| [ Team LiB ] |
|
9.3 ExamplesHaving considered the 10 steps, let's take another brief look at the 3 examples from the previous chapter and see what they will need in terms of sites. 9.3.1 TwoSiteCorpTwoSiteCorp has two locations split by a 128 Kbps link. This means creation of two sites separated by a single site link, with DCs for domain authentication in each site. The site link cost is not an issue, as only one route exists between the two sites. Here the only issue is scheduling the replication, which depends on the existing traffic levels of the link. Schedule replication during the least busy times for a slow link like this. If replication has to take place all the time, as changes need to be propagated rapidly, it is time to consider increasing the capacity of the link. 9.3.2 RetailCorpRetailCorp has a large centralized retail organization with 600 shops connected via 64 Kbps links to a large centralized 10/100 Mbps interconnected headquarters in London. In this situation, you have one site for HQ and 600 sites for the stores. RetailCorp also uses a DC in each store. They then have to create 600 high-cost site links, each with the same cost. RetailCorp decides this is one very good reason to use ADSI (discussed in Part III) and writes a script to automate the creation of the site link objects in the configuration. The only aspect of the site links that is important here is the schedule. Can central HQ cope with all of the servers replicating intersite at the same time? Does the replication have to be staggered? The decision is made that all data has to be replicated during the times that the stores are closed; for stores that do not close, data is replicated during the least busy times. There is no need to worry about site link bridges or site link transitiveness as all links go through the central hub, and no stores need to intercommunicate. The administrators decide to let the KCC pick the bridgehead servers automatically. 9.3.3 PetroCorpPetroCorp has 94 outlying branch offices. These branch offices are connected via 64 Kbps links to 5 central hub sites. These 5 hubs are connected to the central organization's HQ in Denver via T2, T1, 256 Kbps, and 128 Kbps links. Some of the hubs also are interconnected. To make it easier to understand, look at PetroCorp's network again (Figure 9-8). Figure 9-8. PetroCorp's network connections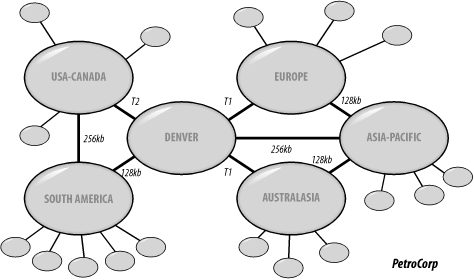 Initially, you need to create 100 sites representing HQ, the hubs, and the branch offices. How many servers do you need per site? From the design we made in Chapter 8, we decided on 9 domains in the forest. Each of those distinct domains must obviously have a server within it that forms part of the single forest. However, although the description doesn't say so, there is very little cross-pollination of clients from one hub needing to log on to servers from another hub. As this is the case, there is no need to put a server for every domain in every hub. If a user from Denver travels to the asiapac.petrocorp.com domain, the user can still log on to petrocorp.com from the Asia-Pacific hub, albeit much more slowly. PetroCorp sees that what little cross-pollination traffic it has is made up of two types of user:
While the senior managers' use is infrequent, these key decision makers need to log on as rapidly as possible to access email and their data. Money is found to ultimately place petrocorp.com servers for authentication purposes in each of the five hubs. The second requirement means that servers for each domain need to be added to the alternate hub. Due to this limitation, only enough money is found to support petrocorp.com from outside its own Denver location and the Europe/Australasia hubs hosting each other's domains (see Figure 9-9). Figure 9-9. PetroCorp's sites and servers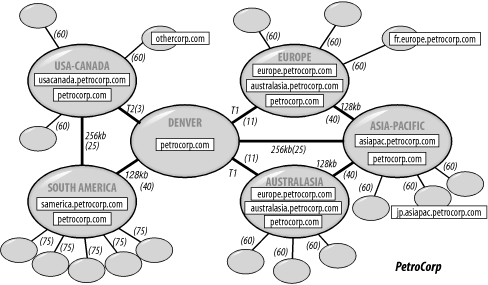 While domains normally are represented by triangles in diagrams, here the rectangular borders around a domain name represent servers that host that domain. Each domain is hosted by multiple servers represented by a single rectangle, although you could run this structure using only one server per rectangle. You can see that petrocorp.com is hosted in Denver, as well as in all other hubs. Regarding intrasite KCC topology generation: PetroCorp has decided to let the KCC automatically generate intradomain server links. If this causes a problem, local administrators should be able to handle it. The site links are depicted in Figure 9-9 with parentheses to indicate the costs. They can also be described as follows:
What about the branches? All links are stable except the links between the eight South America branches and the hub, which are very unreliable. In this case, you have two choices: you can either let the clients in those eight sites authenticate across the less-than-reliable links, or you can place servers in those branches so that authentication is always possible, even when the link is down. PetroCorp opts for the latter and places servers in each of the eight branches. However, DS-RPC is not the best replication mechanism for asynchronous links like these, so PetroCorp instead creates digital certificates and rolls out a certificate server to those sites to enable the replication mechanism to use the underlying mail transport via an SMTP connector for each link. That changes the list to include the following site links:
PetroCorp's administrators then sit back and decide that they are going to create some redundant site links of the same cost so that if a single bridgehead server is lost in any of the major hubs, replication can still continue. Each hub has enough DCs to cope with this, so they add the redundant links. While Steps 6, 7, and 8 have been completed, we have, however, appeared to skip Steps 4 and 5. Step 5 was left until now on purpose, since the administrators wanted to wait until the site links were designed to see whether site link transitiveness should be turned on or off and whether bridging routes might help. Now you can easily see that transitivity is important between the Europe and Australasia hubs. If you don't turn transitiveness on by default, you need to create a site link bridge in Denver that allows the europe.petrocorp.com and australasia.petrocorp.com domains to replicate across the two T1 links even though they have no direct links. Now look at the diagram again, and consider that transitiveness is turned on. This means any site can use any connection to any other site based on the lowest cost. So if you leave site link transitiveness on and let the KCC create the intersite connection objects and bridgehead servers, replication traffic between Denver and South America is likely to route through USA-Canada, as the total cost across those two links (28) is lower than the direct link (40). This also is true for Asia-Pacific to either Europe (40) or Australasia (40). All traffic is likely to route through Denver (36) because of that. All this means is that the slow 128 Kbps links will not have their bandwidth used up by replication; instead, the 256 Kbps links will absorb the overflow. In the eastern link you have potentially added two lots of bidirectional replication traffic across the 256 Kbps link. Whether this is a problem is up to PetroCorp to decide. They have four main choices:
Which of these is chosen depends entirely on the traffic use of the links, the requirements on those links, and how much use the administrators wish to make of the KCC. PetroCorp decides that it wants the KCC to make most of the connections but still wants to retain the greatest control and the potential to force the KCC to use certain routes. To that end, they select the second option. In the end, the company chooses to bridge South America to Denver via USA-Canada to free up the 128 Kbps link for other traffic. They also choose to bridge Europe to Asia-Pacific via Denver to free up what is currently a congested link. The KCC automatically routes all traffic via Denver, as this bridge cost is lower than the single site link. Finally, the administrators allow the KCC in the Denver site to generate the eight intersite site links (four connections, each with two site links for redundancy) and then turn off intersite generation for that site. They then modify the connection objects created (deleting some and creating others), because they have a number of DCs that they do not want to use for replication purposes within Denver that the KCC picked up and used. This is a fairly complicated site problem, but one that wasn't difficult to solve. There are many other viable solutions. We could easily have made all the redundant links that we created use the SMTP connector with a higher cost to make sure that they were used only in an emergency. Many options are available to you as well. That's why a design is so important. |
| [ Team LiB ] |
|