productCode");
int quantitySold = Int32.Parse(
poItem.GetAttribute("quantity"));
string xPathExpression =
"//items/item[@productCode='" + productCode + "']";
XmlElement inventoryItem =
(XmlElement)inventory.SelectSingleNode(xPathExpression);
int quantity = Int32.Parse(inventoryItem.GetAttribute("quantity"));
quantity -= quantitySold;
inventoryItemElement.SetAttribute("quantity", quantity.ToString( ));
}
}
|
| [ Team LiB ] |
|
